当前位置:网站首页>數倉4.0筆記——用戶行為數據采集四
數倉4.0筆記——用戶行為數據采集四
2022-07-23 11:44:00 【絲絲呀】
1 日志采集Flume安裝

[[email protected] software]$ tar -zxvf apache-flume-1.9.0-bin.tar.gz -C /opt/module/
[[email protected] module]$ mv apache-flume-1.9.0-bin/ flume
將lib文件夾下的guava-11.0.2.jar删除以兼容Hadoop 3.1.3
[[email protected] module]$ rm /opt/module/flume/lib/guava-11.0.2.jar

hadoop能正常工作

將flume/conf下的flume-env.sh.template文件修改為flume-env.sh,並配置flume-env.sh文件
[[email protected] conf]$ mv flume-env.sh.template flume-env.sh

[[email protected] conf]$ vi flume-env.sh
export JAVA_HOME=/opt/module/jdk1.8.0_212

分發
[[email protected] module]$ xsync flume/



2 日志采集Flume配置

Flume的具體配置如下:
在/opt/module/flume/conf目錄下創建file-flume-kafka.conf文件
[[email protected] conf]$ vim file-flume-kafka.conf
在文件配置如下內容(先寫下,之後再配置)
#為各組件命名
a1.sources = r1
a1.channels = c1
#描述source
a1.sources.r1.type = TAILDIR
a1.sources.r1.filegroups = f1
a1.sources.r1.filegroups.f1 = /opt/module/applog/log/app.*
a1.sources.r1.positionFile = /opt/module/flume/taildir_position.json
#配置攔截器(ETL數據清洗 判斷json是否完整)
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = com.zhang.flume.interceptor.ETLInterceptor$Builder
#描述channel
a1.channels.c1.type = org.apache.flume.channel.kafka.KafkaChannel
a1.channels.c1.kafka.bootstrap.servers = hadoop102:9092,hadoop103:9092
a1.channels.c1.kafka.topic = topic_log
a1.channels.c1.parseAsFlumeEvent = false
#綁定source和channel以及sink和channel的關系
a1.sources.r1.channels = c1
創建Maven工程flume-interceptor

<dependencies>
<dependency>
<groupId>org.apache.flume</groupId>
<artifactId>flume-ng-core</artifactId>
<version>1.9.0</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.62</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<artifactId>maven-compiler-plugin</artifactId>
<version>2.3.2</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
創建包名:com.zhang.flume.interceptor
在com.zhang.flume.interceptor包下創建JSONUtils類
package com.zhang.flume.interceptor;
import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.JSONException;
public class JSONUtils {
public static boolean isJSONValidate(String log){
try {
JSON.parse(log);
return true;
}catch (JSONException e){
return false;
}
}
}

在com.zhang.flume.interceptor包下創建ETLInterceptor 類 
package com.zhang.flume.interceptor;
import com.alibaba.fastjson.JSON;
import org.apache.flume.Context;
import org.apache.flume.Event;
import org.apache.flume.interceptor.Interceptor;
import java.nio.charset.StandardCharsets;
import java.util.Iterator;
import java.util.List;
public class ETLInterceptor implements Interceptor {
@Override
public void initialize() {
}
@Override
public Event intercept(Event event) {
byte[] body = event.getBody();
String log = new String(body, StandardCharsets.UTF_8);
if (JSONUtils.isJSONValidate(log)) {
return event;
} else {
return null;
}
}
@Override
public List<Event> intercept(List<Event> list) {
Iterator<Event> iterator = list.iterator();
while (iterator.hasNext()){
Event next = iterator.next();
if(intercept(next)==null){
iterator.remove();
}
}
return list;
}
public static class Builder implements Interceptor.Builder{
@Override
public Interceptor build() {
return new ETLInterceptor();
}
@Override
public void configure(Context context) {
}
}
@Override
public void close() {
}
}

打包編譯




需要先將打好的包放入到hadoop102的/opt/module/flume/lib文件夾下面。
[[email protected] module]$ cd flume/lib/
上傳文件
過濾一下:
[[email protected] lib]$ ls | grep interceptor

分發
[[email protected] lib]$ xsync flume-interceptor-1.0-SNAPSHOT-jar-with-dependencies.jar

拿到全類名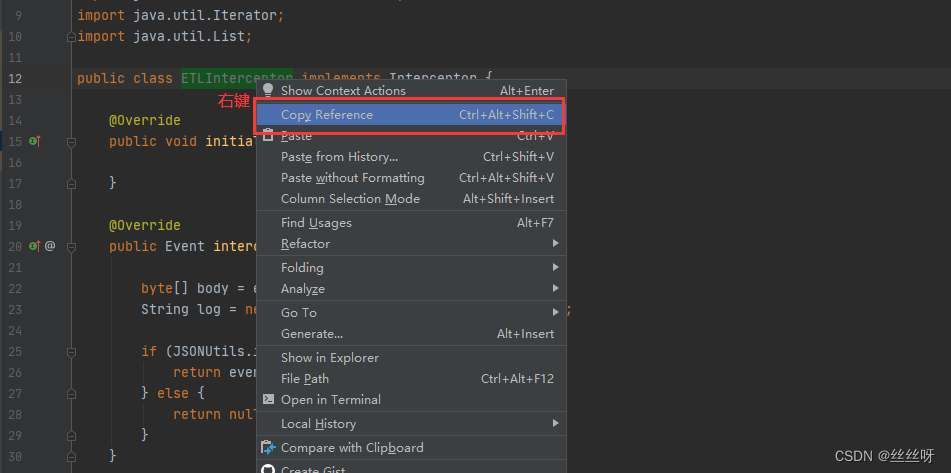
放在最開始的配置文件這個比特置:

現在把配置文件放在集群上
[[email protected] conf]$ vim file-flume-kafka.conf

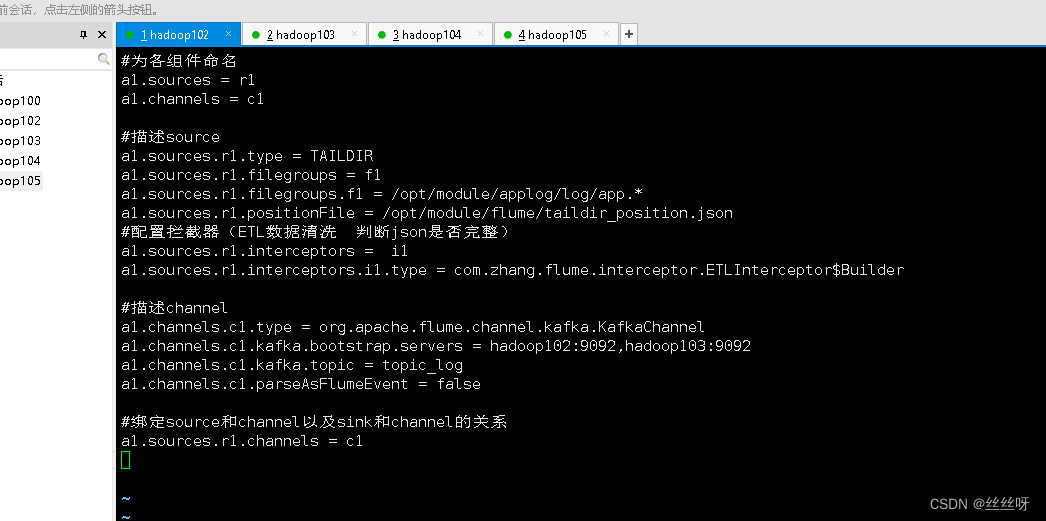
分發[[email protected] conf]$ xsync file-flume-kafka.conf

啟動flume
[[email protected] flume]$ bin/flume-ng agent --name a1 --conf-file conf/file-flume-kafka.conf &


[[email protected] flume]$ bin/flume-ng agent --name a1 --conf-file conf/file-flume-kafka.conf &

103也啟動成功。
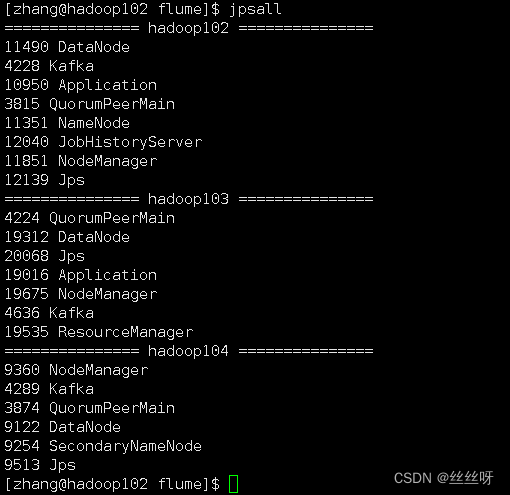
3 測試Flume-Kafka通道
生成日志
[[email protected] flume]$ lg.sh
消費Kafka數據,觀察控制臺是否有數據獲取到:
[[email protected] kafka]$ bin/kafka-console-consumer.sh \
--bootstrap-server hadoop102:9092 --from-beginning --topic topic_log
能看到對應的日志

如果差了hadoop102窗口,發現flume就被關閉了
[[email protected] ~]$ cd /opt/module/flume/
在前臺啟動
[[email protected] flume]$ bin/flume-ng agent --name a1 --conf-file conf/file-flume-kafka.conf

啟動成功,但是關閉客戶端發現又被關閉了
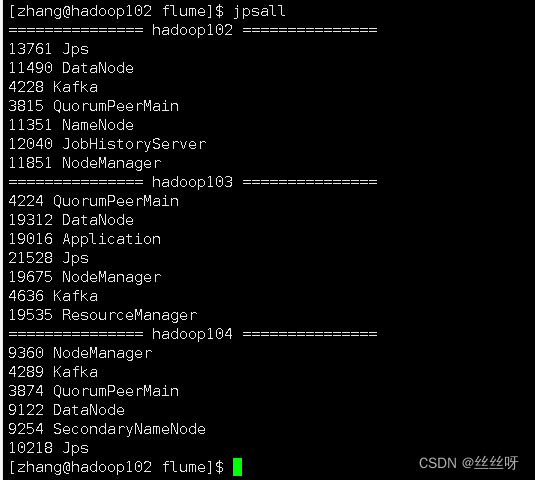
加上nohup
[[email protected] flume]$ nohup bin/flume-ng agent --name a1 --conf-file conf/file-flume-kafka.conf

nohup,該命令可以在你退出帳戶/關閉終端之後繼續運行相應的進程。nohup就是不掛起的意思,不掛斷地運行命令。
怎麼停止?……如何獲得號13901?
[[email protected] kafka]$ ps -ef | grep Application
[[email protected] kafka]$ ps -ef | grep Application | grep -v grep
[[email protected] kafka]$ ps -ef | grep Application | grep -v grep | awk '{print $2}'

[[email protected] kafka]$ ps -ef | grep Application | grep -v grep | awk '{print $2}' | xargs

[[email protected] kafka]$ ps -ef | grep Application | grep -v grep | awk '{print $2}' | xargs -n1 kill -9

Application可能會被其他相同的名字代替,所以要找一個能够唯一標識flume的標志



4 日志采集Flume啟動停止脚本
在/home/atguigu/bin目錄下創建脚本f1.sh
[[email protected] bin]$ vim f1.sh
在脚本中填寫如下內容
#! /bin/bash
case $1 in
"start"){
for i in hadoop102 hadoop103
do
echo " --------啟動 $i 采集flume-------"
ssh $i "nohup /opt/module/flume/bin/flume-ng agent --conf-file /opt/module/flume/conf/file-flume-kafka.conf --name a1 -Dflume.root.logger=INFO,LOGFILE >/opt/module/flume/log1.txt 2>&1 &"
done
};;
"stop"){
for i in hadoop102 hadoop103
do
echo " --------停止 $i 采集flume-------"
ssh $i "ps -ef | grep file-flume-kafka | grep -v grep |awk '{print \$2}' | xargs -n1 kill -9 "
done
};;
esac

[[email protected] bin]$ chmod 777 f1.sh
測試一下停止和啟動正常

5 消費Kafka數據Flume


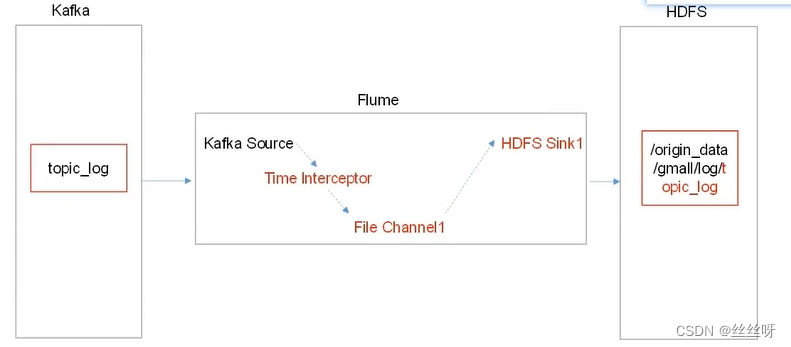
時間攔截器很重要,解决零點漂移問題
消費者Flume配置
在hadoop104的/opt/module/flume/conf目錄下創建kafka-flume-hdfs.conf文件
(獲取到a1.sources.r1.interceptors.i1.type之後再配置)
[[email protected] conf]$ vim kafka-flume-hdfs.conf
## 組件
a1.sources=r1
a1.channels=c1
a1.sinks=k1
## source1
a1.sources.r1.type = org.apache.flume.source.kafka.KafkaSource
a1.sources.r1.batchSize = 5000
a1.sources.r1.batchDurationMillis = 2000
a1.sources.r1.kafka.bootstrap.servers = hadoop102:9092,hadoop103:9092,hadoop104:9092
a1.sources.r1.kafka.topics=topic_log
##時間攔截器
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = com.zhang.flume.interceptor.TimeStampInterceptor$Builder
## channel1
a1.channels.c1.type = file
a1.channels.c1.checkpointDir = /opt/module/flume/checkpoint/behavior1
a1.channels.c1.dataDirs = /opt/module/flume/data/behavior1/
## sink1
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = /origin_data/gmall/log/topic_log/%Y-%m-%d
a1.sinks.k1.hdfs.filePrefix = log-
a1.sinks.k1.hdfs.round = false
#控制生成的小文件
a1.sinks.k1.hdfs.rollInterval = 10
a1.sinks.k1.hdfs.rollSize = 134217728
a1.sinks.k1.hdfs.rollCount = 0
## 控制輸出文件是原生文件。
a1.sinks.k1.hdfs.fileType = CompressedStream
a1.sinks.k1.hdfs.codeC = lzop
## 拼裝
a1.sources.r1.channels = c1
a1.sinks.k1.channel= c1
Flume時間戳攔截器(解决零點漂移問題)
在com.zhang.flume.interceptor包下創建TimeStampInterceptor類
package com.zhang.flume.interceptor;
import com.alibaba.fastjson.JSONObject;
import org.apache.flume.Context;
import org.apache.flume.Event;
import org.apache.flume.interceptor.Interceptor;
import java.nio.charset.StandardCharsets;
import java.util.ArrayList;
import java.util.List;
import java.util.Map;
public class TimeStampInterceptor implements Interceptor {
private ArrayList<Event> events = new ArrayList<>();
@Override
public void initialize() {
}
@Override
public Event intercept(Event event) {
Map<String, String> headers = event.getHeaders();
String log = new String(event.getBody(), StandardCharsets.UTF_8);
JSONObject jsonObject = JSONObject.parseObject(log);
String ts = jsonObject.getString("ts");
headers.put("timestamp", ts);
return event;
}
@Override
public List<Event> intercept(List<Event> list) {
events.clear();
for (Event event : list) {
events.add(intercept(event));
}
return events;
}
@Override
public void close() {
}
public static class Builder implements Interceptor.Builder {
@Override
public Interceptor build() {
return new TimeStampInterceptor();
}
@Override
public void configure(Context context) {
}
}
}


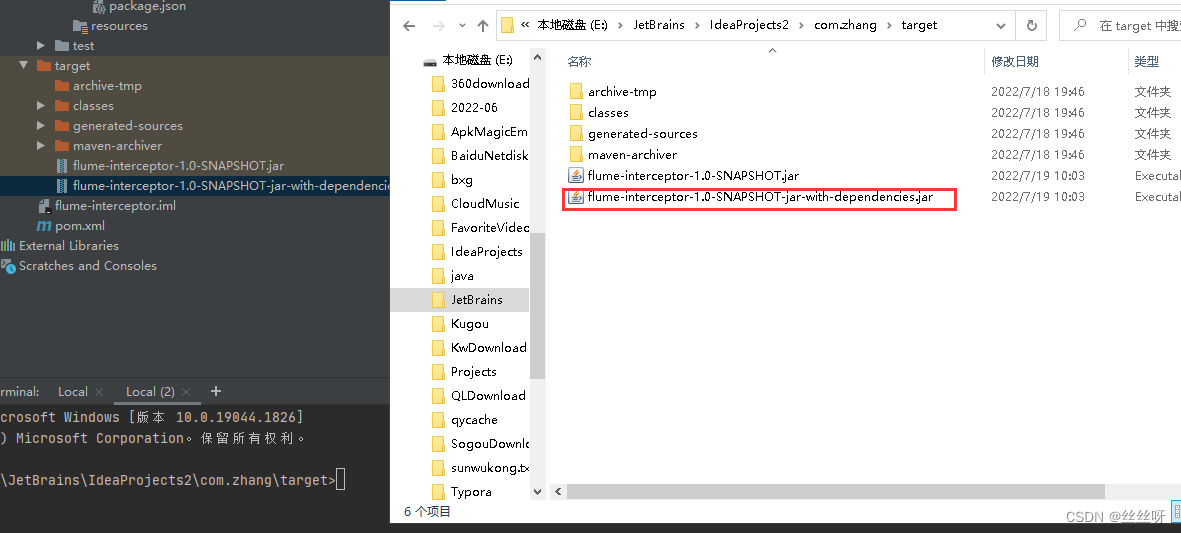
來到hadoop104上:

傳送文件
查看一下在不在
[[email protected] lib]$ ls | grep interceptor

删除之前的
[[email protected] lib]$ rm -rf flume-interceptor-1.0-SNAPSHOT-jar-with-dependencies.jar.0
注意:建議查看一下時間,這裏.0是新生成的文件,不是以前的。
補齊之前寫的脚本
com.zhang.flume.interceptor.TimeStampInterceptor
現在開始寫配置文件

啟動flume
[[email protected] flume]$ nohup /opt/module/flume/bin/flume-ng agent --conf-file /opt/module/flume/conf/kafka-flume-hdfs.conf --name a1 -Dflume.root.logger=INFO,LOGFILE >/opt/module/flume/log2.txt 2>&1 &

查看一下日期(104上)

再看一下102上的之前配置的日志日期


現在再來看一下HDFS中取的日期是日志對應的時間,還是104這臺機器對應的系統時間
先打開HDFS 
[[email protected] applog]$ lg.sh

查看時間,就是日志對應的時間

小插曲:最開始我的origin_data文件,怎麼都不出來,但是我是跟著視頻一步一步來的,最終發現問題:
導入jar包的時候,flume-interceptor-1.0-SNAPSHOT-jar-with-dependencies.jar文件是之前的,.0的文件才是最新文件,所以應該删除前面的文件,留下.0文件。當然出現問題之後直接回去重新删除jar包,重新導入就可以了。
消費者Flume啟動停止脚本
在/home/zhang/bin目錄下創建脚本f2.sh
[[email protected] bin]$ vim f2.sh
在脚本中填寫如下內容
#! /bin/bash
case $1 in
"start"){
for i in hadoop104
do
echo " --------啟動 $i 消費flume-------"
ssh $i "nohup /opt/module/flume/bin/flume-ng agent --conf-file /opt/module/flume/conf/kafka-flume-hdfs.conf --name a1 -Dflume.root.logger=INFO,LOGFILE >/opt/module/flume/log2.txt 2>&1 &"
done
};;
"stop"){
for i in hadoop104
do
echo " --------停止 $i 消費flume-------"
ssh $i "ps -ef | grep kafka-flume-hdfs | grep -v grep |awk '{print \$2}' | xargs -n1 kill"
done
};;
esac
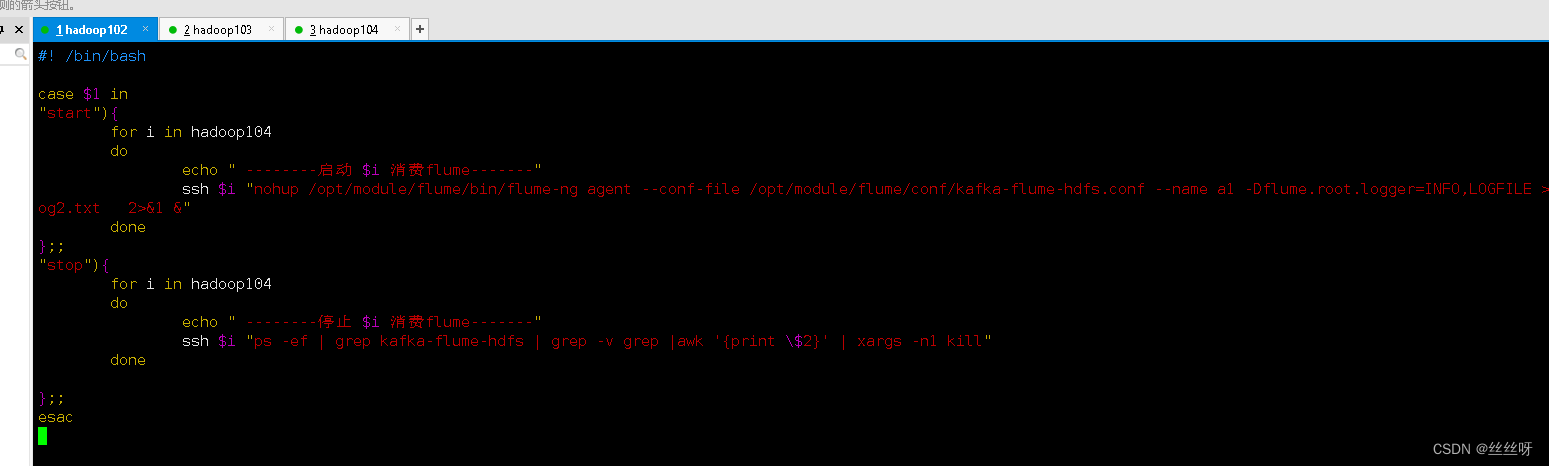
[[email protected] bin]$ chmod 777 f2.sh


項目經驗之Flume內存優化
修改flume內存參數設置


6 采集通道啟動/停止脚本
在/home/zhang/bin目錄下創建脚本cluster.sh
[[email protected] bin]$ vim cluster.sh
在脚本中填寫如下內容 (注意關閉順序,停止Kafka需要一定的時間,如果關閉Kafka緊接著關閉Zookeeper,可能會由於延時問題,不能正常關閉)
#!/bin/bash
case $1 in
"start"){
echo ================== 啟動 集群 ==================
#啟動 Zookeeper集群
zk.sh start
#啟動 Hadoop集群
myhadoop.sh start
#啟動 Kafka采集集群
kf.sh start
#啟動 Flume采集集群
f1.sh start
#啟動 Flume消費集群
f2.sh start
};;
"stop"){
echo ================== 停止 集群 ==================
#停止 Flume消費集群
f2.sh stop
#停止 Flume采集集群
f1.sh stop
#停止 Kafka采集集群
kf.sh stop
#停止 Hadoop集群
myhadoop.sh stop
#停止 Zookeeper集群
zk.sh stop
};;
esac
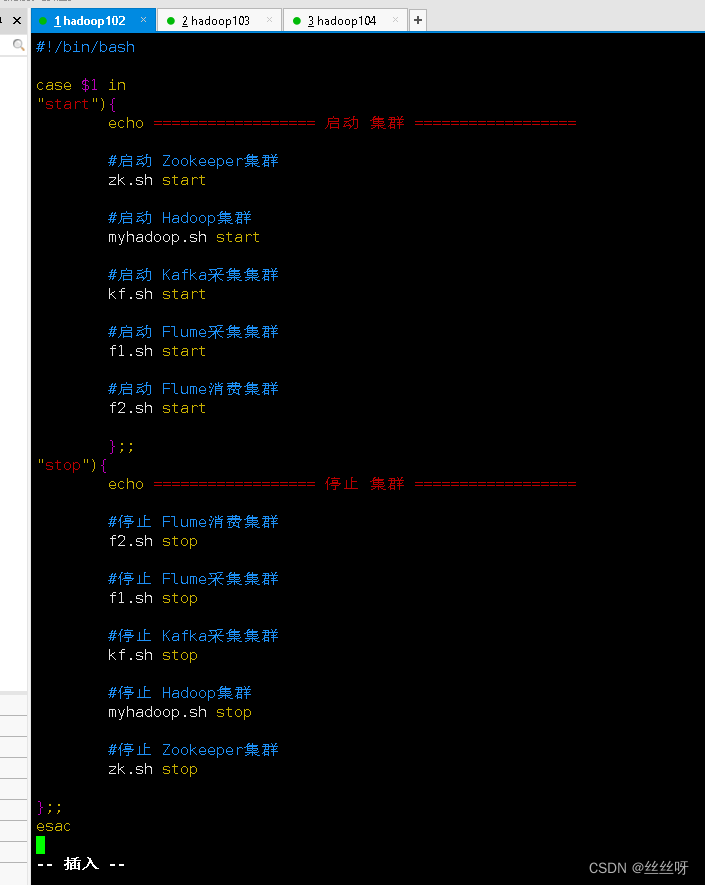
[[email protected] bin]$ chmod 777 cluster.sh
能够正常關閉,啟動


7 常見問題及解决方案
訪問2NN頁面http://hadoop104:9868,看不到詳細信息


找到要修改的文件
[[email protected] ~]$ cd /opt/module/hadoop-3.1.3/share/hadoop/hdfs/webapps/static/

[[email protected] static]$ vim dfs-dust.js

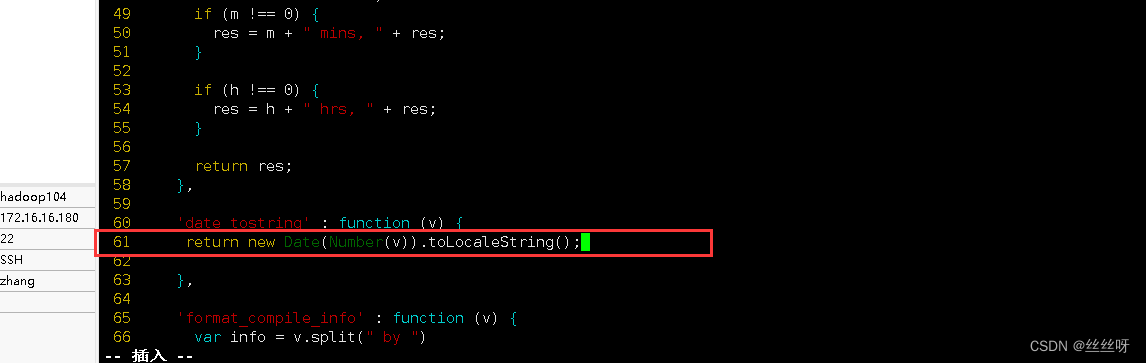
找到61行
修改61行
return new Date(Number(v)).toLocaleString();
强制刷新(更多工具——清空瀏覽器——清除數據)

边栏推荐
- [metric] use Prometheus to monitor flink1.13org.apache.flink.metrics
- 数字藏品系统开发:企业布局元宇宙数字藏品
- NFT digital collection system development: the combination of music and NFT
- Bank of Indonesia governor said the country is actively exploring encrypted assets
- Accumulate SQL by date
- Scala之二流程控制
- window运行gradle build -- --stacktrace出现找不到文件framework-4.3.0.BUILD-SNAPSHOT-schema.zip异常
- Customized development of ant chain NFT digital collection DAPP mall system
- The difference between slice() and slice()
- ETH转账次数达到一个月高点
猜你喜欢

美联储布拉德:上周就业报告表明美国经济稳健,可以承受更高的利率

NFT交易平台数字藏品系统|开发定制

Nepctf 2022 misc < check in question > (extreme doll)
![[metric] use Prometheus to monitor flink1.13org.apache.flink.metrics](/img/9a/f6ef8de9943ec8e716388ae6620600.png)
[metric] use Prometheus to monitor flink1.13org.apache.flink.metrics
quartz2.2简单调度Job

Using dynamic programming to solve the longest growing subsequence problem

Entrepôt de données 4.0 Notes - acquisition de données commerciales

sqli-lab第17~22关通关随笔记
数仓4.0笔记——用户行为数据采集四

Genesis曾向三箭资本提供23.6亿美元的贷款
随机推荐
Shell takes the month within a certain time range
CTF web common software installation and environment construction
第六届“蓝帽杯”全国大学生网络安全技能大赛-初赛Writeup
NepCTF2022 Writeup
Goodbye if else
notepad++背景颜色调整选项中文释义
美联储布拉德:上周就业报告表明美国经济稳健,可以承受更高的利率
用户连续登陆(允许中断)查询sql
Customize foreach tags & select tags to echo data
[deployment] cluster deployment and startup of presto-server-0.261.tar.gz
Laravel API interface + token authentication login
Digital collection development / meta universe digital collection development
sql实现连续登陆7天以上用户统计
NFT交易平台数字藏品系统|开发定制
蚂蚁链NFT数字藏品DAPP商城系统定制开发
mysql树形结构递归查询
ES操作命令
数仓4.0笔记——用户行为数据采集四
How to customize JSP Tags
Custom formula input box