当前位置:网站首页>DownMusic总结记录
DownMusic总结记录
2022-08-02 22:46:00 【Y6blNU1L】
# -*- coding: utf-8 -*-
import base64
import requests
import os
import json
from pyDes import des, PAD_PKCS5, CBC
import threading
# 加解密工具
def decryptAndSetCookie(text: str):
replace = text.replace("-", "").replace("|", "")
if len(replace) < 10 or replace.find("%") == -1:
return False
split = replace.split("%")
key = split[0]
qq = str(decryptDES(split[1], key[0:8]), "utf-8")
if len(qq) < 8:
qq += "QMD"
mkey = str(decryptDES(key, qq[0:8]), "utf-8")
return mkey, qq # 用对象的encrypt方法加密
# des解密
def decryptDES(strs: str, key: str): return des(
key, CBC, key, padmode=PAD_PKCS5).decrypt(base64.b64decode(str(strs)))
# des加密
def encryptDES(text: str, key: str): return str(base64.b64encode(
des(key, CBC, key, padmode=PAD_PKCS5).encrypt(text)), 'utf-8')
# 加密字符串
def encryptText(text: str, qq: str):
key = ("QMD"+qq)[0:8]
return encryptDES(text, key)
# 解密字符串
def decryptText(text: str, qq: str): return str(decryptDES(
text.replace("-", ""), ("QMD" + qq)[0:8]), 'utf-8')
def getHead():
return {
'user-agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36',
'content-type': 'application/json; charset=UTF-8',
"referer": "https://y.qq.com/portal/profile.html"
}
sess = requests.Session()
def buildSearchContent(song='', page=1, page_per_num=100):
return {
"comm": {
"ct": "19", "cv": "1845"},
"music.search.SearchCgiService": {
"method": "DoSearchForQQMusicDesktop",
"module": "music.search.SearchCgiService",
"param": {
"query": song, "num_per_page": page_per_num, "page_num": page}
}
}
def searchMusic(key="", page=1):
# base url
url = "https://u.y.qq.com/cgi-bin/musicu.fcg"
# base data content from qqmusic pc-client-apps
data = buildSearchContent(key, page)
data = json.dumps(data, ensure_ascii=False)
data = data.encode('utf-8')
res = sess.post(url, data, headers=getHead())
jsons = res.json()
# 开始解析QQ音乐的搜索结果
res = jsons['music.search.SearchCgiService']['data']
list = res['body']['song']['list']
meta = res['meta']
# 数据清洗,去掉搜索结果中多余的数据
list_clear = []
for i in list:
list_clear.append({
'album': i['album'],
'docid': i['docid'],
'id': i['id'],
'mid': i['mid'],
'name': i['title'],
'singer': i['singer'],
'time_public': i['time_public'],
'title': i['title'],
'file': i['file'],
})
# rebuild json
# list_clear: 搜索出来的歌曲列表
# {
# size 搜索结果总数
# next 下一搜索页码 -1表示搜索结果已经到底
# cur 当前搜索结果页码
# }
return list_clear, {
'size': meta['sum'],
'next': meta['nextpage'],
'cur': meta['curpage']
}
def getCookie():
uid = "822a3b85-a5c9-438e-a277-a8da412e8265"
systemVersion = "1.7.2"
versionCode = "76"
deviceBrand = "360"
deviceModel = "QK1707-A01"
appVersion = "7.1.2"
encIP = encryptText(
f'{
uid}{
deviceModel}{
deviceBrand}{
systemVersion}{
appVersion}{
versionCode}', "F*ckYou!")
u = 'http://8.136.185.193/api/Cookies'
d = f'\{
{"appVersion":"{
appVersion}","deviceBrand":"{
deviceBrand}","deviceModel":"{
deviceModel}","ip":"{
encIP}","systemVersion":"{
systemVersion}","uid":"{
uid}","versionCode":"{
versionCode}"\}}'.replace(
"\\", "")
ret = sess.post(u, d, headers={
'Content-Type': 'application/json; charset=UTF-8'
})
return ret.text
def getDownloadLink(fileName):
u = 'http://8.136.185.193/api/MusicLink/link'
d = f'"{
encryptText(fileName, mqq_)}"'
ret = sess.post(
u, d, headers={
"Content-Type": "application/json;charset=utf-8"
})
return ret.text
def getMusicFileName(code, mid, format): return f'{
code}{
mid}.{
format}'
def parseSectionByNotFound(filename, songmid):
global mqq_
global mkey_
u = 'https://u.y.qq.com/cgi-bin/musicu.fcg'
d = {
"comm": {
"ct": "19", "cv": "1777"}, "queryvkey": {
"method": "CgiGetVkey", "module": "vkey.GetVkeyServer", "param": {
"uin": mqq_,
"guid": "QMD50",
"referer": "y.qq.com",
"songtype": [1],
"filename": [filename], "songmid": [songmid]
}}}
d = json.dumps(d, ensure_ascii=False)
d = sess.post(u, d, headers={
'referer': 'https://y.qq.com/portal/profile.html',
'user-agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36',
'cookie': f'qqmusic_key={
mkey_};qqmusic_uin={
mqq_};',
'content-type': 'application/json; charset=utf-8'
})
vkey = d.json()['queryvkey']['data']['midurlinfo'][0]['purl']
u = f'http://ws.stream.qqmusic.qq.com/{
vkey}&fromtag=140'
return u
mkey_ = ""
mqq_ = ""
def downSingle(it):
global download_home
# prepare
localFile = f"{
it['singer']} - {
it['title']}.{
it['extra']}"
my_path = download_home+it['singer']+'/'
my_path = f"{
my_path}{
it['album']}"
if not os.path.exists(my_path):
os.mkdir(f"{
my_path}")
localFile = os.path.join(my_path, f"{
localFile}")
if os.path.exists(localFile):
if os.path.getsize(localFile) == int(it['size']):
print(f"本地已下载,跳过下载 [{
it['album']} / {
localFile}].")
return True
else:
print(
f"本地文件尺寸不符: {
os.path.getsize(localFile)}/{
int(it['size'])},开始覆盖下载 [{
localFile}].")
file = getMusicFileName(
it['prefix'], it['mid'], it['extra'])
log = f"{
it['singer']} - {
it['title']} [{
it['notice']}] {
round(int(it['size'])/1024/1024,2)}MB - {
file}"
print(f'正在下载 | {
it["album"]} / {
log}')
link = getDownloadLink(file)
if link.find('qqmusic.qq.com') == -1:
if link.find('"title":"Not Found"') != -1:
# 开始第二次解析
link = parseSectionByNotFound(file, it['songmid'])
else:
print(f"解析歌曲下载地址失败!{
log}")
return False
f = sess.get(link)
with open(localFile, 'wb') as code:
code.write(f.content)
code.flush()
return True
def _main(target="周杰伦"):
global mkey_
global mqq_
global download_home
global dualThread
print("==== welcome to QQMusic digit High Quality Music download center ====")
my_path = download_home+target+'/'
if not os.path.exists(my_path):
os.mkdir(f"{
my_path}")
cookie = getCookie()
mkey, qq = decryptAndSetCookie(cookie)
mkey_ = mkey
mqq_ = qq
# 根据文件名获取下载链接
# getDownloadLink("RS01003w2xz20QlUZt.flac")
# filename = "ID9TZr-ensC/-rJ2t6-atFsm+sRG+2S6CqS"
# filename = decryptText(filename, qq)
# # 解密后 RS01 003w2xz20QlUZt . flac
page = 1
while True:
(list, meta) = searchMusic(target, page)
if meta['next'] != -1:
add = 1
span = " "
songs = []
for i in list:
singer = i['singer'][0]['name']
if singer != target:
# print(f"{singer} not is {target}")
continue
if add > 9:
span = " "
if add > 99:
span = ""
id = i["file"]
# 批量下载不需要选择音质 直接开始解析为最高音质 枚举
code = ""
format = ""
qStr = ""
fsize = 0
mid = id['media_mid']
if int(id['size_hires']) != 0:
# 高解析无损音质
code = "RS01"
format = "flac"
qStr = "高解析无损 Hi-Res"
fsize = int(id['size_hires'])
elif int(id['size_flac']) != 0:
isEnc = False # 这句代码是逆向出来的 暂时无效
if(isEnc):
code = "F0M0"
format = "mflac"
else:
code = "F000"
format = "flac"
qStr = "无损品质 FLAC"
fsize = int(id['size_flac'])
elif int(id['size_320mp3']) != 0:
code = "M800"
format = "mp3"
qStr = "超高品质 320kbps"
fsize = int(id['size_320mp3'])
elif int(id['size_192ogg']) != 0:
isEnc = False # 这句代码是逆向出来的 暂时无效
if(isEnc):
code = "O6M0"
format = "mgg"
else:
code = "O600"
format = "ogg"
qStr = "高品质 OGG"
fsize = int(id['size_192ogg'])
elif int(id['size_128mp3']) != 0:
isEnc = False # 这句代码是逆向出来的 暂时无效
if(isEnc):
code = "O4M0"
format = "mgg"
else:
code = "M500"
format = "mp3"
qStr = "标准品质 128kbps"
fsize = int(id['size_128mp3'])
elif int(id['size_96aac']) != 0:
code = "C400"
format = "m4a"
qStr = "低品质 96kbps"
fsize = int(id['size_96aac'])
albumName = str(i["album"]['title']).strip(" ")
if albumName == '':
albumName = "未分类专辑"
songs.append({
'prefix': code,
'extra': format,
'notice': qStr,
'mid': mid,
'songmid': i['mid'],
'size': fsize,
'title': f'{
i["title"]}',
'singer': f'{
singer}',
'album': albumName})
time_publish = i["time_public"]
if time_publish == '':
time_publish = "0000-00-00"
print(
f'{
add} {
span}{
time_publish} {
singer} - {
i["title"]}')
add += 1
willDownAll = False
while True:
print(
f"\n获取列表成功.当前第{
page}页,共{
meta['size']}条搜索结果.\n下一页输入n\n上一页输入p\n一键下载本页所有歌曲输入a\n若要下载某一首,请输入歌曲前方的序号。\n修改搜索关键词输入s\n请输入:", end='')
inputKey = input()
if inputKey == "n":
break
elif inputKey == "s":
print('\033c', end='')
print("请输入新的搜索关键词:", end='')
_main(input())
return
elif inputKey == 'a':
# 下载本页所有歌曲
willDownAll = True
elif inputKey == 'p':
page -= 2
if page + 1 < 1:
page = 0
break
if willDownAll:
thList = []
for mp3 in songs:
th = threading.Thread(target=downSingle, args=(mp3,))
thList.append(th)
th.start()
if len(thList) == dualThread:
while len(thList) > 0:
thList.pop().join()
# downSingle(mp3)
while len(thList) > 0:
thList.pop().join()
willDownAll = False
else:
op = -1
try:
op = int(inputKey)
except:
print("输入无效字符,请重新输入。")
continue
it = songs[op-1]
downSingle(it)
print("下载完成!")
page += 1
else:
break
print()
# 下载的文件要保存到哪里
# /music/就是你自定义的文件夹名称 随便指定 会自动创建
download_home = "./"
# 多线程下载 线程数量
dualThread = 16
_main()
边栏推荐
- MySQL 与InnoDB 下的锁做朋友 (四)行锁/记录锁
- 在软件测试行业近20年的我,再来和大家谈谈今日的软件测试
- Based on two levels of decomposition and the length of the memory network multi-step combined forecasting model of short-term wind speed
- No code development platform data ID introductory tutorial
- ZCMU--5230: 排练方阵(C语言)
- 用大白话解释“什么是ERP?” 看完这篇就全明白了
- 停止使用 Storyboards 和 Interface Builder
- VMware workstation 程序启动慢
- Strict feedback nonlinear systems based on event trigger preset since the immunity of finite time tracking control
- Towards a General Purpose CNN for Long Range Dependencies in ND
猜你喜欢
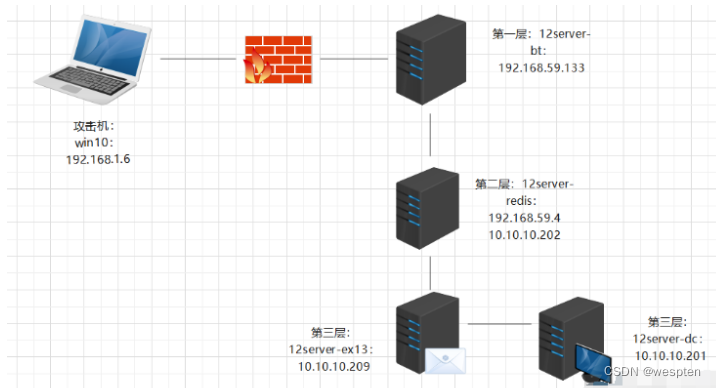
APT级全面免杀拿Shell
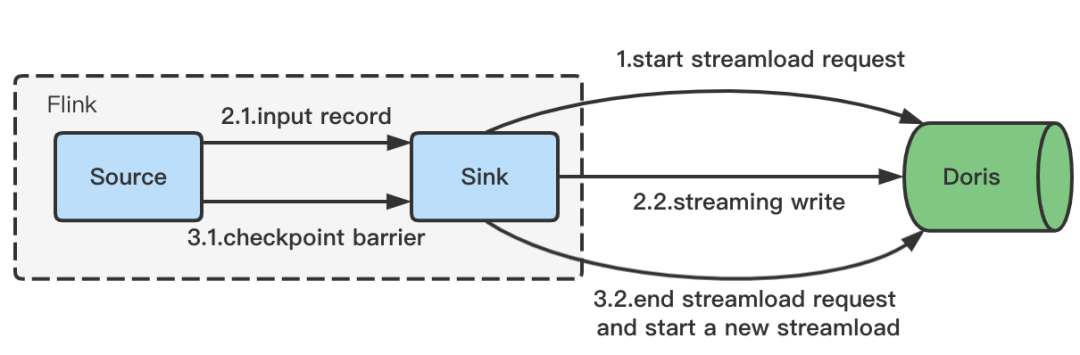
Apache Doris 1.1 特性揭秘:Flink 实时写入如何兼顾高吞吐和低延时
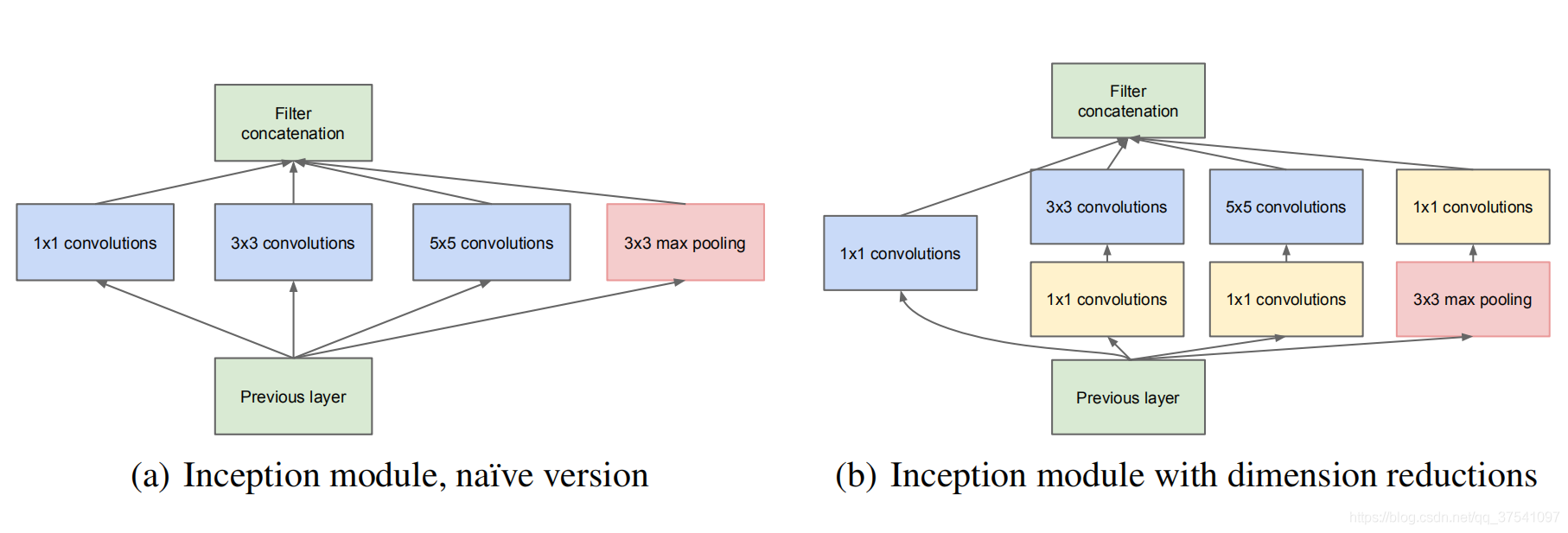
Week 7 CNN Architectures - LeNet-5、AlexNet、VGGNet、GoogLeNet、ResNet
同一份数据,Redis为什么要存两次?
APT level comprehensive free kill with Shell

非关系型数据库MongoDB简介和部署
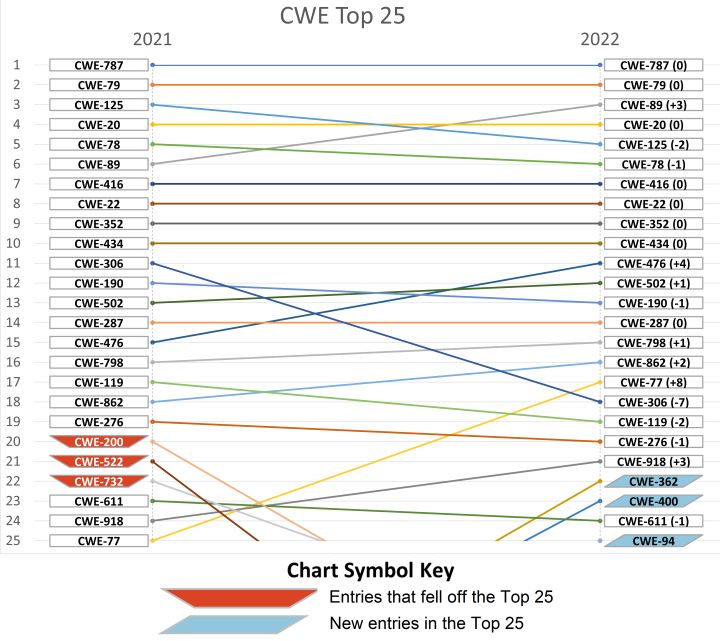
CWE4.8:2022年危害最大的25种软件安全问题
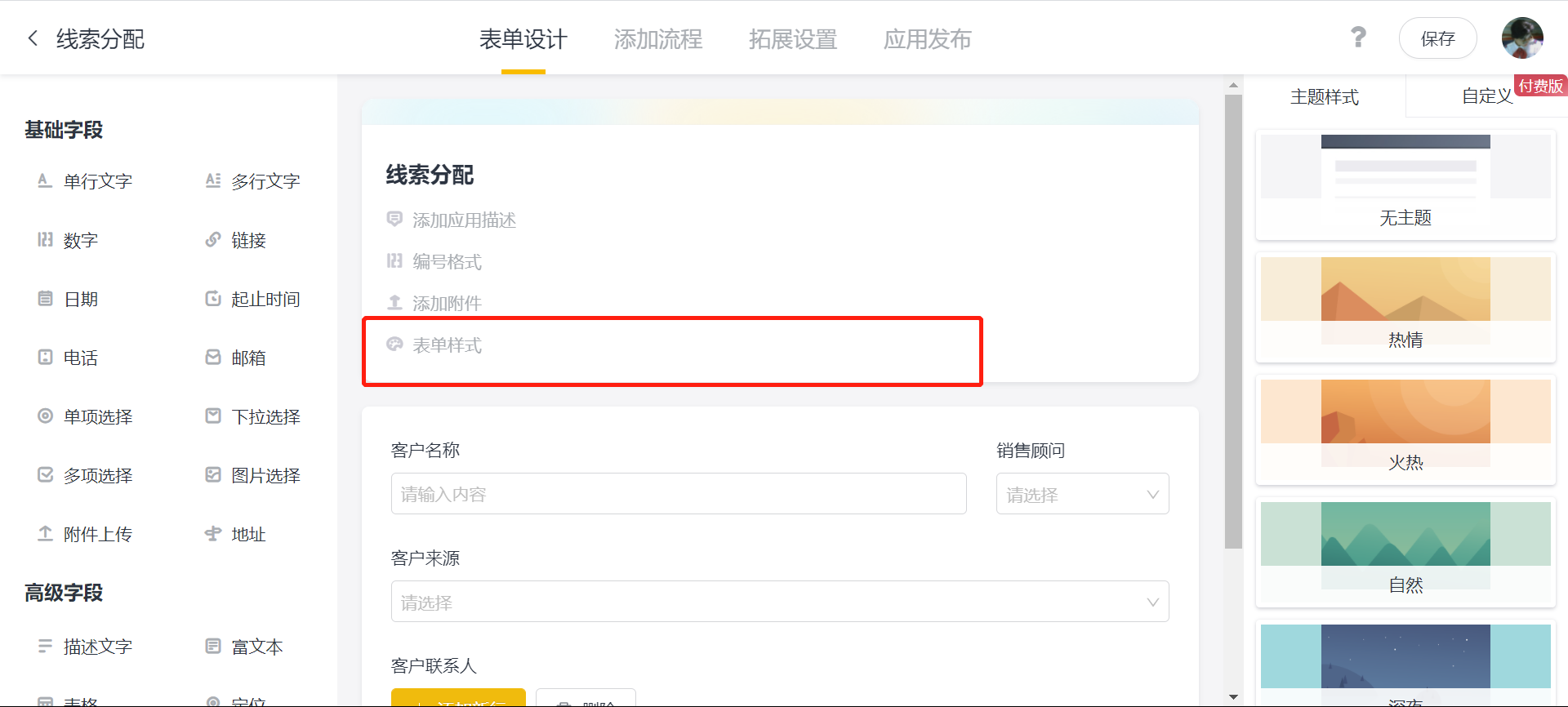
No-code development platform form styling steps introductory course

1 - vector R language self-study
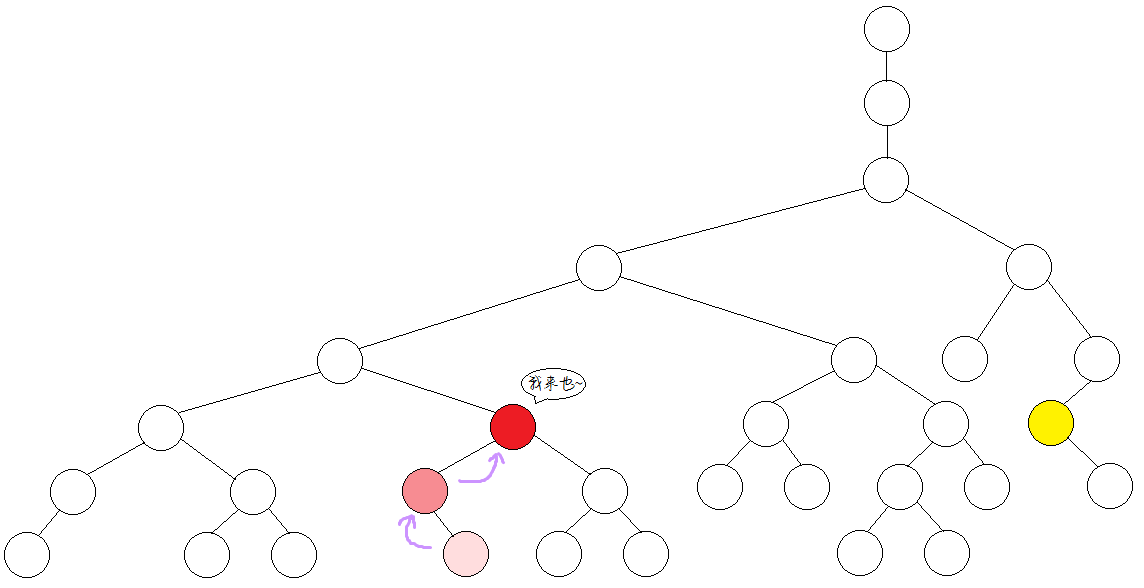
最近公共祖先(LCA)学习笔记 | P3379 【模板】最近公共祖先(LCA)题解
随机推荐
mysql查询表中重复记录
ssm整合(三)Controller 和 视图层编写
严格反馈非线性系统基于事件触发的自抗扰预设有限时间跟踪控制
VS保存后Unity不刷新
无代码开发平台数据ID入门教程
基于飞腾平台的嵌入式解决方案案例集 1.0 正式发布!
threejs dynamically adjust the camera position so that the camera can see the object exactly
Go语言如何操作文件
GameStop NFT 市场分析
WebShell 木马免杀过WAF
Based on two levels of decomposition and the length of the memory network multi-step combined forecasting model of short-term wind speed
scala 集合通用方法
脂溶性胆固醇-聚乙二醇-叠氮,Cholesterol-PEG-Azide,CLS-PEG-N3
qt静态编译出现Project ERROR: Library ‘odbc‘ is not defined
vscode 自定义快捷键——设置eslint
如何通过 IDEA 数据库管理工具连接 TDengine?
today‘s task
学习Autodock分子对接
MySql查询某个时间段内的数据(前一周、前三个月、前一年等)
IDEA 重复代码的黄色波浪线取消设置