当前位置:网站首页>A method of using tree LSTM reinforcement learning for connection sequence selection
A method of using tree LSTM reinforcement learning for connection sequence selection
2022-07-04 19:04:00 【Inspur Yunxi database】
【 Reading guide 】
This blog is about 2020 Published by Professor liguoliang of Tsinghua University in ICDE Papers on , The proposed algorithm and experimental results are introduced , And give some thoughts in combination with the actual situation .
Link to the original text :
http://dbgroup.cs.tsinghua.edu.cn/ligl/papers/icde2020-learnedjoinorder.pdf

Part 1 - background
Connection sequence selection (Join Order Selection, JOS) One is for SQL Query to find the best connection order . As the main concern of database query optimizer, it has been widely studied for decades . It's a difficult question , Because its solution space is very large , The cost of traversing the solution space thoroughly to find the best connection order is very expensive . Traditional methods are usually based on cardinality estimation and cost model , Combined with heuristic pruning , Some pruning techniques are used to reduce the solution space of searching for possible connection order .
Despite decades of efforts , Traditional optimizers deal with complex SQL There are still problems of low scalability or low accuracy when querying . Based on Dynamic Planning (DP) Our algorithm usually chooses the best solution , But it's very expensive . Heuristics , Such as GEQO、QuickPick-1000 and GOO, Plan can be calculated faster , But it often leads to bad plans .
In recent years , Based on machine learning (ML) And deep learning (DL) Learning based optimizer (Learned Optimizer) Methods are becoming more and more popular in the database industry . Especially based on deep reinforcement learning (Deep Reinforcement Learning, DRL) Methods , Such as ReJOIN and DQ, It has shown satisfactory results —— They can generate plans as good as the native query optimizer , But the speed of execution after learning is faster than that of the native query optimizer . however , Existing based on DRL The learning optimizer of encodes the connection tree into a fixed length vector , The length of the vector is determined by the tables and columns in the database . It will lead to two problems :
1. These vectors cannot capture the structural information of the connection tree , It may cause the connection sequence to be selected to a bad plan ;
2. When the database schema changes , Such as adding columns / Table or multiple table names , This learning based optimizer will fail , This requires a new input vector of different lengths , Then retrain the neural network .
In this paper , The author proposes a new learning based optimizer RTOS, It uses reinforcement learning and tree structured short-term and long-term memory (tree-LSTM) To select the connection sequence .RTOS Based on DRL The method has been improved in two aspects :
(1) Graph neural network is used to capture the structure of connection tree ;
(2) Support the modification of database schema and multi alias table name .
stay Join Order Benchmark (JOB) and TPC-H A lot of experiments on the Internet show that ,RTOS Better than traditional optimizers and existing ones based on drl Learning optimizer .
Part 2 - Related work
DRL, Concepts related to deep reinforcement learning :
A conceptual explanation of reinforcement learning was given in an earlier blog 《Constraint-aware SQL Generation Using Reinforcement Learning》 Also mentioned in , I will not repeat it here Agent、Environment、State、Action、Reward And so on , Interested readers can also find relevant materials to deepen their understanding .
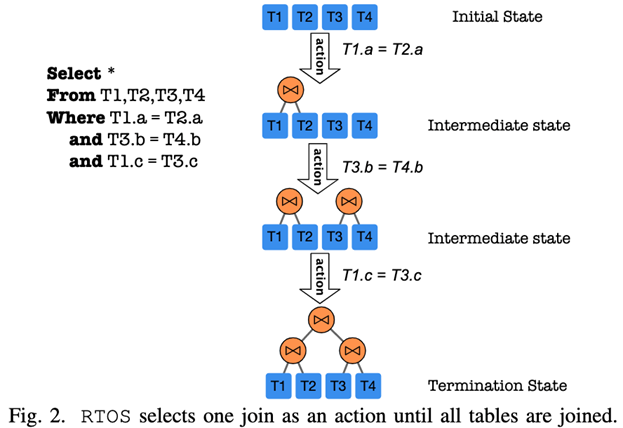
stay RTOS in Agent Corresponding optimizer , Through and with Environment( Corresponding DBMS) Learn from feedback through trial and error interaction . For the one shown in the figure SQL Query statement , As the reinforcement learning process advances, it will enter different State( Every State Corresponding to the connection plan ).RTOS Read the current plan and use Tree-LSTM To calculate the estimated long-term Reward( for example , Which table should be connected to make the current state more complete ). Then it will choose to have the largest Reward( Corresponding to the smallest Cost) The best expectation Action. When all tables are connected ( namely , Export a complete connection plan ) when , The connection plan will be sent to DBMS perform .
DQ,《Learning to Optimize Join Queries With Deep Reinforcement Learning》 Based on DRL Learning optimizer method :
DQ The connection order selection problem is abstracted as a Markov decision process .DQ Used DQN(Deep Q Network) As a reinforcement learning model to guide the selection of connection sequence , because DQN Cost estimation function in Q-function The cost of calculation is too high , So use a two-layer MLP(Multilayer Perceptron) To learn Q-function. The input of neural network is current State, It includes SQL The query information in the statement and the connection operation information represented by the state on the left and right of the connection .
REJOIN,《Deep Reinforcement Learning for Join Order Enumeration》 Based on DRL Learning optimizer method :
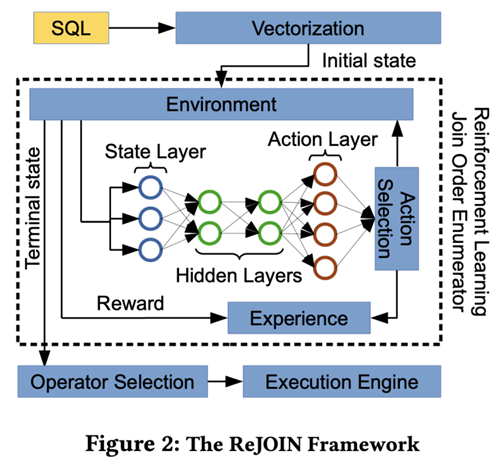
ReJOIN The neighborhood strategy optimization algorithm is mainly used (Proximal Policy Optimization) To guide the selection of connection sequence . The key component is a neural network for strategy selection . This neural network is trained by inputting vectorized state information , This information contains : Tree structure vector composed of depth information 、 Connect predicate vectors and selective predicate vectors . For different SQL Statement , There are different neural network parameters and Reward,ReJOIN According to this SQL The parameters before the statement and Reward, To estimate the future Reward, So as to achieve the SQL Statement to select the connection order .
Existing based DRL The inadequacy of the method :
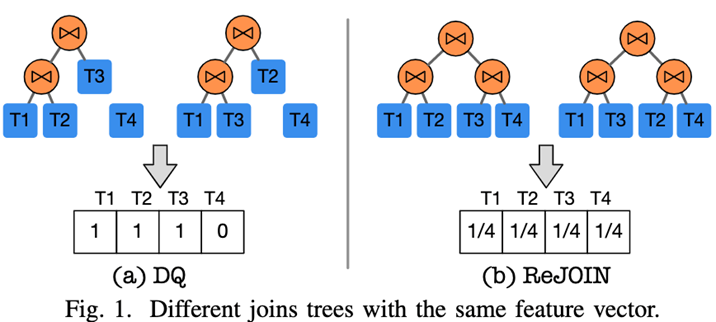
Suppose a database has 4 Tables T1、T2、T3、T4.DQ Use heat only coding (1 Indicates that the table is in the tree , Otherwise 0) To encode the connection tree : It can be found in the figure ((T1,T2), T3) and ((T1,T3),T2) Have the same eigenvector [1,1,1,0].ReJOIN Use the depth of the join table to construct the eigenvector : chart (b) Can be found in , The depth of each table is d = 2,((T1,T2),(T3 T4)) and ((T1, T3), (T2,T4)) Have the same eigenvector [1/4,1/4,1/4,1/4].
Part 3 - RTOS frame
For the above mentioned based on DRL Learning optimizer method , Because they cannot capture the structural characteristics of the connection tree , As a result, it cannot always be obtained at a low cost 、 A scheme with short execution time . In addition, these methods cannot adapt to some operations that change the database schema , Such as adding columns / After the table name , The neural network needs to be trained again . Therefore, the author of this paper proposes RTOS, Focus on capturing the structural characteristics of the connection tree , Better estimate the plan and get the plan with low execution time , At the same time, it can adapt to some operations that will change the database faster .
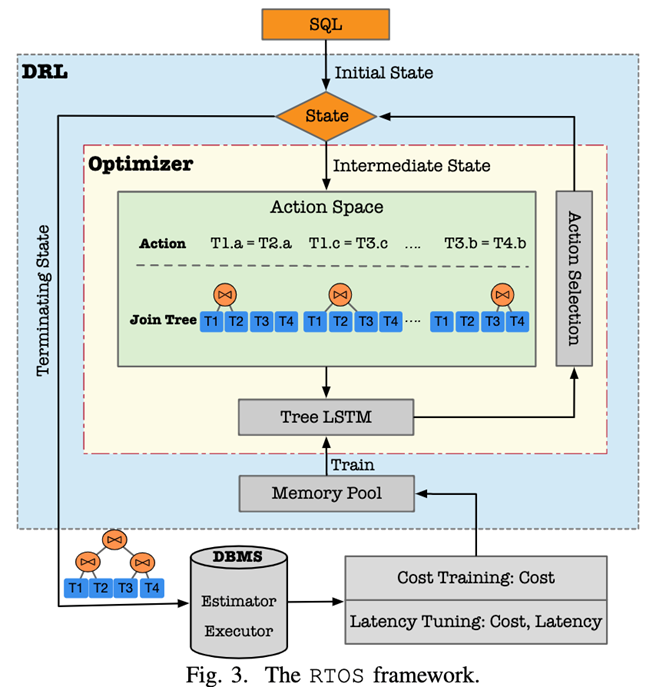
Whole RTOS The framework consists of two parts :DRL Optimizer and DBMS.
1. DRL Optimizer Contained in the State、Optimizer and Memory Pool.State Maintain the current status information of the connection process , The details are as follows: Part4 Partial explanation ;Optimizer Corresponding to RL Medium Agent, It is the core of the whole system . For a given state , Each candidate connection condition can be regarded as one Action;Memory Pool Record RTOS The status and source of the generated plan DBMS Feedback .
2. DBMS Used to RTOS The generated connection plan is used for cost estimation .RTOS Generate a join plan for a given query , Then pass it to DBMS, for example PostgreSQL. We use DBMS Two components in ,Estimator and Executor.Estimator Can give a plan Cost, Use statistics to estimate costs , Without execution . and Executor The user gets the actual execution of the plan Latency.
in addition , In terms of model training ,RTOS The method of two-stage training is used . say concretely , First use Cost Train the model with low cost as feedback ; Then use the real execution Latency Adjust model parameters as feedback .
Part 4 - States Express
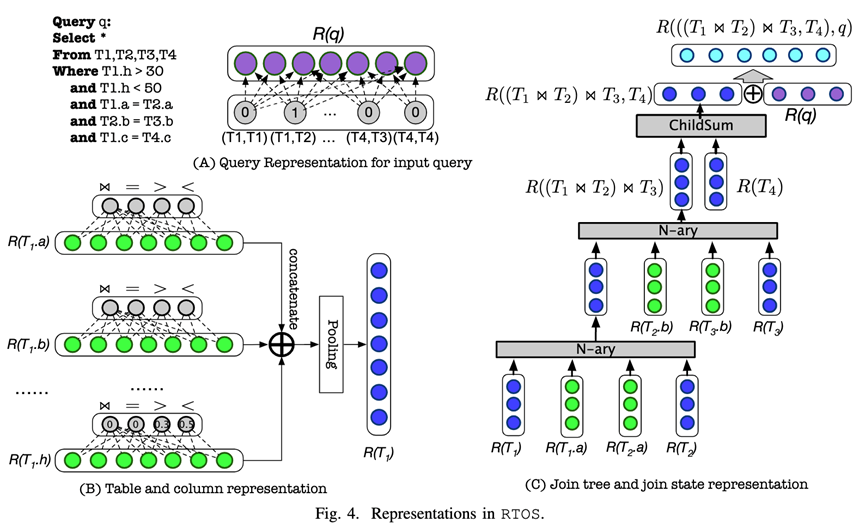
State The representation of consists of three parts :
1. Input SQL Representation of query : It is used to describe the whole play information queried , Expressed by neural network , It includes the tables that need to be connected in the query and the predicate information in the query .
2. Representation of tables and columns : The table and column information in the query is represented by neural network , Calculate features based on predicates , Represent the columns involved in the calculation , Then get the representation of the table through pooling .
3. Number of connections and representation of connections : Through a variety of Tree-LSTM The combination of represents the connection tree and connection status information .
The first two kinds of information contain the previous methods :DQ,ReJOIN Feature vector information mentioned in , The last representation preserves the connection order and the structural information of the complete connection tree . The state information represented by neural network can be realized when the database schema needs to be modified , For example, when adding a new column or table , It can be achieved by applying for new parameters , Instead of retraining the model .
RTOS Strengthen learning strategies :
This article uses DQN Deep reinforcement learning method , By designing a Q-network To estimate the Q value . When collecting feedback on training , because Latency Need to actually execute SQL Query to get , The cost of collection is higher . and Cost As Latency An approximate estimate of , There is no need to actually execute SQL Inquire about , The cost of collection is low , And can realize and Latency Also select for guiding the connection sequence . Because of RTOS The process of reinforcement learning feedback and training is divided into two stages :
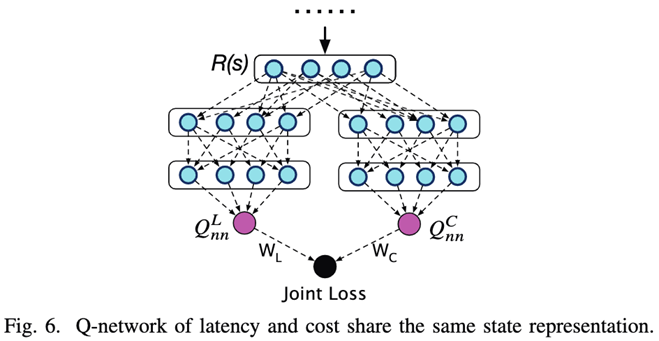
The first stage , Use SQL Of the statement Cost As feedback , Generate a large amount of training data , bring RTOS Based on the DRL The learning optimizer of can achieve the traditional method , For example, dynamic planning has the same effect , Choose the Cost Plan for lower connection order .
The second stage , Use actual execution SQL Statement Latency As feedback, fine tune RTOS Model of . Through the actual Latency Fine tuning can correct RTOS Chinese vs Cost Plan to estimate the wrong connection sequence . That is, it is estimated Cost High value and actually implemented Latency Lower plan , vice versa .
Part 5 - experimental result
This paper is based on PostgreSQL To build the RTOS, The experiment used benchmark yes JOB(Join Order Benchmark) and TPC-H.JOB It's based on IMDB Real data sets of , Provide real workloads , It comes from 33 It's a template 113 A query , Contains 3.6GB The data of ( The index is calculated as 11GB) and 21 A watch .TPC-H Is a standard industry database benchmark , Yes 8 A watch . The paper uses 22 Templates have been generated 4GB Data and 110 A query . In addition to the above baseline( for example DQ,ReJOIN,DP) outside , The paper also compares SkinnerDB( An approach based on reinforcement learning strategies ) and QuickPick( A greedy algorithm ). The experimental results are as follows :
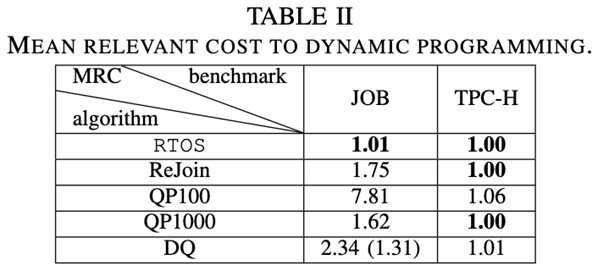
COST result :
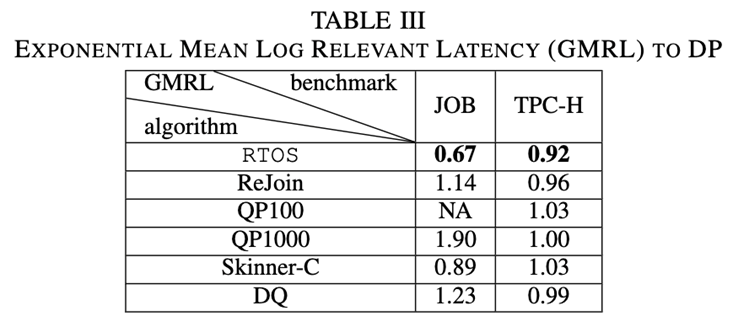
LATENCY result :
JOB The results on the dataset :
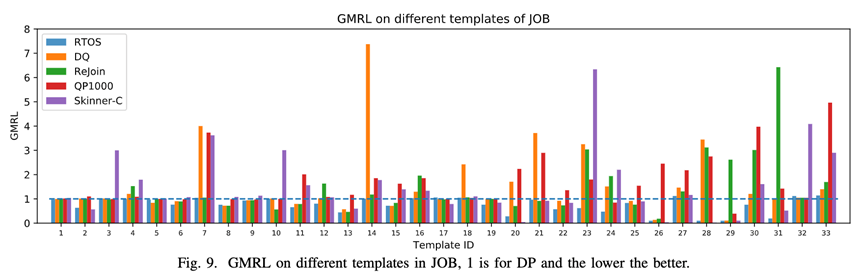
The first indicator : The paper DP As a baseline , And other methods according to the previous work report MRC(mean relative cost, Average relative cost ), among MRC = 1 To express with DP Same performance . Observe Cost and Latency The results show that ,RTOS stay Cost It is superior to the other four methods , And almost with DP equal , stay Latency Better , Is the lowest latency of all methods .
The second indicator : The paper classifies the queries in the data set according to the template , Calculation GMRL( Geometric Mean Relevant Latency, Geometric mean correlation delay ), From the picture 9 Can be found in , Most of the time RTOS The performance of is not inferior to DP, And better than other methods . about T20,T26,T28,T29 etc. RTOS The performance of is much better than DP, Because most of the test templates in the experimental data are relatively long or queries with multiple aliases , The traditional cost model often has the problem of inaccurate estimation , Cause to be based on Cost The chosen plan may not be optimal , and RTOS Can solve this problem , By executing from the query latency Learning in , You can modify the selected plan , For higher performance .
TPC-H The results on the dataset :
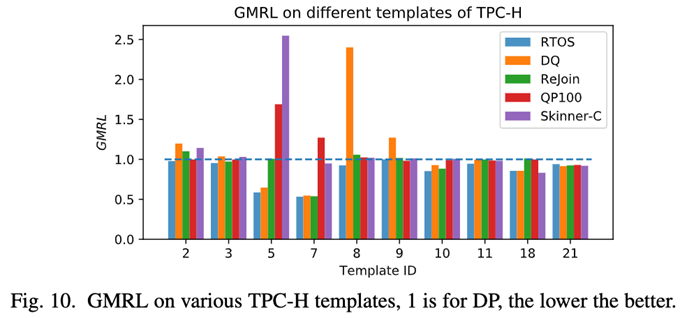
chart 10 Shows TPC-H On different templates , It doesn't show DRL Methods and DP Method executes the same template , For a better view . You can find that for all templates ,RTOS The generated plan is no better than DP Bad ( stay GMRL= 1 Horizontal line at ), It is also better than other methods .
Part 6 - Summary and reflection
This paper introduces the method of applying machine learning to the problem of connection sequence selection : Use Tree-LSTM Learning the tree structure of connection plan RTOS. First ,RTOS Deep reinforcement learning technology is used to solve JOS problem , On top of that , Adopted Tree-LSTM The model encodes the connection state . Based on the first two works, a design based on DRL Learning optimizer , utilize SQL Analytic knowledge 、DRL Select the connection order of 、DNN Cost estimate of the plan , A good plan can be generated on the basis of cost and delay ; It is proved that this method can learn the structure of connection tree well , Get information about the connection operation . The paper also proves , This cost can pre train the neural network , Reduce latency tuning time . However , It is mentioned in the paper that , There are still some problems in the actual use scenario , for example : Training time is too long 、 The connection sequence cannot be selected adaptively according to different database States .
边栏推荐
- How to modify icons in VBS or VBE
- 【2022年江西省研究生数学建模】水汽过饱和的核化除霾 思路分析及代码实现
- 神经网络物联网是什么意思通俗的解释
- 力扣刷题日记/day4/6.26
- 中国农科院基因组所汪鸿儒课题组诚邀加入
- Reptile elementary learning
- 力扣刷题日记/day8/7.1
- Send and receive IBM WebSphere MQ messages
- 学习路之PHP--phpstudy创建项目时“hosts文件不存在或被阻止打开”
- Crawler (6) - Web page data parsing (2) | the use of beautifulsoup4 in Crawlers
猜你喜欢
Scala基础教程--20--Akka
Li Kou brush question diary /day4/6.26

Grain Mall (I)
Deleting nodes in binary search tree
Wanghongru research group of Institute of genomics, Chinese Academy of Agricultural Sciences is cordially invited to join
Neglected problem: test environment configuration management
VMware Tools和open-vm-tools的安装与使用:解决虚拟机不全屏和无法传输文件的问题
Rookie post station management system based on C language
Li Kou brush question diary /day8/7.1

能源行业的数字化“新”运维
随机推荐
[209] go language learning ideas
[opencv introduction to mastery 9] opencv video capture, image and video conversion
Process of manually encrypt the mass-producing firmware and programming ESP devices
其他InterSystems %Net工具
Li Kou brush question diary /day7/6.30
力扣刷题日记/day5/2022.6.27
Li Kou brush question diary /day7/2022.6.29
正则替换【JS,正则表达式】
能源行业的数字化“新”运维
Journal des problèmes de brosse à boutons de force / day6 / 6.28
Is it safe to open an account online? is that true?
Scala基础教程--12--读写数据
ESP32-C3入门教程 问题篇⑫——undefined reference to rom_temp_to_power, in function phy_get_romfunc_addr
Principle and application of ThreadLocal
一种将Tree-LSTM的强化学习用于连接顺序选择的方法
Scala基础教程--19--Actor
千万不要只学 Oracle、MySQL!
6.26cf simulation race e: solution to the problem of price maximization
爬虫(6) - 网页数据解析(2) | BeautifulSoup4在爬虫中的使用
小发猫物联网平台搭建与应用模型