当前位置:网站首页>mysql语法(纯语法)
mysql语法(纯语法)
2022-07-23 05:37:00 【青樖】
mysql -h 主机名 -P端口号 -u用户名 -p密码
例如: mysql -h localhost -P 3306 -uroot -proot
注意:
1 -p与密码之间不能有空格,其他参数名与参数值之间可以有空格也可以没有空格
2 密码建议在下一行输入,保证安全
mysql -h localhost -P 3306 -u root -p
Enter password:****
3 客户端和服务器在同一台机器上,所以输入localhost或者IP地址127.0.0.1。
同时,因为是连接本机: -hlocalhost就可以省略,如果端口号没有修改:-P3306也可以省略
简写格式
mysql -u root -p
Enter password:****
查看服务版本信息:
c:\> mysql --version
退出:exit quit
展示所有数据库
show databases;
SHOW DATABASES;
创建数据库:CREATE DATABASE 数据库名; # 使用的默认的字符集
CREATE DATABASE 数据库名 CHARACTER SET 字符集; # 显示的指明了要创建的数据库的字符集
CREATE DATABASE IF NOT EXISTS 数据库名; (推荐)
#其中order使用``飘号,因为order和系统关键字或系统函数名等预定义标识符重名了
CREATE TABLE `order`(
id INT,
lname VARCHAR(20)
);
查看当前正在使用的数据库:SELECT DATABASE();
使用/切换数据库 :USE 数据库名;
SHOW TABLES FROM 数据库名;
#如果只是查看当前库下的所有表
show tables
查看数据库的创建信息
SHOW CREATE DATABASE 数据库名;
或者:
SHOW CREATE DATABASE 数据库名\G (命令行形式)
方式1:删除指定的数据库
DROP DATABASE 数据库名;
方式2:删除指定的数据库(推荐)
DROP DATABASE IF EXISTS 数据库名;
修改数据库 (了解)
更改数据库字符集
ALTER DATABASE 数据库名 CHARACTER SET 字符集; #比如:gbk、utf8等
DDL-操作表-查询
查询某个数据库下的所有表名称 SHOW TABLES;
查看某个库中的具体的表的结构
DESCRIBE 表名;
或
DESC 表名;
show columns from 表名;
desc 数据库名.表名; # 在一个库中查看另一个库中的表的结构
Field:表示字段名称。
Type:表示字段类型,这里 barcode、goodsname 是文本型的,price 是整数类型的。
Null:表示该列是否可以存储NULL值。
Key:表示该列是否已编制索引。PRI表示该列是表主键的一部分;UNI表示该列是UNIQUE索引的一部分;MUL表示在列中某个给定值允许出现多次。
Default:表示该列是否有默认值,如果有,那么值是多少。
Extra:表示可以获取的与给定列有关的附加信息,例如AUTO_INCREMENT等。
SHOW CREATE TABLE 表名\G
# 展示创建表的结构信息
CREATE TABLE `emp` (
`e_id` int(11) DEFAULT NULL,
`e_name` varchar(20) DEFAULT NULL,
`e_bir` date DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8
DDL-操作表-创建表
CREATE TABLE [IF NOT EXISTS] 表名(
字段1 数据类型 [约束条件] [默认值],
字段2 数据类型 [约束条件] [默认值],
字段3 数据类型 [约束条件] [默认值],
……
字段n 数据类型 # 最后一个字段且该字段后边没有内容不能加逗号
[表约束条件]
);
-- 创建表
CREATE TABLE emp (
-- int类型
emp_id INT,
-- 最多保存20个中英文字符
emp_name VARCHAR(20),
-- 总位数不超过15位
salary DOUBLE,
-- 日期类型
birthday DATE
);
# 创建的A表不是空表 有B的所以信息
CREATE TABLE A AS SELECT * FROM B;
# 创建的A是空表,但是表字段和B保持一致
CREATE TABLE A AS SELECT * FROM B WHERE 1=2;
# 创建的表还可以是其他表的一部分数据
CREATE TABLE A
AS
SELECT B_id, B_name, B_salary
FROM B
WHERE B_id = 80;
#在通过as方式创建表的时候还可以是其他库中的表
create table 表
as
select * from 库名.表名;
DDL-操作表-数据模型
删除表
DROP TABLE [IF EXISTS] 数据表1 [, 数据表2, …, 数据表n]; #可以一次性的删除多个
DROP TABLE 表名;
重命名表
RENAME TABLE 表名 TO 新表名;
ALTER table 表名 RENAME [TO] 新表名; -- [TO]可以省略
清空表
TRUNCATE TABLE 表名;
TRUNCATE语句不能回滚,而使用 DELETE 语句删除数据,可以回滚
追加一个列 ALTER TABLE dept ADD XX varchar(15);
ALTER TABLE 表名 ADD [COLUMN] 字段名 字段类型 [FIRST|AFTER 字段名];
# 可以选择添加位置【FIRST|AFTER 字段名】
# 如果不选默认是在最后一列
修改一个列 ALTER TABLE 表名 MODIFY 列名 VARCHAR(30);
ALTER TABLE 表名 MODIFY [COLUMN] 字段名1 字段类型 [DEFAULT 默认值] [FIRST|AFTER 字段名2];
#如果想调整位置first 不能跟字段 表示直接放到第一位
#after 能跟字段名 表示放到哪个字段后边
重命名一个列 ALTER TABLE dept80 CHANGE department_name dept_name varchar(15);
ALTER TABLE 表名 CHANGE [column] 列名 新列名 新数据类型;
删除一个列 ALTER TABLE 表名 DROP [COLUMN]字段名
ALTER TABLE dept DROP COLUMN job_id;
DML-操作数据-添加
为表的所有字段按默认顺序插入数据
INSERT INTO 表名 VALUES (value1,value2,....);
INSERT INTO departments VALUES (70, 'Pub', 100, 1700);
为表的指定字段插入数据
INSERT INTO 表名(column1 [, column2, …, columnn]) VALUES (value1 [,value2, …, valuen]);
同时插入多条记录
INSERT INTO 表名
VALUES
(value1 [,value2, …, valuen]),
(value1 [,value2, …, valuen]),
……
(value1 [,value2, …, valuen]);
INSERT INTO 表名(column1 [, column2, …, columnn])
VALUES
(value1 [,value2, …, valuen]),
(value1 [,value2, …, valuen]),
……
(value1 [,value2, …, valuen]);
将查询结果插入到表中
INSERT INTO 目标表名
(tar_column1 [, tar_column2, …, tar_columnn])
SELECT
(src_column1 [, src_column2, …, src_columnn])
FROM 源表名
[WHERE condition]
所有列
INSERT INTO emp2
SELECT *
FROM employees
WHERE department_id = 90;
指定列
INSERT INTO sales_reps(id, name, salary, commission_pct)
SELECT employee_id, last_name, salary, commission_pct
FROM employees
DML-操作数据-修改删除
修改 update
UPDATE 表名
SET column1=value1, column2=value2, … , column=valuen
[WHERE condition]
UPDATE employees
SET department_id = 70
WHERE employee_id = 113;
如果省略 WHERE 子句,则表中的所有数据都将被更新
UPDATE employees SET department_id = 70
删除 delete
DELETE FROM table_name [WHERE <condition>];
DELETE FROM departments WHERE department_name = 'Finance';
如果省略 WHERE 子句,则表中的全部数据将被删除
DELETE FROM copy_emp;
删除中的数据完整性错误 有关联关系的情况
DELETE FROM departments WHERE department_id = 60;
You cannot delete a row that contains a primary key that is used as a foreign key in another table.
不能删除包含在另一个表中用作外键的主键的行。
DQL-基础查询
SELECT 1; #没有任何子句
SELECT 9/2; #没有任何子句
等同于
select 1+1 FROM DUAL
DUAL:伪表
SELECT ... FROM
SELECT 标识选择哪些列
FROM 标识从哪个表中选择
SELECT *
FROM 表名;
*: 表示表中的所有的列;
SELECT 字段名1, 字段名1
FROM 表名;
列的别名
SELECT name as 姓名, address 地址 from stu;
SELECT name as "姓名", address "地 址" from stu;
或者
SELECT name "姓名", address '地 址' from stu;
去除重复行 DISTINCT
默认情况下,查询会返回全部行,包括重复行。
SELECT address from stu;
在SELECT语句中使用关键字DISTINCT去除重复行
SELECT DISTINCT address from stu;
去重关键字要在所有列的前边
联合去重
SELECT DISTINCT address,math from stu;
注意:
DISTINCT 需要放到所有列名的前面,不然报错
DISTINCT 其实是对后面所有列名的组合进行去重,
空值参与运算
所有运算符或列值遇到null值,运算的结果都为null
这里你一定要注意,在 MySQL 里面, 空值不等于空字符串。一个空字符串的长度是 0,而一个空值的长度是空。而且,在 MySQL 里面,空值是占用空间的。
解决方案: 使用函数IFNULL
SELECT id,name,address,math,IFNULL(english,0)+2 from stu;
着重号
解决方案 着重号 tab键上边的 ~ 直接按
SELECT * from `order`;
SELECT * from `ORDER`;
查询常数
SELECT *, math+IFNULL(english,0) "总成绩" from stu;
DQL-条件查询
过滤数据
SELECT 字段1,字段2
FROM 表名
WHERE 过滤条件
算数运算符
| 运算符 | 名称 | 作用 | 例子 |
|---|---|---|---|
| + | 加法 | 计算两个值或者表达式的和 | select a+b |
| - | 减法 | 计算两个值或者表达式的差 | select a-b |
| * | 乘法 | 计算两个值或者表达式的乘积 | select a*b |
| / 或者DIV | 除法 | 计算两个值或者表达式的商 | select a/b |
| %或者MOD | 取余/求模 | 计算两个值或者表达式的余数 | select a%b |
比较运算符
| 运算符 | 名称 | 作用 | 例子 |
|---|---|---|---|
| = | 等于运算符 | 判断两个值,字符串,表达式是否相等 | |
| <=> | 安全等于运算符 | 安全的判断两个值,字符串,表达式是否相等 | |
| <> 或者 != | 不等于运算符 | 判断两个值,字符串,表达式是否不相等 | |
| < | 小于运算符 | 判断前面的值,字符串,或表达式是否小于后边的值,字符串,和表达式 | |
| <= | 小于等于运算符 | 判断前面的值,字符串,或表达式是否小于等于后边的值,字符串,和表达式 | |
| > | 大于运算符 | 判断前面的值,字符串,或表达式是否大于后边的值,字符串,和表达式 | |
| >= | 大于等于运算符 | 判断前面的值,字符串,或表达式是否大于等于后边的值,字符串,和表达式 |
非符号运算符
| 运算符 | 名称 | 作用 | 示例 |
|---|---|---|---|
| IS NULL | 为空运算符 | 判断值,字符串,表达式是否为空 | select b from table where a is null |
| IS NOT NULL | 不为空运算 | 判断值,字符串,表达式是否为不空 | select b from table where a is not null |
| LEAST | 最小值运算符 | 在多个值中返回最小值 | select d from table where c least(a,b) |
| GREATEST | 最大值运算符 | 在多个值中返回最大值 | select d from table where c greatest(a,b) |
| BETWEEN AND | 两个值之间的运算符 | 判断一个值是否在两个值之间 | select d from table where c betweed A and B |
| ISNULL | 为空运算符 | 判断值,字符串,表达式是否为空 | select b from table where a isnull |
| IN | 属于运算符 | 判断一个值是否为列表中的任意一个值 | select d from table where c in(a,b) |
| NOT IN | 不属于运算符 | 判断一个值是否不是列表中的任意一个值 | select d from table where c not in(a,b) |
| LIKE | 模糊匹配运算符 | 判断一个值是否匹配模糊匹配规则 | select b from table where a like c |
| REGEXP | 正则表达式运算符 | 判断一个值是否符合正则表达式的规则 | select b from table where a regexp c |
| RLIKE | 正则表达式运算符 | 判断一个值是否符合正则表达式的规则 | select b from table where a rlike c |
逻辑运算符
| 运算符 | 作用 | 示例 |
|---|---|---|
| NOT 或者 ! | 逻辑非 | select not a |
| AND 或者 && | 逻辑与 | select a and b |
| OR 或者 || | 逻辑或 | select a or b |
| XOR | 逻辑异或 | select a xor b |
DQL-条件查询-模糊查询
LIKE运算符
“%”:匹配0个1个或多个字符。
“_”:只能匹配一个字符。
- 查询年龄大于20岁的学员信息
select * from stu where age > 20;
- 查询年龄大于等于20岁的学员信息
select * from stu where age >= 20;
- 查询年龄大于等于20岁 并且 年龄 小于等于 30岁 的学员信息
select * from stu where age >= 20 && age <= 30;
select * from stu where age >= 20 and age <= 30;
> 上面语句中 && 和 and 都表示并且的意思。建议使用 and 。
>
> 也可以使用 between ... and 来实现上面需求
DQL-排序查询
使用 ORDER BY 子句排序
ASC(ascend): 升序 (从上往下 从小到大 默认)
DESC(descend):降序 (从上往下 从大到小)
ORDER BY 子句在SELECT语句的结尾。
单列排序
**按照年龄升序**
SELECT * FROM stu ORDER BY age asc; # asc可省略
**按照年龄降序**
SELECT * FROM stu ORDER BY age desc;
使用列的别名排序
可以使用列的别名作为排序的条件
SELECT *,math+IFNULL(english,0) as 总成绩 FROM stu ORDER BY 总成绩 desc;
# 但是不能作为where 的条件使用 会报错
SELECT
*, math + IFNULL(english, 0) AS 总成绩
FROM
stu
WHERE
总成绩 > 120
ORDER BY
总成绩 DESC;
原因: 执行顺序是 先执行from where 再去select 才有的别名
强调顺序: where 需要在 from 之后 order by 之前
多列排序
#按照数学成绩降序,如果数学成绩相同,按照英语成绩升序
SELECT * FROM stu ORDER BY math desc,english asc;
DQL-聚合函数
| 函数 | 使用 |
|---|---|
| 数值函数 | |
| RAND() | 返回0~1的随机值 |
| ROUND(x) | 返回一个对x的值进行四舍五入后,最接近于X的整数 |
| ROUND(x,y) | 返回一个对x的值进行四舍五入后最接近X的值,并保留到小数点后面Y位 |
| TRUNCATE(x,y) | 返回数字x截断为y位小数的结果 |
| 字符串函数 | MySQL中,字符串的位置是从1开始的。 |
| CHAR_LENGTH(s) | 返回字符串s的字符数。作用与CHARACTER_LENGTH(s)相同 |
| LENGTH(s) | 返回字符串s的字节数,和字符集有关 |
| CONCAT(s1,s2,......,sn) | 连接s1,s2,......,sn为一个字符串 |
| 日期函数 | |
| CURDATE() ,CURRENT_DATE() | 返回当前日期,只包含年、月、日 |
| CURTIME() , CURRENT_TIME() | 返回当前时间,只包含时、分、秒 |
| NOW() / SYSDATE() / CURRENT_TIMESTAMP() / LOCALTIME() / LOCALTIMESTAMP() | 返回当前时间,只包含年月日时、分、秒 |
| 流程控制函数 | |
| IFNULL(value1, value2) | 如果value1不为NULL,返回value1,否则返回value2 |
| 加密函数 | |
| MD5(str) | 返回字符串str的md5加密后的值,也是一种加密方式。若参数为NULL,则会返回NULL |
| SHA(str) | 从原明文密码str计算并返回加密后的密码字符串,当参数为NULL时,返回NULL。SHA加密算法比MD5更加安全。 |
| 信息函数 | |
| VERSION() | 返回当前MySQL的版本号 |
| DATABASE(),SCHEMA() | 返回MySQL命令行当前所在的数据库 |
常用的聚合函数 聚合函数不能嵌套调用。比如不能出现类似“AVG(SUM(字段名称))”形式的调用。
AVG() SUM() MAX() MIN()
SELECT AVG(age), MAX(age),MIN(age), SUM(age) FROM stu;
SUM()SELECT COUNT(*) FROM stu;
DQL-分组查询
SELECT 字段列表 FROM 表名 [WHERE 分组前条件限定] GROUP BY 分组字段名 [HAVING 分组后条件过滤];
#查询男女学生的,数学最高分,数学平均分
SELECT
sex,
max(math) 数学最高分,
avg(math) 数学平均分
FROM
stu
GROUP BY
sex;
非聚合函数使用的字段或者没有在 group by中出现的字段,不能出现的 select中
反之 在 group by中出现的字段不一定非要写在 select 中
但是在mysql中出现不会报错但是没有意义, 在oracle中会报错
HAVING
行已经被分组。
过滤条件使用了聚合函数。就不能使用where了,必须使用having替换where 否则报错
满足HAVING 子句中条件的分组将被显示。
HAVING 不能单独使用,必须要跟 GROUP BY 一起使用。
#按照性别查询数学的平均分,并且平均分要高于80的
SELECT
sex,
avg(math) avg
FROM
stu
GROUP BY
sex
HAVING
avg > 80;不能在 WHERE 子句中使用聚合函数
#按照性别查询数学的平均分,并且平均分要高于80的
SELECT
sex,
avg(math) avg
FROM
stu
where avg>80
GROUP BY
sex
#可以这样去写
SELECT
sex,
avg(math) avg
FROM
stu
HAVING
avg > 50;
# 现在没有了分组 max函数得到就是一个组或者一个值了 再去过滤就没有啥意思了 WHERE和HAVING的对比
#查询'香港','湖南','南京' 中最高数学分数高于80的地区
#方式1
SELECT
address,
MAX(math) max
FROM
stu
WHERE
address IN ('香港', '湖南', '南京')
GROUP BY
address
HAVING
max > 80
#方式2
SELECT
address,
MAX(math) max
FROM
stu
GROUP BY
address
HAVING
max > 80
AND address IN ('香港', '湖南', '南京');
# 方式1 的执行效率高于方式2
当过滤条件中有聚合函数的时候必须声明在having中
当过滤条件中没有聚合函数的时候,此过滤条件可以声明having或者where 中
但是强烈建议写在where中, 在实际开发中必须写在where中 DQL-分页查询
LIMIT [位置偏移量,] 行数
--前10条记录: 第一页
SELECT * FROM 表名 LIMIT 0,10; 或者 SELECT * FROM 表名 LIMIT 10;
--第11至20条记录: 第二页
SELECT * FROM 表名 LIMIT 10,10;
--第21至30条记录: 第三页
SELECT * FROM 表名 LIMIT 20,10;分页显式公式==:(当前页数-1)*每页条数,每页条数==
SELECT * FROM table
LIMIT (PageNo - 1)*PageSize,PageSize;
#从(PageNo - 1)*PageSize位置开始查询, 查询PageSize条注意:LIMIT 子句必须放在整个SELECT语句的最后!包括排序之后
LIMIT 0, 条数 ;等价于 LIMIT 条数
#查询第一条数据
SELECT * FROM stu limit 0,1;
SELECT * FROM stu limit 1;
#查询第3到5条数据(从第三条数据开始查询,查询3条)
SELECT * FROM stu limit 2,3;
#每页显示两条,展示第三页 (3-1)*2,2
SELECT * FROM stu LIMIT 4,2;分页的拓展
如果是 SQL Server 和 Access,需要使用 TOP 关键字
SELECT TOP 5 name, hp_max FROM heros ORDER BY hp_max DESC如果是 DB2,使用FETCH FIRST 5 ROWS ONLY这样的关键字
SELECT name, hp_max FROM heros ORDER BY hp_max DESC FETCH FIRST 5 ROWS ONLY如果是 Oracle,你需要基于 ROWNUM 来统计行数
SELECT rownum,last_name,salary FROM employees WHERE rownum < 5 ORDER BY salary DESC;需要说明的是,这条语句是先取出来前 5 条数据行,然后再按照 hp_max 从高到低的顺序进行排序。但这样产生的结果和上述方法的并不一样。我会在后面讲到子查询,你可以使用
SELECT rownum, last_name,salary
FROM (
SELECT last_name,salary
FROM employees
ORDER BY salary DESC)
WHERE rownum < 10;SELECT的执行过程
SELECT ...,....,... FROM ...,...,.... WHERE 多表的连接条件 AND/OR 不包含组函数的过滤条件 GROUP BY ...,... HAVING 包含组函数的过滤条件 ORDER BY ... ASC/DESC LIMIT ...,... #其中: #(1)from:从哪些表中筛选 #(2)on:关联多表查询时,去除笛卡尔积 #(3)where:从表中筛选的条件 #(4)group by:分组依据 #(5)having:在统计结果中再次筛选 #(6)order by:排序 #(7)limit:分页
==SELECT执行顺序==
你需要记住 SELECT 查询时的两个顺序:
1. 关键字的顺序是不能颠倒的:
SELECT ... FROM ... WHERE ... GROUP BY ... HAVING ... ORDER BY ... LIMIT...2.SELECT 语句的执行顺序(在 MySQL 和 Oracle 中,SELECT 执行顺序基本相同):
FROM -> WHERE -> GROUP BY -> HAVING -> SELECT 的字段 -> DISTINCT -> ORDER BY -> LIMIT比如你写了一个 SQL 语句,那么它的关键字顺序和执行顺序是下面这样的:
SELECT DISTINCT # 查询顺序 5 player_id, count(*) AS num FROM player # from顺序 1 WHERE player_id > 20 # where顺序 2 GROUP BY player_id # 分组顺序 3 HAVING num > 2 # having顺序 4 ORDER BY num DESC # 排序顺序 6 LIMIT 2; # 分页顺序 7
在 SELECT 语句执行这些步骤的时候,每个步骤都会产生一个虚拟表,然后将这个虚拟表传入下一个步骤中作为输入。需要注意的是,这些步骤隐含在 SQL 的执行过程中,对于我们来说是不可见的。
mysql别名问题
MYSQL用的是临时表,在having前已经产生了数据,所以你可以在having中用别名
where中不能直接使用字段的别名,group by、having、order by能够直接使用
sql的执行原理
当我们拿到了查询数据表的原始数据,也就是最终的虚拟表
vt1,就可以在此基础上再进行WHERE 阶段。在这个阶段中,会根据 vt1 表的结果进行筛选过滤,得到虚拟表vt2。然后进入第三步和第四步,也就是
GROUP 和 HAVING 阶段。在这个阶段中,实际上是在虚拟表 vt2 的基础上进行分组和分组过滤,得到中间的虚拟表vt3和vt4。当我们完成了条件筛选部分之后,就可以筛选表中提取的字段,也就是进入到
SELECT 和 DISTINCT 阶段。首先在 SELECT 阶段会提取想要的字段,然后在 DISTINCT 阶段过滤掉重复的行,分别得到中间的虚拟表
vt5-1和vt5-2。当我们提取了想要的字段数据之后,就可以按照指定的字段进行排序,也就是
ORDER BY 阶段,得到虚拟表vt6。最后在 vt6 的基础上,取出指定行的记录,也就是
LIMIT 阶段,得到最终的结果,对应的是虚拟表vt7。当然我们在写 SELECT 语句的时候,不一定存在所有的关键字,相应的阶段就会省略。
同时因为 SQL 是一门类似英语的结构化查询语言,所以我们在写 SELECT 语句的时候,还要注意相应的关键字顺序,所谓底层运行的原理,就是我们刚才讲到的执行顺序。
写不下了重开一个
边栏推荐
- 比特,比特,字節,字的概念與區別
- Meyer Burger梅耶博格西门子工控机维修及机床养护
- H1 -- HDMI interface test application 2022-07-15
- Visual studio 2022 interesting and powerful intelligent auxiliary coding
- Understand asp Net core - Cookie based authentication
- [information system project manager] Chapter VI recheck schedule management knowledge structure
- Linux: database connection
- 华为高层谈 35 岁危机,程序员如何破年龄之忧?
- C1--Vivado配置VS Code文本编辑器环境2022-07-21
- C EventHandler observer mode
猜你喜欢
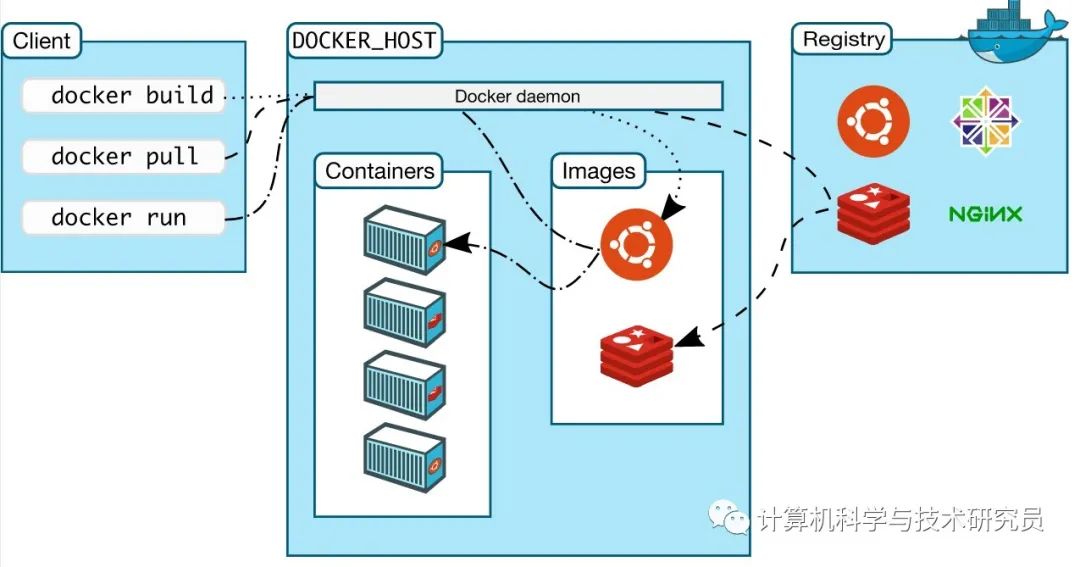
Kubernetes technology and Architecture (VI)

Activiti工作流使用之Activiti-app的安装及流程创建
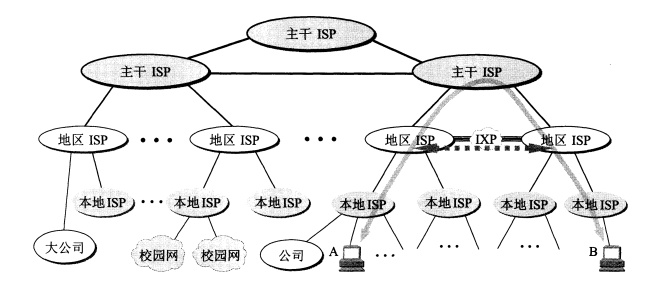
Chapter 1 Overview - Section 1 - 1.2 overview of the Internet
![[visual slam] orb slam: tracking and mapping recognizable features](/img/bb/d6a99bb1bff6bbe1f781e567cc1176.png)
[visual slam] orb slam: tracking and mapping recognizable features

C语言n番战--结构体(七)
开发必备之Idea使用

Pytorch (V) -- pytorch advanced training skills

简述redis特点及其应用场景

IO should know and should know

Alibaba cloud object storage service OSS front and rear joint debugging
随机推荐
Data Lake: introduction to delta Lake
Redis source code and design analysis -- 14. Database implementation
达人专栏 | 还不会用 Apache Dolphinscheduler?大佬用时一个月写出的最全入门教程
对比redis的RDB、AOF模式的优缺点
7、纹理映射
部署metersphere
PXE remote installation and kickstart unattended installation technical documents
8. Surface geometry
Mysql database foundation
An analysis of the CPU explosion of an intelligent transportation background service in.Net
3DMAX first skin brush weights, then attach merge
排序
C语言n番战--共用体和枚举(八)
H1 -- HDMI interface test application 2022-07-15
又更新了, IDEA 2022.2 正式发布
【信息系统项目管理师】第六章 复盘进度管理知识架构
Optimization Net application CPU and memory 11 practices
Redis源码与设计剖析 -- 9.字符串对象
Wechat applet package wx.request
数据库进程卡住解决