当前位置:网站首页>NLP natural language processing - Introduction to machine learning and natural language processing (3)
NLP natural language processing - Introduction to machine learning and natural language processing (3)
2022-07-26 07:25:00 【Emperor Confucianism is supreme】
NLP natural language processing - Introduction to machine learning and natural language processing - New word discovery and TF-IDF
1. The discovery of new words
(1) Why should we do new word discovery
① If there is no vocabulary , How do we find words ;
② As the amount of data increases , The old vocabulary will gradually fail to meet the subsequent needs ;
③ The supplementary vocabulary is helpful to the realization of downstream tasks .
④ Words are equivalent to a fixed collocation , The inside of the word is stable , Also called internal solidity 
; And the outside of the word is unstable , It is called left and right entropy 
.
Such as below : The word Hebei is stable , But the one behind is not fixed .
(2) What is an important word
① When we segment the text , Need to use words to understand the document , Then what we need is the important words in the document ; as follows :
② If a word is in a certain kind of text ( Assuming that A class ) There are many times in , And in other categories of text ( Not A class ) There are few , Then the word is A Important words of text like ( High weight words ).
conversely , If a word appears in many fields , Then its importance to any category is very poor .
③ Use mathematics to describe the importance of a word , namely NLP Medium TF-IDF:TF Word frequency , That is, the number of times a word appears in a category / The total number of words in this category ;IDF Reverse document frequency , Reverse document frequency is high -> The word rarely appears in other documents 
.
Calculation method : Each word will get one for each category TF·IDF value ,TF·IDF high -> The word is highly important in this field .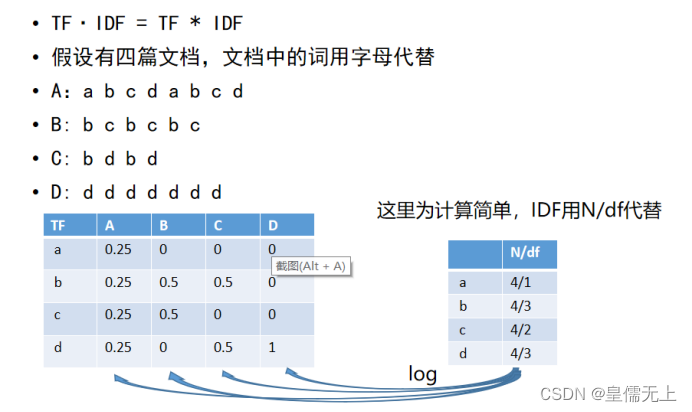
2. TD-IDF Characteristics of the algorithm
(1)tf-idf The calculation of depends very much on the result of word segmentation , If the word segmentation is wrong , The significance of statistical value will be greatly reduced ;
(2) Every word , For each document , Different tf-idf value , So we can't leave the data discussion tfidf;
(3) If there is only one text , Can't calculate tf-idf;
(4) Category data balance is important ;
(5) Susceptible to various special symbols , It's best to do some pretreatment .
3. TD-IDF Application of algorithm
(1)TF-IDF application - Search engine
① For all existing web pages ( Text ), Calculate , Lexical TFIDF value ;
② For an input query Carry out word segmentation ;
③ For documents D, Calculation query The words in the document D Medium TFIDF Sum of values , As query Score of relevance to documents .
(2)TF-IDF application - Text in this paper,
① By calculation TFIDF Worth every text keyword ;
② Sentences that contain many keywords , Think it is a key sentence ;
③ Choose some key sentences , As a summary of the text .
(3)TF-IDF application - Text similarity calculation
Calculate for all text tfidf after , Select from each text tfidf Higher front n Word , Get a set of words S. For each text D, Calculation S The word frequency of each word in , Take it as a vector of text . By calculating the cosine of the angle between vectors , Get the vector similarity , As the similarity of text .
Calculation of cosine value of vector angle :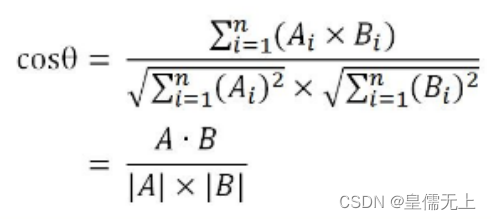
4. TF-IDF The advantages of
① Good explainability : You can clearly see the keywords , Even if the prediction results are wrong , It's also easy to find the reason ;
② Fast calculation : Word segmentation itself takes up the most time , The rest are simple statistical calculations ;
③ Little dependence on annotation data : You can use unmarked corpus to complete part of the work ;
④ It can be combined with many algorithms : It can be seen as word weight .
5. TF-IDF The disadvantages of
① Greatly affected by the effect of word segmentation ;
② There is no semantic similarity between words ( This problem is fatal );
③ No word order information ( The word bag model );
④ Limited capacity , Unable to complete complex tasks , Such as machine translation and entity mining ;
⑤ Sample imbalance will have a great impact on the results ;
⑥ The distribution between samples within a class is not considered .
边栏推荐
- 【推荐系统经典论文(十)】阿里SDM模型
- It's another summer of open source. 12000 project bonuses are waiting for you!
- Opencv learning basic functions
- NFT digital collection system development: digital collections give new vitality to brands
- 4. Data integrity
- 深度学习模型部署
- Lite actor: lightweight optimization of ark actor concurrency model
- NFT数字藏品系统开发:激活数字文化遗产
- 单身杯web wp
- 6、组合数据类型
猜你喜欢

DADNN: Multi-Scene CTR Prediction via Domain-Aware Deep Neural Network
【推荐系统经典论文(十)】阿里SDM模型
从Boosting谈到LamdaMART

NFT digital collection system development: Huawei releases the first collector's digital collection

PR subtitle production
College degree sales career, from the third tier 4K to the first tier 20k+, I am very satisfied with myself
dcn(deep cross network)三部曲

数据平台调度升级改造 | 从Azkaban 平滑过度到 Apache DolphinScheduler 的操作实践
![[C language] do you really know printf? (printf is typically error prone, and collection is strongly recommended)](/img/59/cf43b7dd16c203b4f31c1591615955.jpg)
[C language] do you really know printf? (printf is typically error prone, and collection is strongly recommended)
NLP自然语言处理-机器学习和自然语言处理介绍(三)
随机推荐
Opencv learning drawing shapes and text
从Boosting谈到LamdaMART
0动态规划 LeetCode1567. 乘积为正数的最长子数组长度
Comparison and difference between dependence and Association
机器学习相关比赛网站
Lite actor: lightweight optimization of ark actor concurrency model
「论文笔记」Next-item Recommendations in Short Sessions
Opencv learn read images videos and webcams
Unity3d asynchronous loading of scenes and progress bar loading
达人专栏 | 还不会用 Apache Dolphinscheduler?大佬用时一个月写出的最全入门教程【三】
In July, glassnode data showed that the open position of eth perpetual futures contract on deribit had just reached a one month high of $237959827.
Talent column | can't use Apache dolphin scheduler? The most complete introductory tutorial written by the boss in one month [3]
What is bloom filter in redis series?
此章节用于补充
NFT digital collection system development: digital collections give new vitality to brands
HCIP---BGP综合实验
QT: list box, table, tree control
anaconda安装教程-手把手教你安装
Data platform scheduling upgrade and transformation | operation practice from Azkaban smooth transition to Apache dolphin scheduler
With someone else's engine, can it be imitated?