当前位置:网站首页>15.GPU加速、minist测试实战和visdom可视化
15.GPU加速、minist测试实战和visdom可视化
2022-07-27 05:13:00 【派大星的最爱海绵宝宝】
目录
GPU加速
把所有的设备cpu、cuda0、cuda1等,挣到一个设备上。
.cuda()方法会搬到GPU上
.to()方法返回一个新的refoungs,是否一致取决于哪种类型数据。对一个模块使用,则模块整体更新。如果对一个tensor使用,结果不一样。data2=data.cuda(),此时data2和data不一样,会产生两个tensor,一个在cpu上一个在gpu上。
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets, transforms
batch_size=200
learning_rate=0.01
epochs=10
train_loader = torch.utils.data.DataLoader(
datasets.MNIST('mnist_data/', train=True, download=True,
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])),
batch_size=batch_size, shuffle=True)
test_loader = torch.utils.data.DataLoader(
datasets.MNIST('mnist_data/', train=False, transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])),
batch_size=batch_size, shuffle=True)
class MLP(nn.Module):
def __init__(self):
super(MLP, self).__init__()
self.model = nn.Sequential(
nn.Linear(784, 200),
nn.LeakyReLU(inplace=True),
nn.Linear(200, 200),
nn.LeakyReLU(inplace=True),
nn.Linear(200, 10),
nn.LeakyReLU(inplace=True),
)
def forward(self, x):
x = self.model(x)
return x
device = torch.device('cuda:0')
net = MLP().to(device)
optimizer = optim.SGD(net.parameters(), lr=learning_rate)
criteon = nn.CrossEntropyLoss().to(device)
for epoch in range(epochs):
for batch_idx, (data, target) in enumerate(train_loader):
data = data.view(-1, 28*28)
data, target = data.to(device), target.cuda()
logits = net(data)
loss = criteon(logits, target)
optimizer.zero_grad()
loss.backward()
# print(w1.grad.norm(), w2.grad.norm())
optimizer.step()
if batch_idx % 100 == 0:
print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
epoch, batch_idx * len(data), len(train_loader.dataset),
100. * batch_idx / len(train_loader), loss.item()))
test_loss = 0
correct = 0
for data, target in test_loader:
data = data.view(-1, 28 * 28)
data, target = data.to(device), target.cuda()
logits = net(data)
test_loss += criteon(logits, target).item()
pred = logits.data.max(1)[1]
correct += pred.eq(target.data).sum()
test_loss /= len(test_loader.dataset)
print('\nTest set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format(
test_loss, correct, len(test_loader.dataset),
100. * correct / len(test_loader.dataset)))
net=MLP().to(device),CrossEntropyLoss(),data,target=data.to(device),target.cuda(),使用.to()方法把网路搬到GPU上。
minist测试实战
不断train时,它可能会记住样本,此时效果会很好,但是一换其他样本就效果不佳。
对于每一张图片,对其可能是几的概率做softmax,并且做argmax(返回最大值所在索引),返回值即表明他是几。
logits=torch.rand(4,10)
pred=F.softmax(logits,dim=1)
print('pred shape:',pred.shape)
pred_lable=pred.argmax(dim=1)
print('pred_lable:',pred_lable)
print('logits.argmax:',logits.argmax(dim=1))
label=torch.tensor([9,3,2,4])
correct=torch.eq(pred_lable,label)
print('correct',correct)
accuracy=correct.sum().float().item()/4
print(accuracy)
我们得出[5,3,2,1],假设真实是[9,3,2,4],我们需要计算accuracy=2/4=50%。
计算正确的数量,使用eq()函数,如果元素相等返回1。
correct类型是unit8,我们需要使它变成float类型。
when to test
几个batch一个test
每个epoch一个test
vidsom可视化
visdom效率比tensorboard更高一点,因为后者会把数据写到文件中,导致监听文件占据大量空间。
visdom可以直接使用tensor。
使用visdom
1.install
首先进入anaconda prompt,在我们特定环境中输入pip install visdom
2.run server damon
开启监听进程,输入python -m visdom.server
visdom实际上是一个web服务器,开启后,程序向该服务器发送数据,服务器就会把数据渲染到网页上。运行前需要先开启该web服务器。

遇到问题
- pip unstall visdom
- 从官方网页上下载最新的代码,进入下载好的文件内,pip install -e .
- 退回去,开启监听进程
- 复制地址,打开浏览器
功能
lines:single trace
画一个曲线
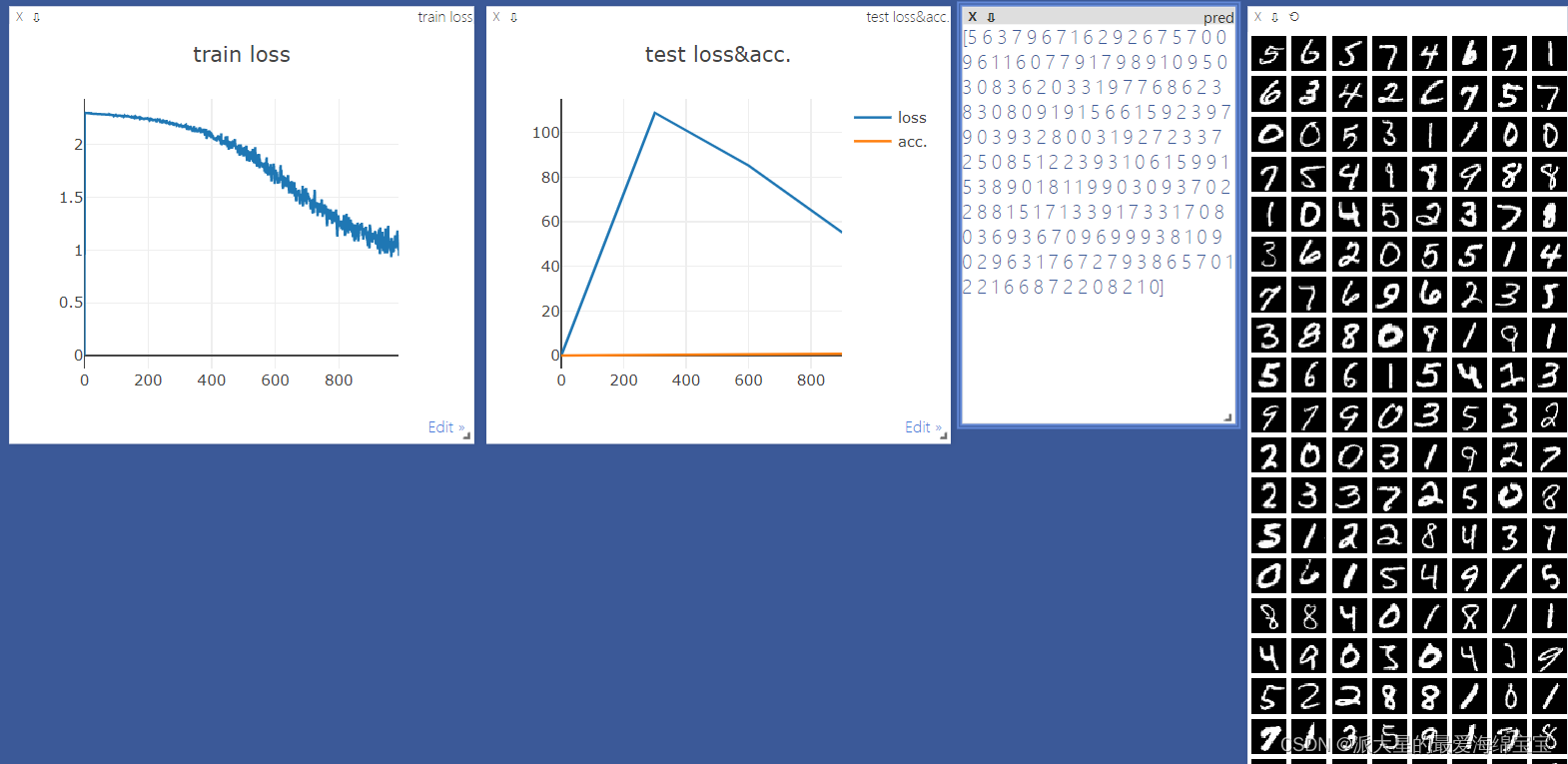
首先创建一条直线,有x,y,且赋初始值,win可以理解为id,大窗口是一个environment。把窗口名字命名为train_loss,且只有一个点(0,0)
from visdom import Visdom
viz=Visdom()
viz.line([0.],[0.],win='train_loss',opts=dict(title='train loss'))
viz.line([loss.item()],[global_step],win='train_loss',update='append')
global_step是x作表,image可以直接接受tensor,对于直线类型,接受的是numpy数据,指定为append,添加到当前直线后面,如果不指定,会全部覆盖掉。
lines:single trace
多条曲线
两条直线,我们需要两个y。
from visdom import Visdom
viz=Visdom()
viz.line([[0.0,0.0]],[0.],win='test',opts=dict(title='test loss & acc',legend=['loss','acc']))
viz.line([[test_loss,correct/len(test_loader.dataset)]],
[global_step],win='test',update='append')
完整代码
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets, transforms
from visdom import Visdom
batch_size=200
learning_rate=0.01
epochs=10
train_loader = torch.utils.data.DataLoader(
datasets.MNIST('mnist_data/', train=True, download=True,
transform=transforms.Compose([
transforms.ToTensor(),
# transforms.Normalize((0.1307,), (0.3081,))
])),
batch_size=batch_size, shuffle=True)
test_loader = torch.utils.data.DataLoader(
datasets.MNIST('mnist_data/', train=False, transform=transforms.Compose([
transforms.ToTensor(),
# transforms.Normalize((0.1307,), (0.3081,))
])),
batch_size=batch_size, shuffle=True)
class MLP(nn.Module):
def __init__(self):
super(MLP, self).__init__()
self.model = nn.Sequential(
nn.Linear(784, 200),
nn.LeakyReLU(inplace=True),
nn.Linear(200, 200),
nn.LeakyReLU(inplace=True),
nn.Linear(200, 10),
nn.LeakyReLU(inplace=True),
)
def forward(self, x):
x = self.model(x)
return x
device = torch.device('cuda:0')
net = MLP().to(device)
optimizer = optim.SGD(net.parameters(), lr=learning_rate)
criteon = nn.CrossEntropyLoss().to(device)
viz=Visdom()
viz.line([0.],[0.],win='train_loss',opts=dict(title='train loss'))
viz.line([[0.0,0.0]],[0.],win='test',opts=dict(title='test loss & acc',legend=['loss','acc']))
global_step=0
for epoch in range(epochs):
for batch_idx, (data, target) in enumerate(train_loader):
data = data.view(-1, 28*28)
data, target = data.to(device), target.cuda()
logits = net(data)
loss = criteon(logits, target)
optimizer.zero_grad()
loss.backward()
# print(w1.grad.norm(), w2.grad.norm())
optimizer.step()
global_step+=1
viz.line([loss.item()],[global_step],win='train_loss',update='append')
if batch_idx % 100 == 0:
print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
epoch, batch_idx * len(data), len(train_loader.dataset),
100. * batch_idx / len(train_loader), loss.item()))
test_loss = 0
correct = 0
for data, target in test_loader:
data = data.view(-1, 28 * 28)
data, target = data.to(device), target.cuda()
logits = net(data)
test_loss += criteon(logits, target).item()
pred = logits.argmax(dim=1)
correct += pred.eq(target).sum().float().item()
viz.line([[test_loss,correct/len(test_loader.dataset)]],
[global_step],win='test',update='append')
viz.images(data.view(-1, 1, 28, 28), win='x')
viz.text(str(pred.detach().cpu().numpy()),win='pred',
opts=dict(title='pred'))
test_loss /= len(test_loader.dataset)
print('\nTest set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format(
test_loss, correct, len(test_loader.dataset),
100. * correct / len(test_loader.dataset)))
边栏推荐
- vim编辑器全部删除文件内容
- GBASE 8C——SQL参考6 sql语法(1)
- 手把手教你搭建钉钉预警机器人
- What are the conditions and procedures for opening crude oil futures accounts?
- 机器人编程与交叉学科的融合延伸
- GBASE 8C——SQL参考6 sql语法(11)
- Face brushing payment is more in line with Alipay's concept of always being ecological
- Inno setup package jar + H5 + MySQL + redis into exe
- In the future, face brushing payment can occupy a lot of market share
- Move protocol launched a beta version, and you can "0" participate in p2e
猜你喜欢

Day 3. Suicidal ideation and behavior in institutions of higher learning: A latent class analysis

Fortex Fangda releases the electronic trading ecosystem to share and win-win with customers

你真的了解 Session 和 Cookie 吗?

解析新时代所需要的创客教育DNA

How can seektiger go against the cold air in the market?

The LAF protocol elephant of defi 2.0 may be one of the few profit-making means in your bear market

使用Docker部署Redis进行高可用主从复制

MySQL如何执行查询语句

「中高级试题」:MVCC实现原理是什么?

亚马逊测评自养号,如何进行系统性的学习?
随机推荐
What are alpha and beta tests?
MySQL limit分页查询优化实践
If the interviewer asks you about JVM, the extra answer of "escape analysis" technology will give you extra points
Emoji表情符号用于文本情感分析-Improving sentiment analysis accuracy with emoji embedding
Deploy redis with docker for high availability master-slave replication
Dimitra and ocean protocol interpret the secrets behind agricultural data
golang怎么给空结构体赋值
Sequel Pro下载及使用方法
kettle的文件名通配规则
kettle如何处理文本数据传输为‘‘而不是null
What are the conditions and procedures for opening crude oil futures accounts?
Day 8.Developing Simplified Chinese Psychological Linguistic Analysis Dictionary for Microblog
The NFT market pattern has not changed. Can okaleido set off a new round of waves?
GBASE 8C——SQL参考6 sql语法(13)
vscode打造golang开发环境以及golang的debug单元测试
Read and understand the advantages of the LAAS scheme of elephant swap
刷脸支付用户主要优势是智能化程度高
机器人编程与交叉学科的融合延伸
Docker deploys the stand-alone version of redis - modify the redis password and persistence method
Common interview questions in software testing