当前位置:网站首页>Application of comparative learning (lcgnn, videomoco, graphcl, XMC GaN)
Application of comparative learning (lcgnn, videomoco, graphcl, XMC GaN)
2022-07-25 12:02:00 【Shangshanxianger】
The concept of comparative learning has been sorted out in blog posts before , More important and popular articles , And some existing applications ( Mainly based on InfoNCE And other early means ):
- Contrastive Learning( Comparative learning ,MoCo,SimCLR,BYOL,SimSiam)
- Application of contrastive learning (CLCaption,C-SWM,CMC,SGL))
This blog will continue to sort out some applications of comparative learning , It's mainly focused on MoCo and SimCLR Wait for the model .
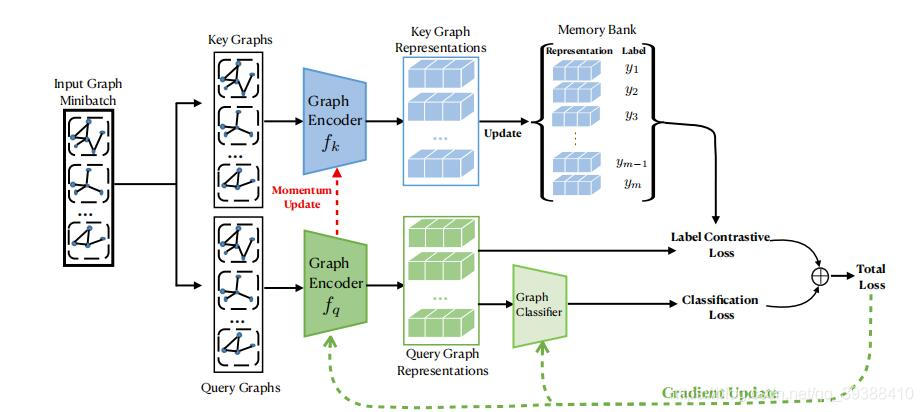
Label Contrastive Coding based Graph Neural Network for Graph Classification
MoCo framework . Graph classification graph neural network based on label contrast coding . Generally, the method of making graph classification is to learn the representation of graph first , There are two main types 1 First calculate node Embedding Repolymerization 2 direct graph Embedding, Then do the classification of the map . However, the author believes that these methods ignore the instance level granularity , The finer granularity of discriminant information between instances is conducive to the graph classification task .
Oh, I think it's more effective 、 More comprehensive use of label information , A graph neural network based on tag contrast coding is proposed (LCGNN), Specifically, tag contrast loss proposed in self supervised learning is used to promote instance level intra class aggregation and inter class separability . The model diagram is shown in the figure above , Basically ,LCGNN It is modeled MoCo The architecture introduces dynamic label repository and momentum update encoder .
- Input is key graphs and query graphs.
- Graph encoder Consider two ,1 yes Graph Isomorphism Network(GIN), Isomorphic graph is simple GNN then Sum polymerization .2 yes Hierarchical Graph Pooling with Structure Learning (HGP-SL), It can combine graph pooling and structure learning into a unified module to generate the hierarchical representation of graphs .
- The latter part is related to MoCo It's the same . There is one Memory Bank, then Momentum Update.
- final loss Yes label constructive and classification form .
This design can essentially be considered as a label enhancement . Then pull the instance with the same label closer , Instances with different labels will push away from each other .
- paper:https://arxiv.org/abs/2101.05486

VideoMoCo: Contrastive Video Representation Learning with Temporally Adversarial Examples
come from CVPR21 The article , Architecture is also based on MOCO, The task is unsupervised video to show learning . The main architecture is shown in the figure above , It's easy to understand , It is to improve the video sequence from two perspectives MoCo The time characteristic of indicates , As above, ab perhaps cd, One of the perspectives is accomplished by discarding frames , Mainly involves :
- generator . Delete several frames in time , And adaptively discard different frames , This is done through time decay .
- Discriminator . Complete the feature representation , No matter how the frame is removed .
And then to two view Carry out similar MoCo Comparative learning of . That is, use time decay to simulate the keys in the memory queue (key) attenuation , The momentum encoder is updated after the key is entered , When using the current input sample for comparative learning , The representation ability of these keys will decrease . This decline is reflected by time decay , To make the input sample enter the nearest key in the queue .
- paper:https://arxiv.org/abs/2103.05905
- code:https://github.com/tinapanpt/VideoMoCo

Graph Contrastive Learning with Augmentations
The last one is MoCo Ideas , This one comes from NIPS20 The article GraphCL And SimCLR The idea is the same , That is, use a variety of data enhancement methods before comparative learning . Motivation is traditional Graph The model will have over-smoothing or information loss This kind of problem , Therefore, the author believes that it is necessary to develop pre training techniques . The complete architecture is shown in the figure above , Basically is SimCLR The routine of . And GraphCL Developed 4 An enhanced mode :
- Node drop . Randomly discard some vertices and their connections . This means that the lack of some vertices does not affect the semantics of the graph .
- Edge disturbance . Perturb the connectivity in the graph by randomly adding or discarding a certain proportion of edges . This means that the connection mode of edges has certain robustness .
- Attribute mask . Use its context information ( That is, the remaining attributes ) recovery masked Vertex properties of . The basic assumption is that the lack of some vertex attributes will not have a great impact on the model prediction .
- Subgraphs . Use random walk to sample a subgraph , It assumes that the semantics of the graph can be greatly preserved in the local structure .
After the attribute enhancement , use GNN Come on encoder( That is, the yellow part in the figure ), And then again Projection head,Contrastive loss, These are the same as SimCLR The same .
- code:https://github.com/Shen-Lab/GraphCL

Cross-Modal Contrastive Learning for Text-to-Image Generation
This application scenario is used for text to image generation . The overall architecture is also similar to SimCLR It's like . First, because the background is cross modal image generation , Therefore, the generated pictures are required to be output
- Coherent . The semantics of text and image should match as a whole .
- Clear . Parts of the image are also recognizable , And consistent with the words of the text .
- Highly restored pictures . When the conditions are consistent, the generated image should be similar to the real image .
To solve this problem , The author proposes a cross modal contrast generation countermeasure network based on maximizing the mutual information between image and text (XMC-GAN). The specific architecture is shown in the figure above ,XMC-GAN An attention self-regulation generator is used to enhance the text - Correspondence between images ( In fact, the noise , Word attention , Overall representation fusion , Specifically, the dolls in the above half of the figure ), At the same time, a contrast discriminator is used as the feature extractor of contrast learning , Here, three kinds of images and texts generated by forced alignment are designed :
- From image to sentence . Directly calculate the comparative loss of features .
- Image area to word . Calculate the paired cosine similarity matrix between all words in the sentence and all areas in the image , Then calculate the comparative loss .
- Image to image contrast loss . Calculate the contrast loss of true image and false image .
See the original text for yourself :
- paper:https://arxiv.org/abs/2101.04702v2

TRAINING GANS WITH STRONGER AUGMENTATIONS VIA CONTRASTIVE DISCRIMINATOR
Supplement ICLR2021 The article , hold GAN Combine it with comparative learning , Make a discriminator in the form of comparison . Especially about GAN Data enhancement technology can be stable to a certain extent GAN Training , So it seems that comparative learning +GAN It's a very suitable match . So follow the enhanced thinking , This article is also SimCLR One kind of , The model architecture is as follows , The generator can get multiple samples , Then they were sent to D in , The main contribution is to propose Contrastive Discriminator (ContraD).
- ContraD The main goal of is not to minimize GAN Loss of discriminator , But to learn a kind of relationship with GAN Compatible comparison indicates . This means that the goal will not destroy comparative learning , The representation still contains enough information to distinguish between real and false samples , Therefore, a small neural network discriminator is enough to perform its task on the representation .
loss Is composed of two parts , One is SimCLR Of loss, At the same time, because we need to distinguish positive and negative samples, it is not enough to just compare and learn , So we still need dis loss To help train .
- code:https://github.com/jh-jeong/ContraD
边栏推荐
- Pycharm connects to the remote server SSH -u reports an error: no such file or directory
- Risks in software testing phase
- 软件缺陷的管理
- The applet image cannot display Base64 pictures. The solution is valid
- 已解决The JSP specification requires that an attribute name is preceded by whitespace
- JS常用内置对象 数据类型的分类 传参 堆栈
- session和cookie有什么区别??小白来告诉你
- Teach you how to configure S2E as the working mode of TCP client through MCU
- JaveScript循环
- brpc源码解析(五)—— 基础类resource pool详解
猜你喜欢

阿里云技术专家秦隆:可靠性保障必备——云上如何进行混沌工程
![[GCN multimodal RS] pre training representations of multi modal multi query e-commerce search KDD 2022](/img/9c/0434d40fa540078309249d415b3659.png)
[GCN multimodal RS] pre training representations of multi modal multi query e-commerce search KDD 2022

知识图谱用于推荐系统问题(MVIN,KERL,CKAN,KRED,GAEAT)

Teach you how to configure S2E as the working mode of TCP server through MCU

JS数据类型以及相互转换
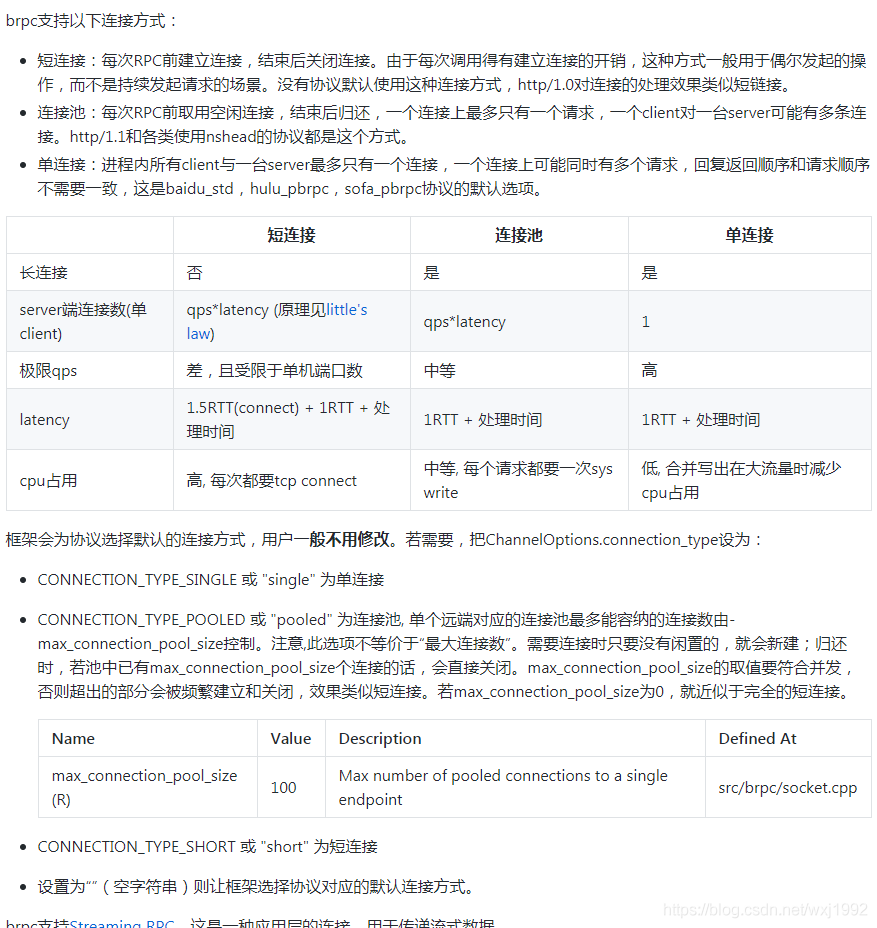
brpc源码解析(三)—— 请求其他服务器以及往socket写数据的机制

【多模态】《HiT: Hierarchical Transformer with Momentum Contrast for Video-Text Retrieval》ICCV 2021

JaveScript循环

【USB设备设计】--复合设备,双HID高速(64Byte 和 1024Byte)
![[MySQL learning 09]](/img/27/2578f320789ed32552d6f69f14a151.png)
[MySQL learning 09]
随机推荐
微信公众号开发 入手
Go 垃圾回收器指南
winddows 计划任务执行bat 执行PHP文件 失败的解决办法
return 和 finally的执行顺序 ?各位大佬请看过来,
【AI4Code】CodeX:《Evaluating Large Language Models Trained on Code》(OpenAI)
Web APIs (get element event basic operation element)
A beautiful gift for girls from programmers, H5 cube, beautiful, exquisite, HD
Transformer变体(Routing Transformer,Linformer,Big Bird)
Flinksql client connection Kafka select * from table has no data error, how to solve it?
Power Bi -- these skills make the report more "compelling"“
Javescript loop
Teach you how to configure S2E as the working mode of TCP client through MCU
软件测试阶段的风险
Solved files' name is invalid or doors not exist (1205)
Brpc source code analysis (V) -- detailed explanation of basic resource pool
【GCN多模态RS】《Pre-training Representations of Multi-modal Multi-query E-commerce Search》 KDD 2022
Meta-learning(元学习与少样本学习)
There is no sound output problem in the headphone jack on the front panel of MSI motherboard [solved]
Maskgae: masked graph modeling meets graph autoencoders
brpc源码解析(一)—— rpc服务添加以及服务器启动主要过程