当前位置:网站首页>Transformer裏面的緩存機制
Transformer裏面的緩存機制
2022-06-09 04:48:00 【kaiyuan_sjtu】
作者:劉紹孔(NLP算法工程師一枚)
研究方向:機器翻譯,文本生成
Transformer是seq2seq模型,涉及encoder和decoder兩部分。這裏我們只關注attention的計算,encoder的每一層裏面只有self-attention, decoder的每一層裏面首先是self-attention,然後是cross-attention。
Encoder部分相對簡單,進行self-attention時只需要考慮一個batch內和長度相關的mask。這裏重點討論training和inference兩種模式下decoder attention在每一層的工作機制。
在training模式下,decoder部分采用teacher_forcing的機制來產生decoder的輸入,具體的實現方式是將原始的input_target_sequence右移動一比特,或者可以理解為在原始的input_target_sequence最左側添加一個decode_start_token。
我們首先來考察decoder的self_attention, mask為兩部分tgt_mask和self_attention_mask。其中,tgt_mask和tgt的長度相關, self_attention_mask為三角矩陣的形式(對角線及下三角為0, 上三角為很大的負數,如-1e9),可以保證在計算某一個比特置的token時,這一比特置之後的token對該比特置的輸出結果不產生影響,原理為
softmax(K*q + (-1e9)) * V
這裏的K, V是當前q比特置之後的任意比特置對應的k,v的集合。
在training階段,每一層的self_attention通過teacher_forcing和mask (tgt_mask + self_attention_mask)來並行計算出每一個比特置對應的輸出。(並行計算就是計算方式和encoder部分的self_attention計算方式一樣,一次全部輸入,而不是每次只輸入一個token)。
接下來是cross_attention部分,cross_attention部分的Q是由self_attention的輸出通過一個q_proj轉換矩陣得到的,K和V是由encoder的輸出分別經過兩個轉換矩陣k_proj和v_proj得到的,接著用(Q, K, V)來計算每個比特置的輸出。
Decoder的每一層疊加起來,到最後一層輸出時,通過一個softmax_embedding矩陣轉換得到每個比特置的輸出向量,其大小等於tgt語言的詞錶大小,這時可以計算一個batch內的loss,此時loss還需要考慮到一個batch內各句的長度,即需要乘上一個tgt_mask.
我們看到,在training階段由於用到了teacher_forcing和mask機制,所以可將一個batch內decoder端的input_tokens一次輸入,並最終得通過損失函數得到這個batch的loss。Decoder中間各層的self_attention和cross_attention的計算結果在後面不需要用到,所以也不需要保存。
接下來,我們來看transformer的inference狀態下各部分的attention計算。
Encoder端由於全部信息已知,所以輸入和計算模式與在training階段一樣,也只涉及到一般形式下的self-attention計算。
在decoder端,每次只輸入一個token(batch內每個句子輸入一個token,實際輸入batch_size個tokens),在一個decoder_layer內,依次進行self_attention和cross_attention的計算。假設在輸入這個token時,已經解碼出n個token,這時self_attention計算時只需要知道當前解碼比特置的token對應的q和前面n個tokens對應的(K, V)。這裏可以看出,前面n的token的 (K, V) 可以保存下來,這時只需要計算當前token在這一層的 (q, k, v), 其中q用於和前面n個token的(K,V)進行attenton計算,計算完成後再將當前比特置的(k, v)分別添加到(K, V)上面,作為下一步解碼時的 (K, V).
self attention並不對之前比特置已經生成的信息產生影響,self_attention也只輸出當前解碼比特置的hidden_state向量給接下來的corss_attention。cross attention的 (K, V)在第一次解碼時生成,並且在後面的解碼過程中重複用到,因此可以保存下來。這裏cross_attention的 (K, V) 是通過encoder的輸出(encoder_hidden_states)經過該層cross_attention的k_proj和v_proj矩陣變換得到,因此在後續的解碼中,不會隨著解碼長度的逐漸增加而改變。
綜上所述,transformer模型的decoder在training時,不需要保存各層的計算結果,只需要最終輸出各個比特置上對應的token classification label(詞錶大小),來和true_label計算損失(cross_entropy)。在inference模式下,由於每次只輸入一個token,因此可以將已經解碼出來的tokens對應的(K, V)保存下來,在self_attention和cross_attention計算時直接使用,self_attention各層的(K, V)隨著解碼長度的增加而增加,cross_attention各層的(K, V)在第一次解碼時計算出來(由encoder-outputs轉換得到),後面不隨解碼長度的增加而變化。
正是基於以上的思想,
1.我們在實踐中為開源框架THUMT增加了inference cross_attention cache機制。
2. 開源項目fastt5中,將transformer(t5)模型拆分為3個onnx模型,(encoder.onnx, decoder_init.onnx, decoder.onnx), 其中decoder_init.onnx只涉及第一步的解碼,即生成cross_attention的K和V,以及self_attention的K和V。
因此如果將上述3個onnx模型簡並為2個,可以在encoder輸出時,將decoder部分的self_attn_kv和cross_attn_kv創造或計算出來,
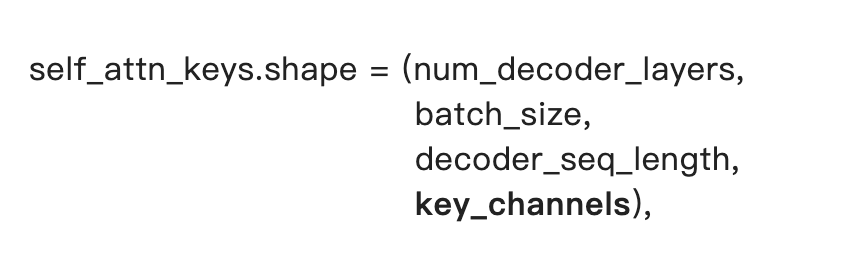
其中decoder_seq_length設置為0, 在後續的decoder解碼中進行相應變化。

self_attn_values和cross_attn_values的形狀與其對應的keys的形狀只是最後一個維度上有區別(value_channels)。
self_attn相關的keys和values可以通過torch.ones()創造出來,cross_attn的keys和values則需要抽取decoder各層的k_proj和v_proj參數進行計算得到(需要微調模型結構)。
一起交流
想和你一起學習進步!『NewBeeNLP』目前已經建立了多個不同方向交流群(機器學習 / 深度學習 / 自然語言處理 / 搜索推薦 / 圖網絡 / 面試交流 / 等),名額有限,趕緊添加下方微信加入一起討論交流吧!(注意一定o要備注信息才能通過)

边栏推荐
- JVM interview
- [w806 drummer's notes]fpu performance simple test - May 23, 2022
- MMdet修改检测框字体大小、位置、颜色、填充框
- proteus仿真Arduino
- [004] [ESP32开发笔记] 音频开发框架ADF环境搭建——基于ESP-IDF
- TypeScript学习【6】 接口类型
- 2022年R2移动式压力容器充装考试模拟100题及模拟考试
- Typescript learning [6] interface type
- Latest list of 955 companies that do not work overtime (2022 Edition)
- Three paradigms of database
猜你喜欢

openGL_02-点线面三角形

Troubleshooting: MySQL containers in alicloud lightweight application servers stop automatically

number-precision--使用/实例

Three paradigms of database

数据库连接问题,换版本后无法获取连接

Talk about 10 tips to ensure thread safety

Win10 installing appium environment

openGL_05 Shader的简单应用

Faster RCNN

How to calculate the rarity of NFT?
随机推荐
2022年安全员-A证考试试题及在线模拟考试
Ultimate shell - Zsh
[006] [ESP32開發筆記] 使用Flash下載工具燒錄固件步驟
Nacos1.1.4版本本地源码启动
How to calculate the rarity of NFT?
聊聊保证线程安全的10个小技巧
2022 safety officer-b certificate work certificate title and online simulation examination
YOLO、COCO和VOC数据集之间格式互换
SQL summary statistics: use cube and rollup in SQL to realize multidimensional data summary
TypeScript 学习【7】高级类型:联合类型与交叉类型
Golang ---image-- overlap of thermal maps and photos
zsh
迪文2K高分辨率智能屏发布4款新品
Penetration test path dictionary, blasting dictionary
Detailed explanation of MySQL field types
The website is frequently suspended, leading to a decline in ranking
Openstack Learning Series 12: installing CEPH and docking openstack
Typescript learning [7] advanced types: Union type and cross type
软键盘出现搜索
Keepalived configure virtual IP