当前位置:网站首页>Aof persistence
Aof persistence
2022-06-13 00:44:00 【Let me ride】
AOF Persistence
One 、Redis Persistence
When Rides When the process is shut down , We can recover data through persistence .
Redis Although it is a memory database , however Redis In fact, it saves the cached data to the hard disk , As long as the file storing the cached data is not lost , Cached data can be recovered naturally .
Rdedis There are two persistence technologies , Namely AOF Journal and RDB snapshot
Redis On by default RDB snapshot , therefore Redis Restart the , The previously cached data will be reloaded .
Two 、AOF journal
Just imagine , If Redis Every write command is executed , Write the command to a file by appending , And then restart Redis When , Read the command in this file first , And execute it , This is equivalent to restoring the cached data ?
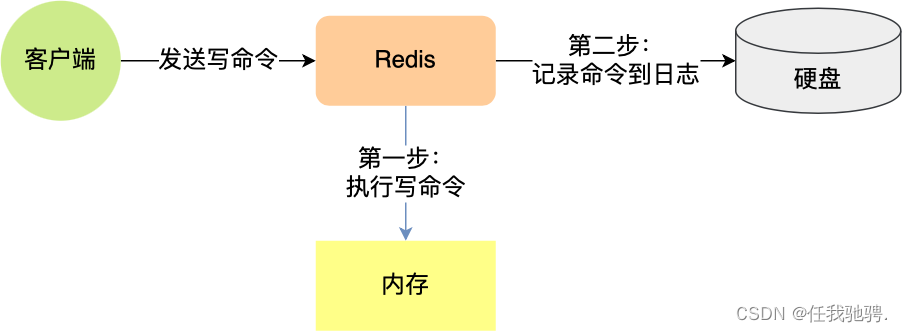
This persistent way of saving write commands to logs , Namely Redis Inside AOF Persistence function , Note that only write commands are recorded , Read commands are not recorded , Because it doesn't make sense .
stay Redis in AOF Persistence is not enabled by default , We need to modify redis.conf The following parameters in the configuration file :
AOF Log files are just plain text , We can go through cat Command to see what's inside , But if you don't know some rules about the contents , You may not understand .
Here I am. 「set name xiaolin」 Command as an example ,Redis After executing this command , Recorded in the AOF The content of the log is as follows :
「*3」 Indicates that the current command has three parts , Every part is based on 「$+ Numbers 」 start , Followed by specific orders 、 Key or value . then , there 「 Numbers 」 Indicates the command in this part 、 How many bytes are there in the key or value . for example ,「$3 set」 This part has 3 Bytes , That is to say 「set」 Command the length of this string .
Redis First execute the write command and then , To record the command to AOF In the Journal , There are actually two advantages to doing so .
The first benefit , Avoid extra inspection overhead .
Because if you record the write command to AOF In the Journal , If you execute that command again , If there is a problem with the current command syntax , So if you don't check the command syntax , The wrong command was recorded to AOF In the Journal ,Redis When using logs to recover data , Could go wrong .
And if the write command is executed first and then the log is recorded , Only after the command is successfully executed , Just recorded the command to AOF In the Journal , So there's no extra inspection overhead , Make sure it's recorded in AOF The commands in the log are executable and correct .
The second advantage , Does not block the execution of the current write command , Because when the write command is executed successfully , Will record the command to AOF journal .
Of course ,AOF Persistence is not without potential risks .
The first risk , Executing the write command and logging are two processes , That's right Redis Before I can write the command to the hard disk , The server is down , This data will be available Risk of loss .
The second risk , Said before , Because the write operation command is not recorded until it is executed successfully AOF journal , So it doesn't block the execution of the current write command , however May give 「 next 」 Command carries the risk of blocking .
Because the operation of writing the command to the log is also completed in the main process ( Executing commands is also in the main process ), That is to say, the two operations are synchronous .

If the log content is written to the hard disk , The hard disk of the server I/O Too much pressure , It will cause the speed of hard disk writing to be very slow , And it blocks , It will also result in subsequent commands not being executed .
Seriously analyze , In fact, these two risks have one thing in common , All follow 「 AOF When to write the log back to the hard disk 」 of .
3、 ... and 、 Three writeback strategies

- Redis After executing the write command , Will append the command to server.aof_buf buffer ;
- And then through write() system call , take aof_buf The data in the buffer is written to AOF file , At this time, the data is not written to the hard disk , It's copied to the kernel buffer page cache, Wait for the kernel to write data to the hard disk ;
- When will the data in the kernel buffer be written to the hard disk , It's up to the kernel .
Redis Provides 3 A write back strategy , Control is the process of the third step mentioned above .
stay redis.conf In the configuration file appendfsync Configuration items can have the following 3 Parameters can be filled in :
Always, This word means 「 Always 」, So it means that every time the write command is executed , Synchronization will AOF Log data is written back to the hard disk ;
Everysec, This word means 「 Per second 」, So it means that every time the write command is executed , First write the command to AOF The kernel buffer of the file , Then write the buffer back to the hard disk every second ;
No, It means not to Redis Control when to write back to the hard disk , Turn it over to the operating system to control when to write back , That is, after each write operation command is executed , First write the command to AOF The kernel buffer of the file , It's up to the operating system to decide when to write the buffer back to the hard disk .
this 3 None of the write back strategies can solve the problem perfectly 「 Main process blocking 」 and 「 Reduce data loss 」 The problem of , Because the two problems are opposite , To one side , You have to sacrifice the other side , Here's why :
Always In terms of strategy , It can ensure that the data is not lost to the greatest extent , But because it synchronizes every write command AOF The content is written back to the hard disk , So it will inevitably affect the performance of the main process ;
No In terms of strategy , It's up to the operating system to decide when AOF The log content is written back to the hard disk , Compared with Always The strategy has good performance , But the timing when the operating system writes back to the hard disk is unpredictable , If AOF The contents of the log are not written back to the hard disk , Once the server goes down , You lose a lot of data .
Everysec In terms of strategy , It's a way to compromise , Avoided Always The performance overhead of the policy , Is better than No Policies are better for avoiding data loss , Of course, if the last second's write command log is not written back to the hard disk , There was a crash , This second of data will naturally be lost .
We choose according to our own business scenarios :
How do these three strategies work ?
After going deep into the source code , You'll find that these three strategies are just controlling fsync() When to call a function .
When an application writes data to a file , The kernel usually copies the data to the kernel buffer first , And then it's queued , Then it's up to the kernel to decide when to write to the hard disk .

If you want the application to write data to the file , Can instantly synchronize data to the hard disk , You can call fsync() function , In this way, the kernel will write the data in the kernel buffer directly to the hard disk , Wait until the hard disk write is complete , This function will return .
Always The strategy is to write every time AOF After the file data , Is executed fsync() function ;
Everysec The policy creates an asynchronous task to execute fsync() function ;
No The strategy is never to execute fsync() function ;
Four 、AOF Rewrite mechanism
AOF A log is a file , As more and more write commands are executed , The size of the file will get bigger and bigger .
If so AOF Log files that are too large can cause performance problems , For example, restart Redis after , Need to read AOF The contents of the file to recover the data , If the file is too large , The whole recovery process will be slow .
therefore ,Redis for fear of AOF The bigger the file, the bigger it gets , Provides AOF Rewrite mechanism , When AOF After the size of the file exceeds the set threshold ,Redis It will activate AOF Rewrite mechanism , To compress AOF file .
AOF The rewriting mechanism is when rewriting , Read all key value pairs in the current database , Then record each key value pair with a command to 「 new AOF file 」, When all the records are finished , It's going to be new AOF The file replaces the existing AOF file .
for instance , Before using the rewriting mechanism , Suppose that before and after the execution of 「set name xiaolin」 and 「set name xiaolincoding」 These two orders , These two commands will be recorded to AOF file .

however After using the rewriting mechanism , It will read name Abreast of the times value( Key value pair ) , And then use one 「set name xiaolincoding」 The command logs to a new AOF file , There is no need to record the first order before , Because it belongs to 「 history 」 command , It doesn't work . thus , A key value pair in the rewrite log uses only one command .
When the rewriting is done , It will bring new AOF The file covers the existing AOF file , This is equivalent to compression AOF file , bring AOF The size of the file is smaller .
then , Through AOF Log recovery data , Just execute this command , You can write the key value pair directly .
therefore , The beauty of rewriting is , Although a key value pair is repeatedly modified by multiple write commands , In the end, it just needs to be based on this 「 Key value pair 」 The current state of the art , Then record the key value pairs with a command , Instead of recording multiple commands of this key value pair , This reduces AOF The number of commands in the file . Finally, after the rewriting is done , New AOF The file covers the existing AOF file .
Here's why rewrite AOF When , Don't reuse the existing AOF file , It's about writing something new first AOF The file then covers the past .
because If AOF The rewriting process failed , The existing AOF Documents can cause pollution , May not be used for recovery .
therefore AOF Rewrite process , Rewrite to a new one first AOF file , If rewriting fails , Just delete this file , Not for the existing AOF File impact .
5、 ... and 、AOF Backstage rewrite
write in AOF Although the log operation is completed in the main process , Because it doesn't write much , So it doesn't affect the operation of the command .
But it's triggering AOF When rewriting , For example, when AOF File is larger than 64M when , Would be right. AOF File rewriting , At this time, you need to read all the cached key value pairs , And generate a command for each key value pair , Then write it to the new AOF file , After rewriting , Let's take the present AOF File replacement .
This process is actually time-consuming , So the overridden operation cannot be placed in the main process .
therefore ,Redis Of rewrite AOF The process is a backstage process bgrewriteaof To complete , There are two benefits to this :
- The subprocess goes on AOF During rewrite , The main process can continue to process command requests , This avoids blocking the main process ;
- The child process has a copy of the master process's data ( How does the data copy come into being ), Here we use child processes instead of threads , Because if you use threads , Multithreads share memory , So when modifying shared memory data , Need to lock to ensure the security of data , And that reduces performance . And using child processes , When creating a subprocess , Parent child processes share memory data , But this shared memory can only be read-only , When either of the parent-child processes modifies the shared memory , It will happen 「 When writing copy 」, So the parent-child process has a separate copy of the data , You don't have to lock to keep your data safe .

Copy while writing as the name suggests , When a write occurs , The operating system will copy the physical memory , This is to prevent fork When creating a subprocess , Due to the long replication time of physical memory data, the parent process is blocked for a long time .
Of course , When the operating system copies the page table of the parent process , The parent process is also blocking , However, the size of the page table is much smaller than the actual physical memory , So the process of copying page tables is usually faster .
however , If the memory data of the parent process is very large , The natural page table will also be large , At this point, the parent process is passing through fork When creating a subprocess , The longer it gets stuck .
therefore , There are two phases that cause the parent process to block :
- On the way to creating a child process , Because we want to copy the page table and other data structure of the parent process , The blocking time depends on the size of the page table , The larger the page table is , And the longer it gets blocked ;
- After creating a subprocess , If the child process or parent process modifies the shared data , Copy on write happens , In the meantime, physical memory will be copied , If you have more memory , The longer the natural blockage is ;
After triggering the rewriting mechanism , The main process creates an override AOF Can be inherited by child processes. , At this point, the parent-child process shares physical memory , Rewriting the child process will only read the memory , rewrite AOF The child process will read all the data in the database , The key value pairs of memory data are converted into a command one by one , Record the command to the rewrite log ( new AOF file ).
But in the process of subprocess rewriting , The main process can still handle commands normally .
If at this time The main process has been modified. It already exists key-value, Copy on write happens , Note that only the physical memory data modified by the main process will be copied here , The physical memory is shared with the child process without modification .
So if this stage changes a bigkey, That is, there is a large amount of data key-value When , At this time, the process of copying physical memory data will be time-consuming , There is a risk of blocking the main process .
One more question , rewrite AOF In the process of logging , If the main process is modified, it already exists key-value, At this point key-value The data in the memory of the child process is inconsistent with that of the main process , What should I do at this time ?
To solve this data inconsistency problem ,Redis Set up a AOF Rewrite buffer , This buffer is being created bgrewriteaof Start using after the child process
In rewriting AOF period , When Redis After executing a write command , It will At the same time, write the write command to 「AOF buffer 」 and 「AOF Rewrite buffer 」.

in other words , stay bgrewriteaof Subprocesses execute AOF During rewrite , The main process needs to perform the following three tasks :
- Execute the command from the client ;
- Append the executed write command to 「AOF buffer 」;
- Append the executed write command to 「AOF Rewrite buffer 」;
When the subprocess is finished AOF Rewrite work ( Scan all the data in the database , Convert the key value pairs of memory data into a command one by one , Record the command to the rewrite log ) after , Will send a signal to the main process , Signaling is a way of communication between processes , And it's asynchronous .
After the main process receives the signal , Will call a signal processing function , This function mainly does the following work :
- take AOF Everything in the rewrite buffer is appended to the new AOF In the file of , Make the old and the new AOF The database state saved by the file is consistent ;
- new AOF Change the name of the file , Cover the existing AOF file .
After the signal function is executed , The main process can continue to process commands as usual .
Throughout AOF In the background rewrite process , In addition to write time replication blocking the main process , In addition, the execution of signal processing functions will block the main process , At other times ,AOF Background rewriting does not block the main process .
6、 ... and 、 summary
Redis There are three ways to AOF The strategy of log writing back to hard disk , Namely Always、Everysec and No, These three strategies are from high to low in reliability , And in terms of performance, it goes from low to high .
As more commands are executed ,AOF The size of the file will naturally become larger and larger , To avoid the log file being too large , Redis Provides AOF Rewrite mechanism , It directly scans all the key value pairs in the data , Then a write command is generated for each key value pair , Then write the command to the new AOF file , After rewriting , Just replace the existing AOF journal . The process of rewriting is done by the backend subprocess , This allows the main process to continue to process commands normally .
use AOF It's very slow to recover data by logging , because Redis Executing commands is the responsibility of a single thread , and AOF The way log recovers data is to execute each command in the log in sequence , If AOF The log is very big , This 「 replay 」 The process will be very slow .
边栏推荐
- 1. Google grpc framework source code analysis Hello World
- Hard (magnetic) disk (I)
- What are the conditions of index invalidation?
- [LeetCode]14. Longest common prefix thirty-eight
- New blog address
- ROS从入门到精通(零) 教程导读
- Kotlin 协程的四种启动模式
- 6.824 Lab 3A: Fault-tolerant Key/Value Service
- Win10 home vs pro vs enterprise vs enterprise LTSC
- Go custom collation
猜你喜欢

Penetration test summary

How to solve the duplication problem when MySQL inserts data in batches?

People and gods are angry. Details of Tangshan "mass beating of women incident"

从ADK的WinPE自己手动构建自己的PE

Druid reports an error connection holder is null

牌好不好无法预料

Win10 home vs pro vs enterprise vs enterprise LTSC

antdPro - ProTable 实现两个选择框联动效果

Aunt learning code sequel: ability to sling a large number of programmers
![[vscode]todo tree a to-do plug-in](/img/52/c977bc9cd021ca6fd12bcc22ae9f78.jpg)
[vscode]todo tree a to-do plug-in
随机推荐
Kali system -- host, dig, dnsenum, imtry for DNS collection and analysis
睡前小故事之MySQL起源
深度学习训练多少轮?迭代多少次?
MySQL query table field information
ImportError: cannot import name 'get_ora_doc' from partially initialized module
Packaging and uplink of btcd transaction process (III)
Using fastjson to solve the problem of returning an empty array from a null value of a field string object
BUUCTF之BabySQL[极客大挑战 2019]
Composite key relationships using Sqlalchemy - relationships on composite keys using Sqlalchemy
DNS attack surface analysis
[vscode]todo tree a to-do plug-in
JPA execution failed in scheduled task -executing an update/delete query transactionrequiredexception
Handling method of wrong heading of VAT special invoice
Download nail live playback through packet capturing
[CISCN2019 华北赛区 Day2 Web1]Hack World --BUUCTF
What are the conditions of index invalidation?
The origin of MySQL in bedtime stories
人神共愤,唐山“群殴女性事件”细节...
Browser console injection JS
Delphi Chinese digit to Arabic digit