当前位置:网站首页>李宏毅机器学习(2017版)_P6-8:梯度下降
李宏毅机器学习(2017版)_P6-8:梯度下降
2022-07-26 22:42:00 【北海虽赊,扶摇可接】
目录

相关资料
开源内容:https://linklearner.com/datawhale-homepage/index.html#/learn/detail/13
开源内容:https://github.com/datawhalechina/leeml-notes
开源内容:https://gitee.com/datawhalechina/leeml-notes
视频地址:https://www.bilibili.com/video/BV1Ht411g7Ef
官方地址:http://speech.ee.ntu.edu.tw/~tlkagk/courses.html
1、梯度下降(Gradient Descent)定义
损失函数最小值求解:
θ ∗ = a r g min min L ( θ ) \theta^{*}=arg \min \min L(\theta) θ∗=argminminL(θ)
L : l o s s f u n c t i o n (损失函数) θ : p a r a m e t e r s (参数) L :lossfunction(损失函数) \theta :parameters(参数) L:lossfunction(损失函数)θ:parameters(参数)
梯度下降:
分别计算初始点处,两个参数对 L的偏微分,然后 θ 0 \theta^0 θ0减掉 η \eta η(Learning rates(学习速率))乘上偏微分的值,得到一组新的参数。
2、调整学习率
2.1、恒定学习率问题

学习率太小(蓝色的线),损失函数下降的非常慢;学习率太大(绿色的线),损失函数下降很快,但马上就卡住不下降了;学习率特别大(黄色的线),损失函数就飞出去了;红色的就是差不多刚好,可以得到一个好的结果。
2.2、自适应学习率(Adaptive Learning Rates)
随着次数的增加,通过一些因子来减少学习率。
刚开始,初始点会距离最低点比较远,使用大一点的学习率,比较靠近最低点了,减小学习率。
例如: η t = η t t + 1 \eta^{t}= \frac{\eta ^{t}}{\sqrt{t+1}} ηt=t+1ηt,t是次数。随着次数的增加, η t \eta^t ηt减小。
**注意:**学习率不能是一个值通用所有特征,不同的参数需要不同的学习率
3、相关优化算法
3.1、Adagrad 算法
3.1.1、概念
Adagrad算法指每个参数的学习率都把它除上之前微分的均方根。
公式简化如下:
参数更新过程:
3.1.2、理论解释
- 对于单变量函数优化:

如果算出来的微分越大,则距离最低点越远。而且最好的步伐和微分的大小成正比。所以如果踏出去的步伐和微分成正比,它可能是比较好的。
梯度越大,就跟最低点的距离越远。
- 对于多变量函数优化:

最好的迭代步伐是: 一次微分 二次微分 \frac{一次微分}{二次微分} 二次微分一次微分,不止和一次微分成正比,还和二次微分成反比。
对于Adagrad算法,分母 ∑ i = 0 t ( g i ) 2 \sqrt{\sum _{i=0}^{t}(g^{i})^{2}} ∑i=0t(gi)2就是希望在尽可能不增加过多运算的情况下模拟二次微分。(如果计算二次微分,在实际情况中可能会增加很多的时间消耗)。
3.2、随机梯度下降法(Stochastic Gradient Descent)
随机梯度下降法损失函数不需要处理训练集所有的数据,而是选取一个例子 x n x^n xn处理(每次仅处理一个数据)。不需要像之前那样对所有的数据进行处理,只需要计算某一个例子的损失函数 L n Ln Ln,就可以更新梯度。
L = ( y ^ n − ( b + ∑ i w i x i n ) ) 2 L=(\widehat{y}^{n}-(b+ \sum _{i}w_{i}x_{i}^{n}))^{2} L=(yn−(b+i∑wixin))2 θ i = θ i − 1 − n ∇ L n ( θ i − 1 ) \theta^{i}= \theta ^{i-1}-n \nabla L^{n}(\theta ^{i-1}) θi=θi−1−n∇Ln(θi−1)
过程对比如下:
3.3、特征缩放(Feature Scaling)
3.3.1、概念
某个函数有多个输入特征,并且输入的特征数据分布的范围很不一样,建议把他们的范围缩放,使得不同输入的范围是一样的。 y = b + w 1 x 1 + w 2 x 2 y=b+w_{1}x_{1}+w_{2}x_{2} y=b+w1x1+w2x2
3.3.2、原因
x 1 x_1 x1对y的变化影响比较小,所以 w 1 w_1 w1对损失函数的影响比较小, w 1 w_1 w1对损失函数有比较小的微分,所以 w 1 w_1 w1方向上是比较平滑的,同理 w 2 w_2 w2方向较陡峭。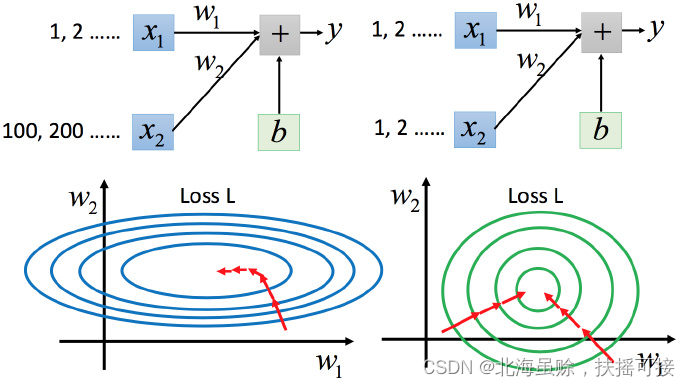
对于左边的情况,上面讲过这种狭长的情形不用Adagrad的话是比较难处理的。
- 两个方向上需要不同的学习率,同一组学习率会搞不定它。而右边情形更新参数就会变得比较容易。
- 左边的梯度下降并不是向着最低点方向走的,而是顺着等高线切线法线方向走的。但绿色就可以向着圆心(最低点)走,这样做参数更新也是比较有效率。
3.3.3、缩放方法
采用批量归一化方法进行缩放,缩放到标准正态分布。
上图每一列都是一个例子,里面都有一组特征。
对每一个维度i(绿色框)都计算平均数,记做 m i m_i mi;还要计算标准差,记做 σ i \sigma _i σi。
然后用第 r(特征)个例子中的第 i(数据)个输入,减掉平均数 m i m_i mi,然后除以标准差 σ i \sigma _i σi,得到的结果是所有的维数都是0,所有的方差都是1。(标准正态分布)
4、梯度下降的理论基础
4.1、下降可视化

在 θ 0 \theta^0 θ0处,可以在一个小范围的圆圈内找到损失函数细小的 θ 1 \theta^1 θ1,不断的这样去寻找。
关键在于如果在小圆圈内快速的找到最小值。
4.2、泰勒展开式
4.2.1、单变量泰勒展开式
若 h ( x ) h(x) h(x)在 x = x 0 x=x_0 x=x0点的某个领域内有无限阶导数(即无限可微分,infinitely differentiable),那么在此领域内有:
当x很接近 x 0 x_0 x0时, h ( x ) ≈ h ( x 0 ) + h ′ ( x 0 ) ( x − x 0 ) h(x)\approx h(x_{0})+h^{\prime}(x_{0})(x-x_{0}) h(x)≈h(x0)+h′(x0)(x−x0)。
4.2.2、多变量泰勒展开式
下面是两个变量的泰勒展开式: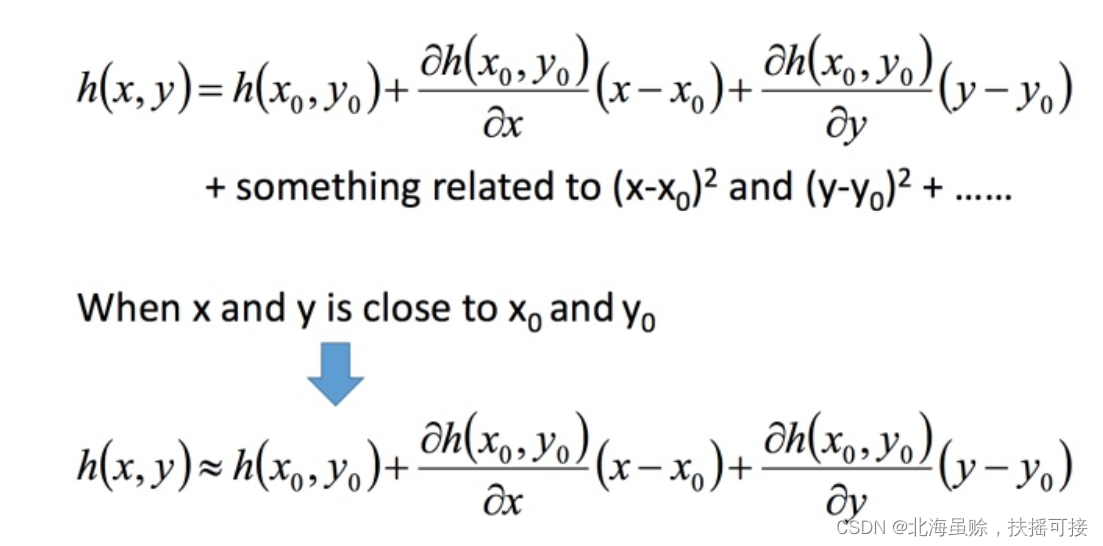
4.3、利用泰勒展开式求解最小值
将损失函数进行泰勒展开,同时略去无穷小项:
简化后如下:
利用向量点乘,求出最小值,推导出GD表达式:
注意:上述推导限制条件如下:
**推导前提:**泰勒展开式给的损失函数的估算值是要足够精确的,而这需要红色的圈圈足够小(也就是学习率足够小)来保证。所以理论上每次更新参数都想要损失函数减小的话,
4.4、梯度下降的限制
容易陷入局部极值 还有可能卡在不是极值,但微分值是0的地方 还有可能实际中只是当微分值小于某一个数值就停下来了,但这里只是比较平缓,并不是极值点。(难以确定真实情况)
边栏推荐
- Spark源码学习——Memory Tuning(内存调优)
- 智密-腾讯云直播 MLVB 插件优化教程:六步提升拉流速度+降低直播延迟
- 使用tika 判断文件类型
- 进入2022年,移动互联网的小程序和短视频直播赛道还有机会吗?
- MySQL索引优化:哪些情况下需要建立索引(适合构建索引的几种情况)
- SparkSql之编程方式
- 视频类小程序变现的最短路径:从带货到品牌营销
- Canal 介绍
- Flink 1.15 implements SQL script to recover data from savepointh
- Real time calculation demo based on Flink: user behavior analysis (IV: how many different users have visited the website (UV) in a period of time)
猜你喜欢

Flink Interval Join源码理解

One of the Flink requirements - processfunction (requirement: alarm if the temperature rises continuously within 30 seconds)
![[SQL注入] 联合查询](/img/82/37008a1ecb4bb37bea42443dbb9be6.png)
[SQL注入] 联合查询

Flink1.11 SQL local run demo & local webui visual solution
![[CTF攻防世界] WEB区 关于备份的题目](/img/af/b78eb3522160896d77d9e82f7e7810.png)
[CTF攻防世界] WEB区 关于备份的题目

Cannot find a valid baseurl for repo: HDP-3.1-repo-1

(Spark调优~)算子的合理选择

Flink 1.15实现 Sql 脚本从savepointh恢复数据

Redis -- cache avalanche, cache penetration, cache breakdown

MySQL index optimization: scenarios where the index fails and is not suitable for indexing
随机推荐
Write the changed data in MySQL to Kafka through flinkcdc (datastream mode)
Flink 1.15 implements SQL script to recover data from savepointh
2022.7.14DAY605
深入理解Pod对象:基本管理
The difference between golang slice make and new
[ciscn2019 finals Day2 web1]easyweb
通过FlinkCDC将MySQL中变更的数据写入到kafka(DataStream方式)
Flink中的状态管理
MLVB 云直播新体验:毫秒级低延迟直播解决方案(附直播性能对比)
Spark data skew solution
Redis -- cache avalanche, cache penetration, cache breakdown
Only hard work, hard work and hard work are the only way out C - patient entity class
Spark On YARN的作业提交流程
Designer mode
解决rsyslog服务占用内存过高
Channel shutdown: channel error; protocol method: #method<channel. close>(reply-code=406, reply-text=
flink需求之—SideOutPut(侧输出流的应用:将温度大于30℃的输出到主流,低于30℃的输出到侧流)
forward和redirect的区别
2022.7.10DAY602
SparkSql之DataFrame