当前位置:网站首页>Squeeze and incentive networks
Squeeze and incentive networks
2022-07-23 16:48:00 【TJMtaotao】
Squeeze-and-Excitation Networks
ie Hu[0000−0002−5150−1003]
Li Shen[0000−0002−2283−4976]
Samuel Albanie[0000−0001−9736−5134]
Gang Sun[0000−0001−6913−6799]
Enhua Wu[0000−0002−2174−1428]
Abstract Convolutional neural networks (CNNs) The core building block of is the convolution operator , It enables the network to construct information features by fusing the spatial and channel information in the local receptive field of each layer . Previous extensive studies have investigated the spatial components of this relationship , We try to improve the spatial coding quality of the whole feature level to enhance CNN Expressive force . In this work , We will focus on Channel relations On , A new architecture unit is proposed , We call it “ Squeeze and excite ”(SE) block , It passes through Explicitly model the interdependencies between channels , Adaptively recalibrate the channel characteristic response . We show that , These blocks can Stacked together to form SENet Architecture , Generalize very effectively on different data sets . We further prove that ,SE Block in Slightly increase the calculation cost Under the circumstances , remarkable Improved the existing latest cnn Performance of . Compressing and motivating networks is what we ILVRC 2017 Basis of classified submission , It won the first place , And the former 5 Bit errors are reduced to 2.251%, More than the 2016 Winning entries for , Relatively improved 25%.
key word : Squeeze and excite , The image shows , Be careful , Convolutional neural networks .
1 INTRODUCTION
Evolutionary neural networks (CNNs) It has proved to be a useful model for dealing with various visual tasks [1]、[2]、[3]、[4]. Each convolution layer in the network , The filter set represents the neighborhood spatial connection pattern along the input channel , The spatial and channel information are fused together in the local receiving field . By interleaving a series of convolution layers with nonlinear activation function and down sampling operator ,CNNs Can produce image representation , Thus, the hierarchical pattern is captured and the global theoretical receiving field is obtained . A central theme of computer vision research is to find more powerful forms of expression , These representations capture only those attributes in the image that are most significant for a given task , To improve performance . As a widely used visual task model family , The development of new neural network architecture design is a key frontier of this research . Recent research shows that , By integrating learning mechanisms into networks that help capture spatial correlations between features ,CNNs The generated representation can be enhanced . One of them consists of Inception Series architecture [5]、[6] Methods of generalization , Integrate the multi-scale process into the network module , To achieve improved performance . Further work seeks better model space dependence [7],[8], And bring spatial attention into the structure of the network [9].
In this paper , We studied another aspect of network design —— The relationship between channels . We introduced a new architecture unit , We call it squeezing and motivating (SE) block , The purpose is to improve the representation quality of the network by explicitly modeling the interdependence between the channels with convolution characteristics . So , We propose a mechanism that allows the network to perform feature recalibration , Through this mechanism , Networks can learn to use global information to selectively emphasize informative features , And suppress less useful features .
SE The structure of the building block is shown in the figure 1 Shown . For, enter X Mapping to U∈RH×W×C Feature mapping of U Any given transformation of , For example, convolution , We can construct the corresponding SE Block to perform feature recalibration . features U First, through the extrusion operation , The squash operation gathers its spatial dimensions (H×W) Generate channel descriptors by feature mapping on . The function of the descriptor is to generate the embedding function of the global distribution of the channel characteristic response , Allow information from the global receiving field of the network to be used by all its layers . Aggregation is followed by an incentive operation , It takes the form of a simple self gating mechanism , The mechanism takes embedding as input , And generate a set of modulation weights for each channel . These weights are applied to feature mapping U To generate SE Block output ,SE The output of the block can be directly fed into the subsequent layer of the network .
By simply superimposing SE Block set , Can construct SE The Internet (SENet). Besides , these SE The block can also be used as a substitute for the original block within a certain depth of the network arch itecarXiv:1709.01507v4 Number [ resume ]2019 year 5 month 16 Japan 2 chart 1. Squeeze and excite blocks . Really? ( The first 6.4 section ). Although the templates for building blocks are generic , But it performs different roles at different depths throughout the network . In the early layers , It stimulates information properties in a class agnostic way , Enhanced low-level representation of sharing . In subsequent layers ,SE Blocks are becoming more and more specialized , And respond to different inputs in a highly class specific manner ( The first 7.2 section ). therefore ,SE The benefits of feature recalibration performed by the block can be accumulated through the network .
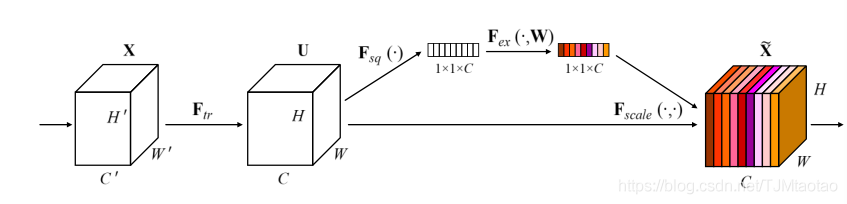
chart 1. Squeeze and excite blocks .
Design and develop new CNN Architecture is a difficult engineering task , You usually need to choose many new super parameters and layer configurations . by comparison ,SE The structure of the block is simple , It can be directly used in the most advanced existing architecture , use SE Block replacement component , So as to effectively improve the performance .SE Blocks are also computationally lightweight , It will only slightly increase the complexity and computational burden of the model .
In order to provide evidence for these statements , We have developed several senet, Also on ImageNet Data sets were extensively evaluated [10]. We also showed ImageNet Other than the results , These results show that the benefits of our approach are not limited to specific data sets or tasks . By using SENets, We are ILSVRC 2017 Ranked first in the classification competition . Our best test set 1 Up to 2.251% Before 5 A mistake . Compared with the winner of the previous year ( front 5 The error of the name is 2.991%), This means a relative improvement 25%.
2 RELATED WORK
Deeper Architecture .VGGNets[11] and Inception Model [5] indicate , Increasing the depth of the network can significantly improve the representation quality of the network . By adjusting the distribution of input to each layer , Batch normalization (BN)[6] It increases the stability of the learning process in the deep network , And produce a smoother optimized surface [12]. On the basis of these work ,ResNets It proves that we can learn more deeply by using identity based skip connection 、 Stronger networks are possible [13],[14]. Road network [15] A gating mechanism is introduced , To adjust the information flow along the shortcut connection . After all this work , The connection between network layers is further restated [16]、[17]、1.http://image-net.org/challenges/LSVRC/2017/results This website shows promising improvements in the learning and representation characteristics of deep networks .
Another closely related research direction is to improve the functional form of computing elements in the network . Block convolution has proved to be a popular method to increase the learned transform cardinality [18],[19]. Multi branch convolution [5]、[6]、[20]、[21] It can realize more flexible operator combination , This can be seen as a natural extension of the grouping operator . In previous work , Cross channel correlation is usually mapped into new feature combinations , Independent of spatial structure [22]、[23] Or through the use of 1×1 Standard convolution filter for convolution [24] To unite . Most of these studies focus on the goal of reducing model and computational complexity , Reflects a hypothesis , That is, the channel relationship can be expressed as a combination of instance unknowable functions with local receiving fields . On the contrary , We believe that providing a mechanism , Global information is used to explicitly model the dynamics between channels 、 Nonlinear dependence , It can simplify the learning process , Significantly enhance the presentation ability of the network .
Algorithm architecture search . In addition to the above work , There is also a rich research history , Designed to abandon manual architectural design , But looking for automatic learning network structure . Most of the early work in this field was carried out in the field of neuroevolution , They established a method of searching network topology by evolutionary method [25],[26]. Although calculation is usually required , But evolutionary search has achieved remarkable success , These include the sequence model [27]、[28] Find a good storage unit , And learn the complex architecture for large-scale image classification [29]、[30]、[31]. In order to reduce the computational burden of these methods , be based on Lamarckian Inherit [32] And microstructure search [33] An effective alternative to this method is proposed
By defining schema search as hyperparametric optimization , Random search [34] And other more complex model-based optimization techniques [35],[36] It can also be used to solve this problem . Topology selection as a path through the structure of possible design [37] And direct architecture prediction [38],[39] It is proposed as an additional feasible architecture search tool . Through intensive learning [40]、[41]、[42]、[43]、[44] The technique in , Achieved particularly remarkable results .SE block 3 It can be used as an atomic building block for these search algorithms , And proved to be efficient in concurrent work .
Attention and gating mechanism . Note that it can be interpreted as a method of favoring the allocation of available computing resources to the most informative part of the signal [46]、[47]、[48]、[49]、[50]、[51]. Attention mechanisms have proven their usefulness in many tasks , Learning sequence includes [52],[53],[9],[54],[55],[56] Lip reading [57]. In these applications , It can be combined into one operator , Follow one or more layers , These layers represent a higher level of abstraction for adaptation between patterns . Some works have conducted interesting research on the combination of spatial attention and channel attention [58],[59].Wang wait forsomeone .[58] An hourglass based module is introduced [8] Powerful backbone and mask attention mechanism , The mechanism is inserted between the intermediate stages of the deep residual network . by comparison , What we proposed SE The block contains a lightweight gating mechanism , This mechanism models the channel relationship in a computationally efficient way , Focus on enhancing the presentation ability of the network .
3 SQUEEZE-AND-EXCITATION BLOCKS
The compression and excitation block is a computing unit , It can be built on inputting X∈RH0×W0×C0 Mapping to feature mapping U∈RH×W×C On the transformation of . In the following symbol , We will Ftrto As a convolution operator , And use V=[v1,v2.,vC] Represents the learned filter kernel set , among vC It means the first one c The parameters of a filter . Then we can write the output as U=[u1,u2.,uC), among

here * For convolution ,vc=[v1 c,v2c.,vC0 c),X=[x1,x2.,xC0] and uc∈RH×W.vs-cis A two-dimensional space kernel , Act on X On the corresponding channel of vc A single channel . To simplify the representation , The offset term is omitted . Because the output is generated by the sum of all channels , Channel dependence is implicitly embedded in vc in , But it is entangled with the local spatial correlation captured by the filter . The channel relation of convolution modeling is implicit and local in nature ( Except for the top ). We expect to enhance the learning of convolution features by explicitly modeling channel correlation , Thus, the network can increase the sensitivity to information features , These information features can be used through subsequent transformation . therefore , We want to input the filter response into the next transform , It provides global information access and recalibrates the filter response through two steps: squeezing and excitation . chart 1 Shows SE A diagram of the structure of a block .
3.1 Compress : Global information embedding is to solve the problem of using channel correlation , We first consider the signal of each channel in the output characteristics . Each learned filter uses a local receiver field , So convert the output U Each unit of cannot take advantage of context information outside the region .
To alleviate this problem , We propose to compress the global spatial information into the channel descriptor . This is achieved by using the global average pool to generate channel statistics . Formally , A statistic z∈RCis from U Through its spatial dimension H×W Shrink to produce , bring z Of the c The elements are calculated as follows :

Discuss . transformation U The output of can be interpreted as a collection of local descriptors , The statistics of these descriptors represent the whole image . Using this information is very popular in previous feature engineering work [60]、[61]、[62]. We chose the simplest aggregation technology global average pooling, Note that more complex strategies can also be used here .
3.2 incentive : Adaptive recalibration
In order to take advantage of the information gathered in the compression operation , We use the second operation to track it , This operation is intended to fully capture channel dependencies . In order to achieve this goal , This function must meet two criteria : First of all , It has to be flexible ( especially , It must be able to learn the nonlinear interaction between channels ); second , It must learn non mutually exclusive relationships , Because we want to ensure that we allow emphasis on multiple channels ( Instead of forcing a hot start ). To meet these standards , We choose to adopt a simple gating mechanism , sigmoid function :
![]() among δ Refer to ReLU[63] function ,W1∈R C R×C and W2∈R C×crr. In order to limit the complexity of the model and help promote , By forming two complete connections around the nonlinearity (FC) Layer bottleneck to parameterize the gate mechanism ,i、 e. With dimensionality reduction ratio r Dimensionality reduction layer ( The selection of this parameter is shown in 6.1 Section discusses )、ReLU, Then return to the transform output U Dimensionality reduction layer of channel size . Rescale by using activation U Get the final output of the block :
among δ Refer to ReLU[63] function ,W1∈R C R×C and W2∈R C×crr. In order to limit the complexity of the model and help promote , By forming two complete connections around the nonlinearity (FC) Layer bottleneck to parameterize the gate mechanism ,i、 e. With dimensionality reduction ratio r Dimensionality reduction layer ( The selection of this parameter is shown in 6.1 Section discusses )、ReLU, Then return to the transform output U Dimensionality reduction layer of channel size . Rescale by using activation U Get the final output of the block :
![]()
In style ,ex=[e x1,e x2.,e xC] and Fscale(uc,sc) Channel multiplication b
Discuss . The excitation operator will be specific to the input descriptor z Map to a set of channel weights . In this regard ,SE The block essentially introduces the dynamics based on input , This can be seen as a self attention function on the channel , The relationship is not limited to the local receptive field of the convolution filter response .

3.3 example
SE Blocks can be integrated into the standard architecture by nonlinear insertion after each convolution , example Such as VGGNet[11]. Besides ,SE The flexibility of the block means that it can be directly applied to transformations other than standard convolution . To illustrate this point , We pass the will SE The blocks are combined into several examples of more complex architectures to develop senet, It will be described below .
We first consider the of the initial network SE Construction of blocks [5]. here , We simply convert Ftrto As a complete initial module ( See chart 2), And by making this change to each such module in the architecture , We get a SE Initial network .SE Blocks can also be used directly for the remaining networks ( chart 3 It depicts SE ResNet Module mode ). here ,SE Block conversion ftri It is considered to be the non identified branch of the remaining modules . Both squeezing and excitation work before summing with the identity Branch . take SE Block and ResNeXt[19]、Inception ResNet[21]、MobileNet[64] and ShuffleNet[65] Further variants of the integration can be constructed by following a similar scheme . about SENet Specific examples of Architecture , surface 1 given SE-ResNet-50 and SE-ResNeXt-50 Detailed description of .
SE One result of the flexibility of blocks is , There are several possible ways to integrate it into these architectures . therefore , In order to evaluate the use of SE The sensitivity of the integration strategy of merging blocks into the network architecture , We also provide ablation experiments , Explore the second 6.5 The blocks in this section contain different designs .
In order to make the proposed SE Block design has practical application value , It must provide a good compromise between improved performance and increased model complexity . To illustrate the computational burden associated with this module , We use ResNet-50 and SE-ResNet-50 Take the comparison between .ResNet-50 about 224×224 Pixel input image , In a forward process, you need 3.86 GFLOPs, Extrusion stage FC The layer is in the excitation phase , Then there is a cheap channel scaling operation . in general , When the reduction rate r( See the first 3.2 section ) Set to 16 when ,SE-ResNet-50 need 3.87 GFLOPs, Relatively primitive ResNet-50 increase 0.26%. In exchange for this small additional computational burden ,SE-ResNet-50 The accuracy of exceeds ResNet-50, And actually close to the need 7.58 GFLOPs Deeper ResNet-101 The accuracy of the network ( surface 2).
actually , Pass forward and backward ResNet-50 need 190 ms, and SE-ResNet-50 You need to 209 ms, Train small batches 256 Images ( Both timings are performed on one server , There is... On the server 8 individual NVIDIA Titan X gpu). We suggest that this represents a reasonable runtime overhead , With the popularity of GPU The global pool and small internal product operations in the library are further optimized , This overhead may be further reduced . Because of its importance in embedded device application , We further study each model CPU Extrapolate time for benchmarking : about 224×224 Pixel input image ,ResNet-50 need 164ms, and SE-ResNet-50 need 167ms. We think ,SE The contribution of blocks to model performance proves SE The small amount of additional computational cost generated by the block is reasonable .
Next, let's consider the proposed SE Additional parameters introduced by the block . These additional parameters are determined by only two of the gating mechanisms FC Layers produce , Therefore, it constitutes a small part of the total network capacity . To be specific , these FC The total number of weight parameters introduced by the layer is given by the following formula :

among r Represents the reduction rate ,S Represent series ( Series refers to the set of blocks operating on the feature mapping of the common space dimension ),Cs Represents the dimension of the output channel ,Ns Represent series S Number of duplicate blocks ( When in FC When using offset terms in layers , The introduced parameters and computational costs are usually negligible ).SE-ResNet-50 stay
∼ResNet-50 need 2500 All the parameters , Corresponding to ∼10% The growth of . actually , Most of these parameters come from the final stage of the network , In the final stage of the network , The excitation operation is performed on the maximum number of channels . However , We found that , This relatively expensive SE The final stage of the block can be achieved at only a small performance cost (ImageNet Preceding 5 The bit error is less than 0.1%) To remove , Thus, the increase of relative parameters is reduced to 4%, This may prove useful when parameter use is a key consideration ( For further discussion , Please refer to No 6.4 Section and section 7.2 section ).
primary ResNeXt-101[19] use ResNet-152[13] Block stacking strategy . With the design and training of this model ( Don't use SE block ) The further differences are as follows :(a) The front of each bottleneck building block 1×1 The number of convolution channels is halved , In order to reduce the computational cost of the model with the minimum performance reduction .(b) The first one. 7×7 The convolution layer is replaced by three consecutive 3×3 Convolution layer .(c) use 3×3 step -2 Convolution instead of step size -2 Convolution 1×1 Down sampling projection to save information .(d) Insert a shedding layer before the classification layer ( The shedding ratio is 0.2), To reduce over fitting .(e) Used... During training Labelsmoothing Regularization ( Such as [20] Introduced in ).(f) Freeze all... During the last few training sessions BN Parameters of the layer , To ensure the consistency of training and testing .(g) Use 8 Servers (64 GPU) Perform training in parallel , To achieve mass production (2048). The initial learning rate is set to 1.0.
import torch.nn as nn
class SELayer(nn.Module):
def __init__(self, channel, reduction=16):
super(SELayer, self).__init__()
self.avgpool = nn.AdaptiveAvgPool2d(1)
self.fc = nn.Sequential(
nn.Linear(channel, channel//reduction,bias=False),
nn.ReLU(inplace=True),
nn.Linear(channel//reduction,channel, bias=False),
nn.Sigmoid()
)
def forward(self, x):
b,c,h,w = x.size()
y = self.avgpool(x).view(b,c)
y = self.fc(y).view(b,c,1,1)
return x * y.expand_as(x)
边栏推荐
- Numpy 数据分析基础知识第一阶段(NumPy基础)
- fastadmin,非超级管理员,已赋予批量更新权限,仍显示无权限
- 机器狗背冲锋枪射击视频火了,网友瑟瑟发抖:stooooooooppppp!
- The protection circuit of IO port inside the single chip microcomputer and the electrical characteristics of IO port, and why is there a resistor in series between IO ports with different voltages?
- 使用“soup.h1.text”爬虫提取标题会多一个\
- Niuke-top101-bm36
- SQL156 各个视频的平均完播率
- pytest接口自动化测试框架 | 多进程运行用例
- mysql多表查询之_笛卡尔乘积_内连接_隐式连接
- How to choose fluorescent dyes in laser confocal
猜你喜欢
卷积神经网络模型之——GoogLeNet网络结构与代码实现

Tan Zhangxi, director of risc-v Foundation: risc-v has gradually expanded from the edge to the center

Cuibaoqiu, vice president of Xiaomi group: open source is the best platform and model for human technological progress

聊一聊JVM的内存布局
Liupeng, vice president of copu: China's open source has approached or reached the world's advanced level in some areas

20220722挨揍记录

TS encapsulates the localstorage class to store information

千万别让富坚义博看到这个

【笔记】线性回归

Scale Match for Tiny Person Detection
随机推荐
软件体系结构
Une solution complète au problème du sac à dos dans la programmation dynamique
20220722 beaten record
16 automated test interview questions and answers
AWS 6 AWS IOT
国产AI蛋白质结构预测再现突破,用单条序列解决3D结构,彭健团队:“AlphaFold2以来最后一块拼图补齐了”...
Stm32f103+rfid-rc522 module realizes simple card reading and writing demo "recommended collection"
The working principle of PLL. For example, how can our 8MHz crystal oscillator make MCU work at 48mhz or 72mhz
距离IoU损失:包围盒回归更快更好的学习(Distance-IoU Loss: Faster and Better Learning for Bounding Box Regression)
MySQL中几种常见的 SQL 错误用法
Frequently asked questions about MySQL
15001. System design scheme
946. Verify stack sequence ●● & sword finger offer 31. stack push in and pop-up sequence ●●
UiPath Studio Enterprise 22.4 Crack
Why does fatal always appear when using opengaussjdbc? (tag database keyword user)
Circuit structure and output mode of GPIO port of 32-bit single chip microcomputer
Surface family purchase reference
go run,go build,go install有什么不同
僧多粥少?程序员要怎样接私活才能有效提高收入?
15001.系统设计方案