当前位置:网站首页>Tensorflow2.4 implementation of repvgg
Tensorflow2.4 implementation of repvgg
2022-06-30 20:10:00 【Haohao+++】
Preface
RepVGG It's Tsinghua University & Kuangshi technology, etc. proposed a novel CNN Design paradigm , Avoided VGG The problem of low accuracy of class method training , Again VGG The advantages of efficient reasoning .
Address of thesis : https://arxiv.org/abs/2101.03697
The blog comes up with two important ways .
Training multi branch structures
ResNet In structure ResBlock It uses y = x + f ( x ) y=x+f(x) y=x+f(x), Although multi branch structure is not friendly to reasoning , But training friendly , The author will RepVGG Designed as a multi branch for training , Single branch structure in reasoning . The author refers to ResNet Of identity And 1 × 1 1\times1 1×1 Branch , The following formal modules are designed :
y = x + g ( x ) + f ( x ) y=x+g(x)+f(x) y=x+g(x)+f(x)
among :
- g ( x ) g(x) g(x) by 1x1 Convolution .
- f ( x ) f(x) f(x) by 3x3 Convolution .
Simple is fast , Memory economy , flexible
- Fast: comparison VGG, The existing multi - Branch architecture has lower Flops, But reasoning is not faster . such as VGG16 The parameter of is EfficientNetB3 Of 8.4 times , But in 1080Ti On the contrary, the reasoning speed is faster 1.8 times . This means that the computational density of the former is that of the latter 15 times .Flops The contradiction with reasoning speed mainly stems from two key factors :(1) MAC(memory access cose), For example, multi branch structure Add And Cat The calculation of is very small , but MAC Very high ; (2) Parallelism , Studies have shown that : The model with high parallelism has faster reasoning speed than the model with low parallelism .
- Memory-economical: Multi branch architecture is a memory inefficient architecture , This is because the structure of each branch needs to be in Add/Concat Save before , This results in a larger peak memory footprint ; and plain The model has better memory efficiency .
- Flexible: Multi branch structure will limit CNN The flexibility of the , such as ResBlock Will constrain two branches tensor They have the same shape ; meanwhile , Multi branch structure is not friendly to model pruning .
Network structure


Code implementation
from tensorflow.keras.models import Model
from tensorflow.keras.layers import (
Conv2D, BatchNormalization, GlobalAvgPool2D, Activation, Multiply,
Add, Dense, Input
)
# ----------------- #
# Convolution + Standardization
# ----------------- #
def conv_bn(filters, kernel_size, strides, padding, groups=1):
def _conv_bn(x):
x = Conv2D(filters=filters, kernel_size=kernel_size, strides=strides,
padding=padding, groups=groups, use_bias=False)(x)
x = BatchNormalization()(x)
return x
return _conv_bn
# ----------------- #
# SE modular
# ----------------- #
def SE_block(x_0, r = 16):
channels = x_0.shape[-1]
x = GlobalAvgPool2D()(x_0)
# (?, ?) -> (?, 1, 1, ?)
x = x[:, None, None, :]
# use 2 individual 1x1 Convolution instead of full connection
x = Conv2D(filters=channels//r, kernel_size=1, strides=1)(x)
x = Activation('relu')(x)
x = Conv2D(filters=channels, kernel_size=1, strides=1)(x)
x = Activation('sigmoid')(x)
x = Multiply()([x_0, x])
return x
# ----------------- #
# RepVGG modular
# ----------------- #
def RepVGGBlock(filters, kernel_size, strides=1, padding='valid', dilation=1, groups=1, deploy=False, use_se=False):
def _RepVGGBlock(inputs):
if deploy:
if use_se:
x = Conv2D(filters=filters, kernel_size=kernel_size, strides=strides,
padding=padding, dilation_rate=dilation, groups=groups, use_bias=True)(inputs)
x = SE_block(x)
x = Activation('relu')(x)
else:
x = Conv2D(filters=filters, kernel_size=kernel_size, strides=strides,
padding=padding, dilation_rate=dilation, groups=groups, use_bias=True)(inputs)
x = Activation('relu')(x)
return x
if inputs.shape[-1] == filters and strides == 1:
if use_se:
id_out = BatchNormalization()(inputs)
x1 = conv_bn(filters=filters, kernel_size=kernel_size, strides=strides, padding=padding, groups=groups)(inputs)
x2 = conv_bn(filters=filters, kernel_size=1, strides=strides, padding=padding, groups=groups)(inputs)
x3 = Add()([id_out, x1, x2])
x4 = SE_block(x3)
return Activation('relu')(x4)
else:
id_out = BatchNormalization()(inputs)
x1 = conv_bn(filters=filters, kernel_size=kernel_size, strides=strides, padding=padding, groups=groups)(inputs)
x2 = conv_bn(filters=filters, kernel_size=1, strides=strides, padding=padding, groups=groups)(inputs)
x3 = Add()([id_out, x1, x2])
return Activation('relu')(x3)
else:
if use_se:
x1 = conv_bn(filters=filters, kernel_size=kernel_size, strides=strides, padding=padding, groups=groups)(inputs)
x2 = conv_bn(filters=filters, kernel_size=1, strides=strides, padding='valid', groups=groups)(inputs)
x3 = Add()([x1, x2])
x4 = SE_block(x3)
return Activation('relu')(x4)
else:
x1 = conv_bn(filters=filters, kernel_size=kernel_size, strides=strides, padding=padding, groups=groups)(inputs)
x2 = conv_bn(filters=filters, kernel_size=1, strides=strides, padding='valid', groups=groups)(inputs)
x3 = Add()([x1, x2])
return Activation('relu')(x3)
return _RepVGGBlock
# ----------------- #
# RepVGG Stacking of modules
# ----------------- #
def make_stage(planes, num_blocks, stride_1,deploy,use_se, override_groups_map=None):
def _make_stage(x):
cur_layer_id=1
strides = [stride_1] + [1]*(num_blocks-1)
for stride in strides:
cur_groups = override_groups_map.get(cur_layer_id, 1)
x = RepVGGBlock(filters=planes, kernel_size=3, strides=stride, padding='same',
groups=cur_groups, deploy=deploy, use_se=use_se)(x)
cur_layer_id += 1
return x
return _make_stage
# ----------------- #
# RepVGG The Internet
# ----------------- #
def RepVGG(x, num_blocks, classes=1000, width_multiplier=None, override_groups_map=None, deploy=False, use_se=False):
override_groups_map = override_groups_map or dict()
in_planes = min(64, int(64 * width_multiplier[0]))
out = RepVGGBlock(filters=in_planes, kernel_size=3, strides=2, padding='same', deploy=deploy, use_se=use_se)(x)
out = make_stage(int(64 * width_multiplier[0]), num_blocks[0], stride_1=2, deploy=deploy, use_se=use_se, override_groups_map=override_groups_map)(out)
out = make_stage(int(128 * width_multiplier[1]), num_blocks[1], stride_1=2, deploy=deploy, use_se=use_se, override_groups_map=override_groups_map)(out)
out = make_stage(int(256 * width_multiplier[2]), num_blocks[2], stride_1=2, deploy=deploy, use_se=use_se, override_groups_map=override_groups_map)(out)
out = make_stage(int(512 * width_multiplier[3]), num_blocks[3], stride_1=2, deploy=deploy, use_se=use_se, override_groups_map=override_groups_map)(out)
out = GlobalAvgPool2D()(out)
out = Dense(classes)(out)
return out
optional_groupwise_layers = [2, 4, 6, 8, 10, 12, 14, 16, 18, 20, 22, 24, 26]
g2_map = {
l: 2 for l in optional_groupwise_layers}
g4_map = {
l: 4 for l in optional_groupwise_layers}
def RepVGG_A0(inputs,classes=1000, deploy=False):
return RepVGG(inputs, num_blocks=[2, 4, 14, 1], classes=classes,
width_multiplier=[0.75, 0.75, 0.75, 2.5], override_groups_map=None, deploy=deploy)
def create_RepVGG_A1(x, deploy=False):
return RepVGG(x, num_blocks=[2, 4, 14, 1], classes=1000,
width_multiplier=[1, 1, 1, 2.5], override_groups_map=None, deploy=deploy)
def create_RepVGG_A2(x, deploy=False):
return RepVGG(x, num_blocks=[2, 4, 14, 1], num_classes=1000,
width_multiplier=[1.5, 1.5, 1.5, 2.75], override_groups_map=None, deploy=deploy)
def create_RepVGG_B0(x, deploy=False):
return RepVGG(x, num_blocks=[4, 6, 16, 1], num_classes=1000,
width_multiplier=[1, 1, 1, 2.5], override_groups_map=None, deploy=deploy)
def create_RepVGG_B1(x, deploy=False):
return RepVGG(x, num_blocks=[4, 6, 16, 1], num_classes=1000,
width_multiplier=[2, 2, 2, 4], override_groups_map=None, deploy=deploy)
def create_RepVGG_B1g2(x, deploy=False):
return RepVGG(x, num_blocks=[4, 6, 16, 1], num_classes=1000,
width_multiplier=[2, 2, 2, 4], override_groups_map=g2_map, deploy=deploy)
def create_RepVGG_B1g4(x, deploy=False):
return RepVGG(x, num_blocks=[4, 6, 16, 1], num_classes=1000,
width_multiplier=[2, 2, 2, 4], override_groups_map=g4_map, deploy=deploy)
def create_RepVGG_B2(x, deploy=False):
return RepVGG(x, num_blocks=[4, 6, 16, 1], num_classes=1000,
width_multiplier=[2.5, 2.5, 2.5, 5], override_groups_map=None, deploy=deploy)
def create_RepVGG_B2g2(x, deploy=False):
return RepVGG(x, num_blocks=[4, 6, 16, 1], num_classes=1000,
width_multiplier=[2.5, 2.5, 2.5, 5], override_groups_map=g2_map, deploy=deploy)
def create_RepVGG_B2g4(x, deploy=False):
return RepVGG(x, num_blocks=[4, 6, 16, 1], num_classes=1000,
width_multiplier=[2.5, 2.5, 2.5, 5], override_groups_map=g4_map, deploy=deploy)
def create_RepVGG_B3(x, deploy=False):
return RepVGG(x, num_blocks=[4, 6, 16, 1], num_classes=1000,
width_multiplier=[3, 3, 3, 5], override_groups_map=None, deploy=deploy)
def create_RepVGG_B3g2(x, deploy=False):
return RepVGG(x, num_blocks=[4, 6, 16, 1], num_classes=1000,
width_multiplier=[3, 3, 3, 5], override_groups_map=g2_map, deploy=deploy)
def create_RepVGG_B3g4(x, deploy=False):
return RepVGG(x, num_blocks=[4, 6, 16, 1], num_classes=1000,
width_multiplier=[3, 3, 3, 5], override_groups_map=g4_map, deploy=deploy)
def create_RepVGG_D2se(x, deploy=False):
return RepVGG(x, num_blocks=[8, 14, 24, 1], num_classes=1000,
width_multiplier=[2.5, 2.5, 2.5, 5], override_groups_map=None, deploy=deploy, use_se=True)
if __name__ == '__main__':
inputs = Input(shape=(224,224,3))
classes = 1000
model = Model(inputs=inputs, outputs=RepVGG_A0(inputs))
model.summary()
~ Welcome to correct
边栏推荐
猜你喜欢

exness:流动性系列-流动性清洗和反转、决策区间

8 - 函数

台湾SSS鑫创SSS1700替代Cmedia CM6533 24bit 96KHZ USB音频编解码芯片

标配10个安全气囊,奇瑞艾瑞泽8安全防护无死角
Exness: liquidity series - liquidity cleaning and reversal, decision interval

Spark - 一文搞懂 Partitioner

Audio and video architecture construction in the super video era | science and Intel jointly launched the second season of "architect growth plan"
![[solved] how does Tiktok cancel paying attention to the cancelled account](/img/1f/7b0bd2c0f69f7f3d1c25c426cc5771.png)
[solved] how does Tiktok cancel paying attention to the cancelled account
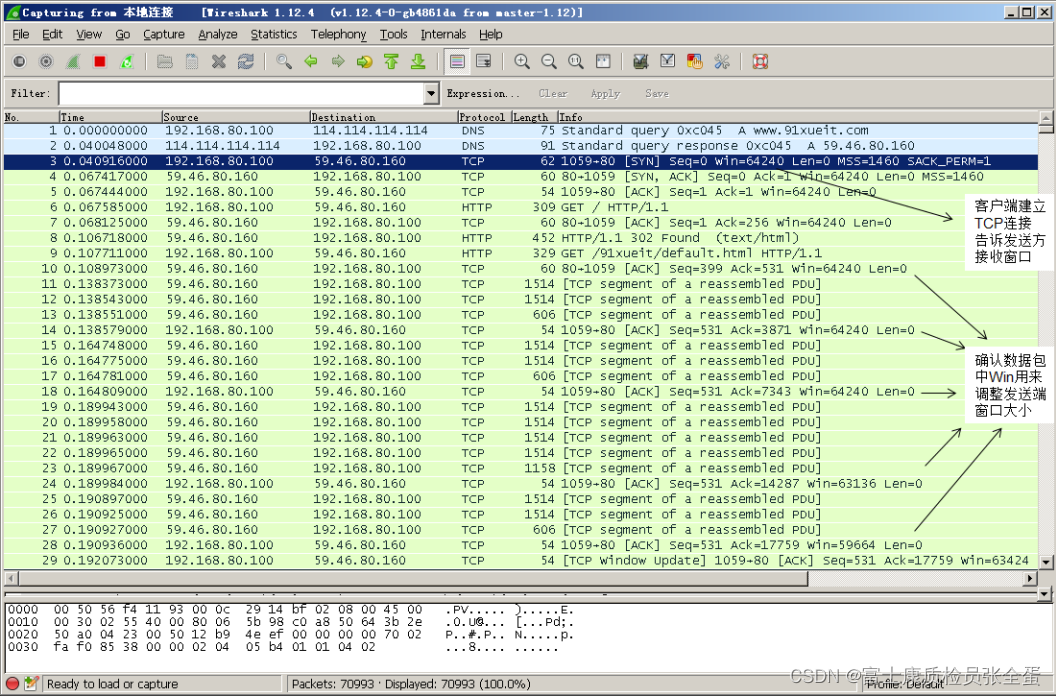
传输层 使用滑动窗口实现流量控制

企业中台规划和IT架构微服务转型
随机推荐
MySQL数据库误删回滚的解决
QT :QAxObject操作Excel
Why must we move from Devops to bizdevops?
Data intelligence - dtcc2022! China database technology conference is about to open
昔日果汁大王,16个亿卖了
Taihu Lake "China's healthy agricultural products · mobile phone live broadcast" enters Taihu Lake
exness:美GDP终值意外加速萎缩1.6%
Solution to rollback of MySQL database by mistake deletion
Summary of operating system interview questions (updated from time to time)
QQmlApplicationEngine failed to load component qrc:/main.qml:-1 No such file or directory
CADD课程学习(1)-- 药物设计基础知识
Idle fish is hard to turn over
PS2手柄-1「建议收藏」
yolo 目标检测
Growth summer challenge is coming, exclusive community welfare is coming ~ get CSDN customized T-shirt for free
WeakSet
如何使用robots.txt及其详解
Warmup预热学习率「建议收藏」
屏幕显示技术进化史
【论文阅读】Trajectory-guided Control Prediction for End-to-end Autonomous Driving: A Simple yet Strong Baseline