当前位置:网站首页>Introduction, type selection comparison and architecture design of common distributed file storage
Introduction, type selection comparison and architecture design of common distributed file storage
2022-06-28 17:05:00 【Full stack programmer webmaster】
Hello everyone , I meet you again , I'm your friend, Quan Jun .
Hello, I'm cuckoo :
Before, when docking storage projects , Sort out the file system used in the company , The file systems currently used within the company are GlusterFS,FastDFS etc. , The performance of the file system drops sharply due to the large number of small files and high concurrency , Performance bottlenecks , So we plan to build a distributed object storage platform . Next, we will sort out and compare the popular unstructured file storage products in the market .
Distributed storage source files
In this era of data explosion , The amount of data generated is increasing , from GB,TB,PB,ZB. Mining the value of data is also the ultimate goal of enterprises . But if you want to mine massive data , The first thing to consider is the storage of massive data , such as Tb Data of magnitude .
When it comes to data storage , What we have to say is the speed of data reading and writing on disk . Back in the last century 90 In the early s , The storage capacity of an ordinary hard disk is about 1G about , The reading speed of the hard disk is about 4.4MB/s. It takes about 5 Minute time , But today, the capacity of hard disks is 1TB Around the , Compared with the expansion of nearly a thousand times . But the reading speed of the hard disk is about 100MB/s. The time it takes to read a hard disk is about 2.5 Hours . So if it's based on TB Level of data for analysis , It's been several days since the optical hard disk finished reading data , Not to mention calculation and analysis . So how to deal with the storage of big data , How about calculation and analysis ?
Common distributed file storage
Common distributed file systems
GFS、HDFS、Lustre 、Ceph 、GridFS 、mogileFS、TFS、FastDFS etc. . They are suitable for different fields . None of them are system level distributed file systems , But application level distributed file storage Storage services .
Distributed file storage selection comparison
Well known open source distributed file storage
1.GFS(Google File System)
Google In order to meet the needs of our company, we have developed a product based on Linux Proprietary distributed file system . Even though Google Some technical details of the system are published , but Google The software part of the system is not released as open source software .
2.HDFS
Hadoop Implemented a distributed file system (Hadoop Distributed File System), abbreviation HDFS. Hadoop yes Apache Lucene founder Doug Cutting Developed a widely used text search library . It originated in the Apache Nutch,
The latter is an open source web search engine , Itself is also Luene Part of the project .Aapche Hadoop The architecture is MapReduce An open source application of the algorithm , yes Google An important cornerstone of his empire .
3.TFS
TFS(Taobao FileSystem) It's a highly scalable 、 High availability 、 High performance 、 Distributed file system for Internet services , Mainly for massive unstructured data , It's built on ordinary Linux machine On the cluster , It can provide high reliability for the outside
And highly concurrent storage access .TFS Taobao provides massive small file storage , Usually the file size does not exceed 1M, It meets Taobao's demand for small file storage , Widely used In various applications of Taobao . It USES a HA Architecture and smooth expansion , Ensure the availability and scalability of the whole file system . At the same time, flat data organization structure , You can map the file name to the physical address of the file , simplify This paper introduces the file access process , To some extent TFS Provides good read and write performance .
Google Academic papers , This is the origin of many distributed file systems ,HDFS and TFS It's all for reference Google Of GFS Design Coming out .
Typical architecture design of distributed file storage
I take hadoop Of HDFS For example , After all, open source distributed file storage is used the most .
Hadoop distributed file system (HDFS) Designed to run on universal hardware (commodity hardware) Distributed file system on .HDFS It's a highly fault tolerant system , Suitable for deployment on cheap machines .HDFS It can provide high throughput data access , Very suitable for large-scale data set applications .HDFS A part of the relaxation POSIX constraint , To achieve streaming read file system data .
Large data sets
Running on the HDFS The application on has a large data set .HDFS A typical file size on is usually G Bytes to T byte . therefore ,HDFS Tuned to support large file storage . It should be able to provide overall high data transmission bandwidth , It can expand to hundreds of nodes in a cluster . A single HDFS Examples should be able to support tens of millions of files .
A simple consistency model
HDFS The application needs a “ Write multiple reads at a time ” File access model for . A file is created 、 After writing and closing, there is no need to change . This assumption simplifies the problem of data consistency , And make high-throughput data access possible .Map/Reduce Applications or web crawler applications are very suitable for this model . There are plans to expand this model in the future , Make it support additional write operations of files .
Portability between heterogeneous hardware and software platforms
HDFS The portability of the platform is considered in the design . This feature facilitates HDFS As the promotion of large-scale data application platform .
Namenode and Datanode
HDFS use master/slave framework . One HDFS The cluster is made up of a Namenode And a certain number of Datanodes form .
Namenode It's a central server , Responsible for managing the file system's namespace (namespace) And client access to files .
In the cluster Datanode It's usually one node and one , Responsible for managing the storage on the node where it resides .HDFS Exposed the namespace of the file system , Users can store data in the form of files . From the inside , A file is actually divided into one or more data blocks , These blocks are stored in a set of Datanode On .
Namenode Perform namespace operations on the file system , Like opening 、 close 、 Rename a file or directory . It's also responsible for identifying data blocks to specific Datanode Mapping of nodes .Datanode Responsible for handling the read and write requests of the file system client . stay Namenode Data block creation under unified scheduling 、 Delete and copy .
Namenode and Datanode Designed to run on ordinary commercial machines . These machines generally run GNU/Linux operating system (OS).HDFS use Java Language development , So any support Java All machines can be deployed Namenode or Datanode. Due to the adoption of highly portable Java Language , bring HDFS It can be deployed to many types of machines . A typical deployment scenario is to run only one Namenode example , The other machines in the cluster run one Datanode example . This architecture does not exclude running multiple on one machine Datanode, It's just that it's rare .
The future of distributed storage
With the transition of modern society from the industrial age to the information age , The development of information technology and the intellectualization of human life bring explosive growth of data , Data is becoming the most valuable resource in the world .
According to the physical storage form , Data storage can be divided into centralized storage and distributed storage . Centralized storage is based on traditional storage array ( Traditional storage ) Mainly , Distributed storage ( Cloud storage ) Mainly software defined storage .
Traditional storage Always with high reliability 、 Good stability , It is famous for its rich functions , But at the same time , Traditional storage also exposes poor horizontal scalability 、 Expensive 、 Data connectivity is difficult , It is easy to form a data island , Leading to high cost of data center management and maintenance .
Distributed storage : Store data in multiple independent devices on the network , Generally, the standard x86 Server and network interconnection , And run the relevant storage software on it , The system provides storage services as a whole ..
All in all , Distributed file storage , It not only improves the utilization of storage space , It also achieves elastic expansion , Reduced operating costs , Avoid waste of resources , It is more suitable for the future scenario of data explosion era .
Publisher : Full stack programmer stack length , Reprint please indicate the source :https://javaforall.cn/132769.html Link to the original text :https://javaforall.cn
边栏推荐
- 如何登录到你的 WordPress 管理仪表板
- C#/VB. Net to convert PDF to excel
- 批量修改指定字符文件名 bat脚本
- Please ask me, the queries written in my database account for 99%. Is it better to use pay as you go mode or reservation mode?
- 【TcaplusDB知识库】TcaplusDB限制条件介绍
- "Popular science leaders say" intelligent bionic robot fish
- GCC efficient graph revolution for joint node representationlearning and clustering
- Research on master's thesis writing
- 小新黑苹果声卡ID注入
- NOIP2011-2018提高组解题报告
猜你喜欢

这个简单的小功能,半年为我们产研团队省下213个小时

【TcaplusDB知识库】TcaplusDB限制条件介绍
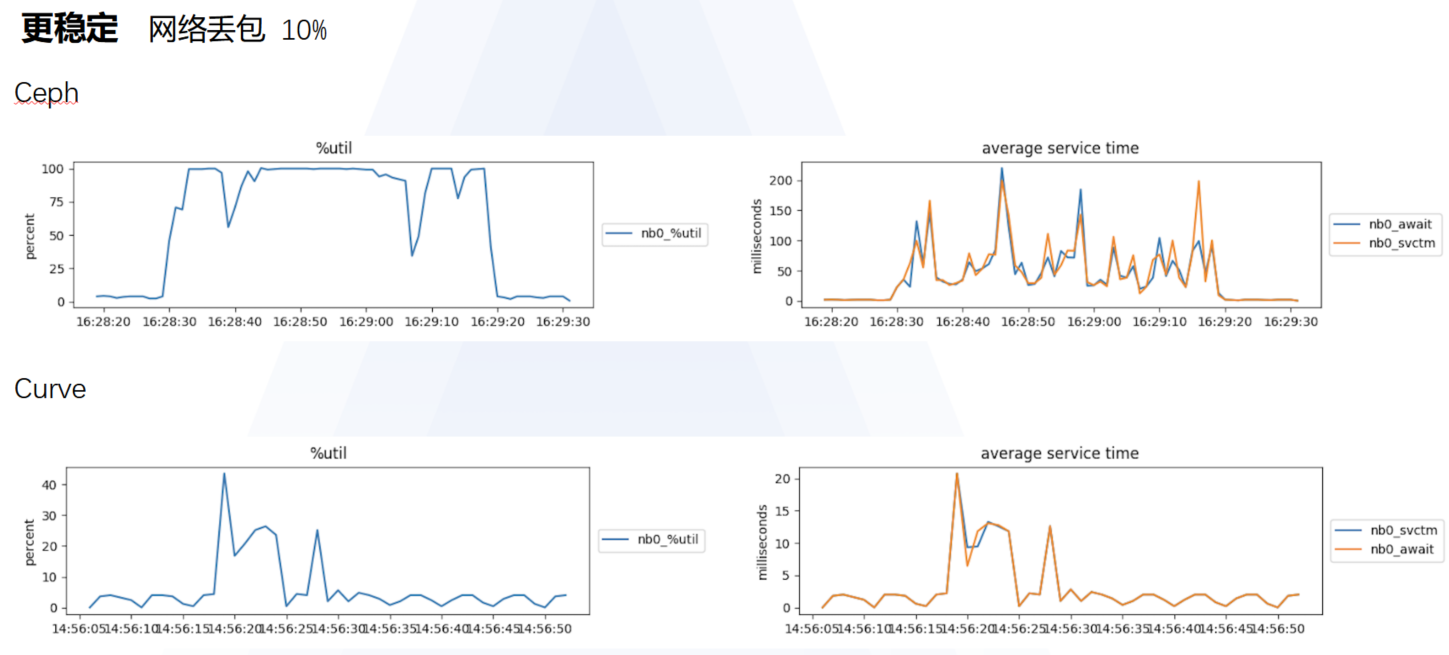
Curve 替换 Ceph 在网易云音乐的实践

7-用户输入和while循环

解决sqoop出现 ERROR manager.SqlManager: Generic SqlManager.listDatabases() not implemented

批量修改指定字符文件名 bat脚本
This simple little function saves 213 hours for our production research team in half a year

老司机总结的12条 SQL 优化方案(非常实用)

Lucky draw animation - Carp jumps over the dragon's gate

Potplayer play Baidu Cloud disk video
随机推荐
Curve 替换 Ceph 在网易云音乐的实践
【TcaplusDB知识库】WebClient用户如何读取和修改数据
[force button] 35 Search insert location
offsetwidth\clientwidth\scrollwidth
Solve the problem that subcomponents will not be destroyed through setTimeout
Introduction to LTSpice circuit simulation
彻底凉了!腾讯知名软件全线下架,网友一片唏嘘。。。
PotPlayer播放百度云盘视频
How to query the last data according to multiple indexes to achieve the effect of SQL order by desc limit 1?
【世界海洋日】TcaplusDB号召你一同保护海洋生物多样性
批量修改指定字符文件名 bat脚本
Super detailed steps for MySQL master-slave switching
ARM9开发之学习过程总结[通俗易懂]
编写自己的 WordPress 模板
使用Karmada实现Helm应用的跨集群部署
Fs2k face sketch attribute recognition
After the first failure, AMEC rushed to the Hong Kong stock exchange for the second time, and the financial principal changed frequently
"Popular science leaders say" intelligent bionic robot fish
Subscription publishing mode bus in JS
强化 WordPress 的 11 种有效方法