当前位置:网站首页>Pyramid Scene Parsing Network【PSPNet】论文阅读
Pyramid Scene Parsing Network【PSPNet】论文阅读
2022-07-01 03:15:00 【是七叔呀】
论文:https://arxiv.org/pdf/1612.01105.pdf
Caffe Code:https://github.com/hszhao/PSPNet
有pytorch代码的知乎链接:https://zhuanlan.zhihu.com/p/115004020
理解篇:PSPNet模型学习笔记
Abstract
场景解析对于不受限制的开放词汇和多样的场景来说是一项挑战。在本文中,我们通过我们的金字塔池化模块和提出的金字塔场景解析网络(PSPNet),通过基于不同区域的上下文聚合来探索利用全局上下文信息的能力。我们的全局先验表示可以有效地在场景解析任务中产生高质量的结果,而PSPNet为像素级预测提供了一个优越的框架。所提出的方法在各种数据集上实现了最先进的性能。它在2016 ImageNet场景解析挑战赛、PASCAL VOC 2012基准测试和Cityscapes基准测试中名列第一。单台PSPNet可创造mIoU精度85的新纪录。PASCAL VOC 2012的4%,准确度80。城市景观2%。
1. Introduction
基于语义分割的场景解析是计算机视觉中的一个基本课题。目标是为图像中的每个像素指定一个类别标签。场景解析提供了对场景的完整理解。它预测每个元素的标签、位置以及形状。这个主题对于自动驾驶、机器人传感等潜在应用具有广泛的兴趣。
场景解析的难度与场景和标签的多样性密切相关。先锋(pioneer)场景解析任务【23】是对LMO数据集上2688幅图像的33个场景进行分类【22】。最近的PASCAL VOC语义分割和PASCAL上下文数据集【8,29】包括更多具有类似上下文的标签,如椅子和沙发、马和牛等。新的ADE20K数据集【43】是最具挑战性的数据集,具有大量且不受限制的开放词汇表(unrestricted open vocabulary)和更多场景类别。图1中显示了一些代表性图像。为这些数据集开发有效的算法需要克服一些困难。
最先进(sota)的场景解析框架大多基于完全卷积网络(FCN)[26]。基于深度卷积神经网络(CNN)的方法提高了对动态对象的理解(boost dynamic object understanding),但仍然面临考虑到不同的场景和不受限制的词汇的挑战。图2的第一行显示了一个示例,其中船被误认为是汽车。这些错误是由于对象的外观相似造成的。但是,当根据场景描述为河流附近的船库之前的上下文先验(the context prior)查看图像时,应该就能做出正确的预测。
为了获得准确的场景感知,知识图依赖于场景上下文的先验信息。我们发现,当前基于FCN的模型的主要问题是缺乏合适的策略来利用全局场景类别线索。对于典型的复杂场景理解,以前为了获得全局图像级(level)特征,空间金字塔池化(spatial pyramid pooling)被广泛采用,其中空间统计为整体场景解释提供了一个良好的描述。空间金字塔池化网络(Spatial pyramid pooling network )[12]进一步增强了这种能力。
与这些方法不同,为了结合合适的全局特征,我们提出了金字塔场景解析网络pyramid scene parsing network(PSPNet)。除了用于像素预测的传统扩展FCN(3,40)外,我们还将像素级特征扩展到专门设计的全局金字塔池化特征。局部和全局线索一起使最终预测更加可靠。我们还提出了一种带有深度监督损失的优化策略。我们给出了所有的实现细节,这些细节是我们在本文中获得良好性能的关键,并使代码和经过训练的模型可以公开使用1。
我们的方法在所有可用数据集上都实现了最先进的性能。它是2016年ImageNet场景解析挑战赛的冠军【43】,在PASCAL VOC 2012语义分割基准(PASCAL VOC 2012 semantic segmentation benchmark)测试中排名第一【8】,在城市场景城市景观数据(on urban scene Cityscapes data)中排名第一【6】。他们表明,PSPNet为像素级预测任务提供了一个有希望的方向,这甚至可能有利于后续基于CNN的工作:立体匹配、光流、深度估计等。我们的主要贡献有三个方面:
- 我们提出了一种金字塔场景解析网络,用于在基于FCN的像素预测框架中嵌入困难场景的上下文特征。
- 我们开发了一种基于深度监督损失的深度ResNet有效优化策略[13]。
- 我们构建了一个实用的系统,用于最先进的场景解析和语义分割,其中包括所有关键的实现细节。
2. Related Work
下面,我们将回顾场景解析和语义分割任务==(scene parsing and semantic segmentation tasks)的最新进展。在强大的深度神经网络[17、33、34、13]的驱动下,场景解析和语义分割等像素级预测任务取得了巨大的进展,这是因为 将 分 类 中 的 全 连 接 层 替 换 为 卷 积 层 \color{red}{将分类中的全连接层替换为卷积层} 将分类中的全连接层替换为卷积层[26]。为了扩大神经网络的感受野,[3,40]的方法使用了扩张卷积(dilated convolution)。Noh等人[30]提出了一种从粗到细的结构,用 反 卷 积 网 络 ( d e c o n v o l u t i o n n e t w o r k ) \color{red}{反卷积网络(deconvolution network)} 反卷积网络(deconvolutionnetwork)来学习分割掩模。我们的基线网络是FCN和扩张网络[26,3](Our baseline network is FCN and dilated network)。
其他工作主要从两个方向进行。其中一个方向(26、3、5、39、11)是具有多尺度特征集合。由于在深层网络中, 更 高 层 的 特 征 包 含 更 多 的 语 义 和 更 少 的 位 置 信 息 \color{red}{更高层的特征包含更多的语义和更少的位置信息} 更高层的特征包含更多的语义和更少的位置信息。结合多尺度特征可以提高性能。
另一个方向是基于结构预测。先驱网络(pioneer work)[3]使用条件随机场(conditional random field)(CRF)做后处理来修正(refine)分割结果。以下方法【25、41、1】通过端到端建模优化网络。这两个方向都改善了场景解析中预测语义边界与对象匹配的定位能力。然而,在复杂场景中仍然有很大的空间可以利用必要的信息。
为了更好地利用全局图像级别的先验知识进行不同场景的理解,[18,27]的方法使用传统特征提取全局上下文信息,而不是从深层神经网络中提取。在目标检测框架下也有类似的提升【35】。Liu等人[24]证明了FCN的全局平均池化可以改善语义分割结果。然而,我们的实验表明,这些全局描述对于具有挑战性的ADE20K数据来说并不具有足够的代表性。因此,与[24]中的全局池化不同,我们通过我们的金字塔场景解析网络,通过基于不同区域的上下文聚合来探索利用全局上下文信息。
3. Pyramid Scene Parsing Network
我们首先观察和分析了将FCN方法应用于场景解析时的典型故障案例。他们促使我们提出金字塔池化模块作为 一 个 有 效 的 全 局 上 下 文 先 验 \color{red}{一个有效的全局上下文先验} 一个有效的全局上下文先验。如图3所示的金字塔场景解析网络(PSPNet),可以提高复杂场景解析中开放词汇表对象和内容识别的性能(improve performance for open-vocabulary object and stuff identification in complex scene parsing)。
3.1 Important Observations
新的ADE20K数据集【43】包含150个物品/对象类别标签(150 stuff/object category labels )(例如,墙、天空和树)和1038个图像级场景描述(例如,机场航站楼、卧室和街道)。因此,大量的标签和大量的场景分布便应运而生。通过检查[43]中提供的FCN基线的预测结果,我们总结了复杂场景解析的几个常见问题:
Mismatched Relationship不匹配的关系:上下文语境关系是一种普遍而重要的关系,尤其是对于复杂场景的理解。存在一个共现视觉模式。例如,飞机可能在跑道上或在天空中飞行,而不是在道路上。对于图2中的第一排示例,FCN根据其外观将黄色框中的船预测为“汽车”。但众所周知,汽车很少过河。缺乏收集上下文信息的能力会增加错误分类的可能性。Confusion Categories混肴类别:ADE20K数据集中有许多分类标签对[43]在分类上令人困惑。例如电场和地球;山地和丘陵;墙、房子、建筑物和摩天大楼。它们外观相似。为整个数据集添加标签的专家标注员如【43】所述仍然制造了17.60%的像素错误。在图2的第二行中,FCN预测框中的对象是摩天大楼和建筑的一部分。应排除这些结果,以便整个对象不是摩天大楼就是建筑,而不是两者兼而有之。这个问题可以通过利用类别之间的关系来解决。Inconspicuous Classes不显眼的类别:包含任意大小尺寸对象/内容的场景。一些小尺寸的东西,如路灯和招牌,尽管它们可能很重要,但很难找到。相反,大型物体或物品可能超过了FCN的感受野,从而导致了不连续预测。如图2第三行所示,枕头的外观与床单相似。忽略全局场景类别可能无法解析枕头。为了提高针对非常小或非常大的对象的性能,应该格外注意包含不明显类别内容的不同子区域。
总结这些观察结果,许多错误部分的或完全的与不同感受野的contextual relationship 上 下 文 关 系 \color{red}{上下文关系} 上下文关系和contextual relationship 全 局 信 息 \color{red}{全局信息} 全局信息 有关。因此,具有合适全局场景级先验的深度网络可以大大提高场景解析的性能。
3.2 Pyramid Pooling Module
通过以上分析,在接下来的内容中,我们介绍了金字塔池模块,经实证证明,它是一种有效的全局上下文先验。
在深层神经网络中, 感 受 野 的 大 小 可 以 大 致 表 明 我 们 使 用 上 下 文 信 息 的 多 少 程 度 \color{red}{感受野的大小可以大致表明我们使用上下文信息的多少程度} 感受野的大小可以大致表明我们使用上下文信息的多少程度。虽然从理论上讲,ResNet的感受野【13】已经大于输入图像,但Zhou等人【42】表明,CNN的经验感受野比理论上的感受野小得多,特别是在高水平层(high-level layers)。这使得许多网络没有充分整合重要的全局场景先验。我们通过提出有效的全局先验表征来解决这个问题。
全局平均池化作为全局上下文先验是一个很好的baseline模型,通常用于图像分类任务[34,13]。在[24]中,它成功地应用于语义分割。但对于ADE20K中的复杂场景图像【43】,这种策略不足以覆盖必要的信息。这些场景图像中的像素是关于许多物品和对象的注释。直接将它们融合成单个向量可能会丢失空间关系并导致歧义。在这方面,全局上下文信息和子区域上下文信息被认为是更有助于区分不同类别。一个更强大的表征(representation )可以是来自不同子区域的信息与这些感受野的融合。场景/图像分类的经典著作[18,12]也得出了类似的结论。
在[12]【 K. He, X. Zhang, S. Ren, and J. Sun. Spatial pyramid pooling in deep convolutional networks for visual recognition. In ECCV, 2014. 1, 3】中,通过金字塔池化生成的不同级别的特征图最终被展平并连接到一个全连接的层中进行分类。该全局先验用于去除CNN对图像分类的固定尺寸约束。为了进一步减少不同子区域之间的上下文信息丢失,我们提出了一种分层全局先验,包含不同尺度的信息,并且在不同子区域之间变化。我们将其称为金字塔池化模块,用于在深度神经网络的最后一层特征图上进行全局场景优先构建,如图3(c)部分所示。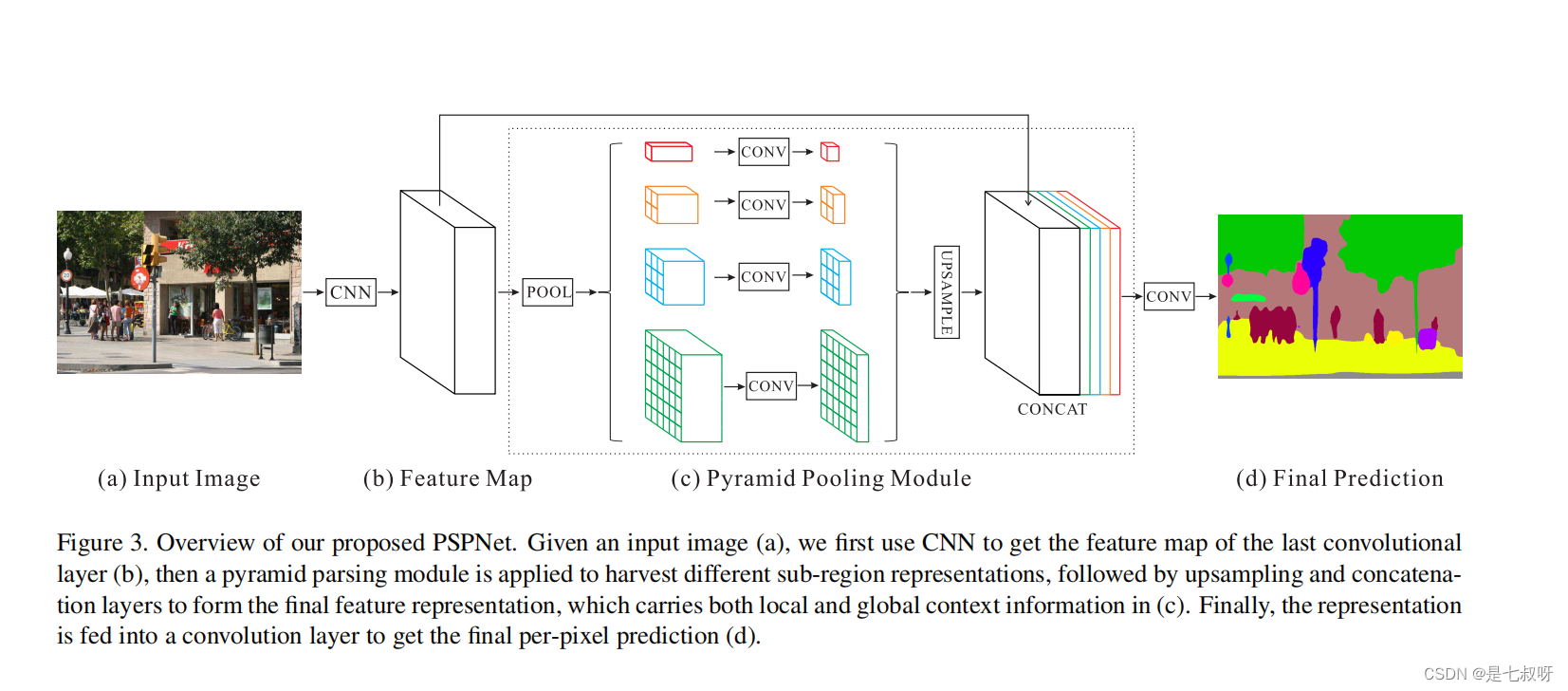
金字塔池化模块融合了四种不同尺度金字塔下的特征。以红色突出显示的最粗糙级别是全局池化,用于生成单个bin输出。以下金字塔级别将特征图划分为不同的子区域,并形成不同位置的集合表示。金字塔池化模块中不同级别的输出包含不同大小的特征图。为了保持全局特征的权重,当金字塔的level size大小为N时,在每个金字塔层后使用1×1卷积层将上下文表示的维数降低到原始特征的1/N。然后通过双线性插值直接对低维特征图进行上采样,得到与原始特征映射相同大小的特征。最后,将不同层级的特征连接为最终的金字塔池全局特征。
请注意,金字塔级别的数量和每个级别的大小是可以修改的。它们与输入金字塔池化层的特征图的大小有关。该结构通过采用不同大小的池化核以一些步长抽象出不同的子区域。因此,多阶段核应该在表征上保持一个合理的缺口。我们的金字塔池模块是一个4层级模块,bin大小分别为1×1、2×2、3×3和6×6。对于max和average之间的池化操作类型,我们在第5.2节中进行了大量的实验来显示差异。
3.3 Network Architecture
使用金字塔池化模块,我们提出了金字塔场景解析网络(PSPNet),如图3所示。给定图3(a)中的输入图像,我们使用预训练的ResNet[13]模型和扩展网络策略( the dilated network strategy)[3,40]来提取特征图。最终的特征图大小是输入图像的1/8,如图3(b)所示。在最顶层的特征图,我们使用(c)中所示的金字塔池化模块来收集上下文信息。使用我们的4级level金字塔,池化核覆盖了图像的整个、一半和小部分。它们融合为全局先验。然后,在(c)的最后部分,我们将先验知识与原始特征连接(concatenate)起来。最后通过卷积层,以生成(d)中的最终预测图。
为了解释我们的结构,PSPNet为像素级场景解析提供了有效的全局上下文先验。金字塔池化模块可以收集不同级别level的信息,比全局池化更具代表性[24]。在计算成本方面,我们的PSPNet与最初的扩展的FCN网络(the original dilated FCN network)相比没有太大的增加。在端到端学习中,可以同时优化全局金字塔池化模块和局部FCN特征。
4. Deep Supervision for ResNet-Based FCN
深度预训练的网络会带来好的性能【17、33、13】。然而,如[32,19]所示,网络深度的增加可能会带来额外的图像分类优化困难。ResNet通过在每个块中使用跳过连接(skip connection in each block)来解决此问题。深度ResNet的后几层主要在前几层的基础上学习残差。
相反,我们建议通过附加损失的监督生成初始结果,然后使用最终损失学习残差剩余结果。因此,深层网络的优化被分解为两个部分,每一个部分都更简单的去求解。
图 4 \color{red}{图4} 图4显示了我们的深度监督ResNet101[13]模型的一个示例。除了使用softmax loss训练最终分类器的主分支外,在第四阶段之后还应用了另一个分类器,即res4b22残差块。与中继反向传播(relay backpropagation)[32]将反向辅助损失阻断到几个浅层不同,我们让这两个损失函数通过之前的所有层。辅助损失帮助优化学习过程,而主分支(the master branch loss)损失承担最大责任。我们增加权重以平衡辅助损失(the auxiliary loss)。
在测试阶段,我们放弃了这个辅助分支,只使用经过好的优化的主分支进行最终预测。这种基于ResNet的FCN的深度监督训练策略在不同的实验环境下具有广泛的实用性,并且适用于预训练的ResNet模型。这体现了这种学习策略的普遍性。更多详情见第5.2节。
5. Experiments
我们提出的方法在场景解析和语义分割挑战方面是成功的。我们在本节中对三个不同的数据集进行了评估,包括ImageNet场景解析挑战2016【43】、PASCAL VOC 2012语义分割【8】和城市场景理解数据集Cityscapes【6】。
5.1 Implementation Details
对于一个实用的深度学习系统,魔鬼总是出现在细节中。我们的实现基于公共平台Caffe【15】。受[4]的启发,我们使用“多边形”(poly)学习率策略,其中当前学习率等于基础1乘以(1− iter maxiter):
电源。我们将基本学习率设置为0.01,电源(power)为0.9。可以通过增加迭代次数来提高性能,ImageNet实验的迭代次数设置为150K,PASCAL VOC为30K,Cityscapes为90K。动量和权重衰减设置为0.9和0.0001。对于数据扩充增强,对于所有数据集,我们采用0.5到2之间的随机镜像和随机调整大小(resize),另外添加10到10度之间的随机旋转,以及ImageNet和PASCAL VOC的随机高斯模糊。这种全面的数据扩充方案使网络能够抵抗过度拟合。我们的网络包含以下扩展卷积[4]( dilated convolution following [4])。
在实验过程中,我们注意到适当大的“cropsize”可以产生良好的性能,而批处理规范化层中的“batchsize”非常重要。由于GPU卡上的物理内存有限,我们在培训期间将“batchsize”设置为16。为了实现这一点,我们从[37]中的Caffe与分支[4]进行修订,并使其支持基于OpenMPI对从多个GPU收集的数据进行批量规范化。对于辅助损失,在实验中我们将权重设置为0.4。
5.2 ImageNet Scene Parsing Challenge 2016
ImageNet Scene Parsing Challenge 2016:ADE20K数据集【43】被用于ImageNet场景解析挑战赛2016。与其他数据集不同的是,ADE20K对于多达150个类和各种场景来说更具挑战性,总共有1038个图像级别标签。挑战数据分为20K/2K/3K图像,用于训练、验证和测试。此外,它还需要解析场景中的对象和内容,这使得它比其他数据集更加困难。为了进行评估,使用了像素级精度(Pixel Acc.)和按类交并比的的平均值(Mean IoU)。Ablation Study for PSPNet:为了评估PSPNet,我们在几种设置下进行了实验,包括最大和平均的池化类型、仅使用一个全局特征或四个级别特征的池化、池化操作之后和连接之前有无降维。如 表 1 \color{red}{表1} 表1所示,在所有设置中,平均池化都比最大池化工作得更好。使用金字塔解析的池化优于使用全局池化。通过降维,性能得到了进一步增强。使用我们提出的PSPNet,最佳设置产生了结果41.68 / 80.04的Mean IoU和Pixel Acc.(%),超过如Liu等人【24】中的全局平均池化40.07 / 79.52。与基线(baseline)相比,PSPNet的表现在绝对提升方面超过它4.45/2.03,在相对差异上为11.95/2.60。
Ablation Study for Auxiliary Loss:引入的辅助损失有助于优化学习过程,同时又不影响主分支中的学习。我们将辅助损失权重α设置在0和1之间,实验结果如 表 2 \color{red}{表2} 表2所示。基线(baseline)使用带有扩展网络的基于ResNet50的FCN,并使用主分支的softmax损失进行优化。添加了辅助损失分治后,α=0.4产生了最佳性能。它的性能超过基准在Mean IoU和Pixel Acc上提高了1.41/0.94。我们认为,考虑到新加的辅助损失增加,更深层次的网络将受益更多。
Ablation Study for Pre-trained Model:先前的研究表明,更深层的神经网络有助于大规模数据分类。为了进一步分析PSPNet,我们对预训练好的ResNet进行了不同深度的实验。我们测试了{50、101、152、269}四个深度。如 图 5 \color{red}{图5} 图5所示,在相同的设置下,将ResNet的深度从50增加到269可以将(Mean IoU和Piexl Acc.)提升2%,的分数从60.86提高到62.35,1.49的绝对提升。 表 3 \color{red}{表3} 表3列出了不同深度ResNet模型预训练PSPNet的详细分数。

More Detailed Performance Analysis: 表 4 \color{red}{表4} 表4显示了我们对ADE20K验证集的更详细分析。除最后一行外,我们所有的结果都使用单尺度检验。“ResNet269+DA+AL+PSP+MS”使用多尺度测试。我们的基准是从带有扩展网络的ResNet50自适应而来的,取得到了34.28的Mean IOU和76.35的Piexl Acc.由于强大的ResNet,它的性能已经超过了之前的其他系统【13】。
与基准相比,我们提出的结构有了进一步的提升。使用数据扩充,我们的结果比基准超出了1.54/0.72,达到了35.82/77.07。使用辅助损失可以进一步提高1.41/0.94,达到37.23/78.01。使用PSPNet,我们注意到提升相对更为显著,提升了4.45/2.03。结果达到了41.68/80.84。与基准结果的差值在绝对提升方面为7.40/3.69,相对提升21.59/4.83(%)。更深层的ResNet269网络能够产生更高的性能,最高可达43.81/80.88。最后,多尺度测试方案将分数移动到了44.94/81.69。
Results in Challenge:使用所提出的网络结构,我们团队在2016 ImageNet场景解析挑战赛中取得了第一名的成绩。 表 5 \color{red}{表5} 表5显示了本次比赛的一些结果。我们的合奏成绩在测试集上达到了57.21%。我们的单模型得到55.38%的分数,甚至比其他几个多模型集成提交的数据还要高。该分数低于验证集上的分数,可能是因为验证集和测试集之间的数据分布不同。
如 图 2 \color{red}{图2} 图2(d)列所示,PSPNet解决了FCN中的常见问题。
图 6 \color{red}{图6} 图6显示了对ADE20K的验证集的另一些解析结果。与基准相比,我们的结果包含更准确和详细的结构。
5.3 PASCAL VOC 2012
我们的PSPNet在语义分割方面也有令人满意的效果。我们在PASCAL VOC 2012分割数据集[8]上进行了实验,该数据集包含20个对象类别和一个背景类。按照[26,7,31,3]的步骤,我们使用带有[10]注释的增强数据(augmented data),得到10582,1449和1456幅图像,用于训练,验证和测试。结果如 表 6 \color{red}{表6} 表6所示,我们基于两种设置,即有无MS-COCO数据集预训练,将PSPNet与之前在测试集上表现最好的方法进行了比较【21】:
MS-COCO预训练的方法标有“†”。为了在场景解析/语义分割任务中与当前基于ResNet的框架[38、9、4]进行公平比较,我们在ResNet101的基础上构建了我们的体系结构,而没有像CRF那样后处理。我们使用几个尺度输入评估PSPNet,并跟着【3,24】使用以下平均结果。
如 表 6 \color{red}{表6} 表6所示,PSPNet在这两种设置上都优于以前的方法。仅使用VOC 2012数据进行训练,我们达到82.6%的准确率——我们在所有20个类别中都获得了最高的准确率(the highest accuracy)。当PSPNet使用MS-COCO数据集进行预训练时,它达到85.4%的准确率,其中20个类中有19个类的精度是最高。有趣的是,我们仅使用VOC 2012数据训练的PSPNet优于使用MS-COCO预训练模型训练的现有方法。
有人可能会争论,自从提出ResNet以来,基于我们的分类模型比以前的几种方法更强大。为了展示我们的独特贡献,我们表明,我们的方法也优于使用相同模型的最先进框架( state-of-the-art frameworks),包括FCRNs【38】、LRR【9】和DeepLab【4】。在这个过程中,我们甚至没有使用费时但有效的后处理,如CRF,如[4,9]中所述。
图 7 \color{red}{图7} 图7中示出了几个示例。对于第一行中的“cows”,我们的基准模型将其视为“horse”和“dog”,而PSPNet会更正这些错误。对于第二行和第三行中的“aeroplane”和“table”,PSPNet会找到缺失的部分。对于下面行中的“person”、“bottle”和“plant”,与基准模型相比,PSPNet在图像中的这些小尺寸对象类上表现良好。
图 9 \color{red}{图9} 图9中包含了PSPNet和其他方法之间的更多视觉比较。
5.4 Cityscapes
Cityscapes【6】是最近发布的用于语义城市场景理解的数据集。它包含从不同季节的50个城市收集的5000幅高质量像素级精细标注图像。图像分为2975、500和1525组用于训练、验证和测试。它定义了19个类别,每个类别都包含了内容和对象(stuff and objects)。此外,还为两种对比设置提供了20000幅粗略标注的图像,即仅使用精细数据或同时使用精细和粗略数据进行训练。使用精细和粗略数据训练的方法用“\”标记。详细结果见 表 7 \color{red}{表7} 表7。为了进行公平比较,我们的基准模型是DeepLab[4]中的ResNet101,测试流程遵循第5.3节。
表 7 \color{red}{表7} 表7中的统计数据表明,PSPNet优于其他方法,具有显著的优势。同时使用精细和粗糙数据进行训练,使我们的方法得到80.2准确率。 图 8 \color{red}{图8} 图8中示出了几个示例。
表 8 \color{red}{表8} 表8显示了测试集的详细分类结果。
6. Concluding Remarks(结束语)
我们提出了一种有效的金字塔场景解析网络,用于复杂场景的理解。全局金字塔池化特征提供了额外的上下文信息(additional contextual information)。我们还为基于ResNet的FCN网络提供了一种深度监督的优化策略。我们希望公开的实现细节能够帮助社区采用这些有用的场景解析和语义分割策略,并改进相关技术。
Acknowledgements(致谢)
我们要感谢孙刚和童晓在培训基本分类模型方面的帮助,感谢罗群的技术支持。这项工作得到香港特别行政区研究资助局的资助(项目编号2150760)。
边栏推荐
- C # realize solving the shortest path of unauthorized graph based on breadth first BFS -- complete program display
- Nacos
- 力扣-两数之和
- Introduction to webrtc concept -- an article on understanding source, track, sink and mediastream
- Edge Drawing: A combined real-time edge and segment detector 翻译
- 服务器渲染技术jsp
- Latest interface automation interview questions
- The value of the second servo encoder is linked to the NC virtual axis of Beifu PLC for display
- MySQL knowledge points
- JS daily development tips (continuous update)
猜你喜欢

Chapitre 03 Bar _ Gestion des utilisateurs et des droits

MySQL knowledge points

Let's just say I can use thousands of expression packs

Huawei operator level router configuration example | configuration optionA mode cross domain LDP VPLS example

Hal library setting STM32 interrupt

Depth first traversal of C implementation Diagram -- non recursive code

HTB-Lame
How the network is connected: Chapter 2 (Part 2) packet receiving and sending operations between IP and Ethernet

Kmeans

pytorch训练深度学习网络设置cuda指定的GPU可见
随机推荐
Go tool cli for command line implementation
# 使用 KubeKey 搭建 Kubernetes/KubeSphere 环境的'心路(累)历程'
EtherCAT简介
二叉树神级遍历:Morris遍历
Subnet division and subnet summary
Completely solve the lost connection to MySQL server at 'reading initial communication packet
How to verify whether the contents of two files are the same
MySQL knowledge points
Kmeans
File upload and download
shell脚本使用两个横杠接收外部参数
[linear DP] shortest editing distance
Learning notes for introduction to C language multithreaded programming
gcc使用、Makefile总结
Hal library setting STM32 interrupt
多元线性回归
The value of the second servo encoder is linked to the NC virtual axis of Beifu PLC for display
文件上传下载
Latest interface automation interview questions
4、【WebGIS实战】软件操作篇——数据导入及处理