当前位置:网站首页>A method to solve Bert long text matching
A method to solve Bert long text matching
2022-07-03 23:47:00 【Necther】
introduction
bert It opens the door of transfer learning , First, a general language model is trained through unsupervised corpus , Then fine tune based on your own corpus (finetune) Models to meet different business needs . We know bert Can support the largest token The length is 512, If the maximum length exceeds 512, How to deal with it ? The following paper provides a simple and effective solution .
Simple Applications of BERT for Ad Hoc Document Retrieval
201903 publish
1. Abstract
bert The big trick works well , But its maximum length is 512 As well as its performance, these two shortcomings pose challenges to our online deployment . We're doing it document Level recall , Its text length is much longer than bert Length that can be handled , This paper presents a simple and effective solution . Will grow document Break it down into several short sentences , Each sentence is in bert On independent inference , Then aggregate the scores of these sentences to get document Score of .
2. Paper details and experimental results
2.1 Long text matching solution
The author first matches the task with short text - Social media posts to do recall experiments , adopt query To recall related posts , Generally, the length of a post is short text , stay bert Within the scope that can be dealt with . The evaluation index of the experiment is two Average recall (AP) and top30 The recall rate (P30), The following table shows the results of recent depth models on this dataset .

I think the above experimental data mainly say one thing :
bert It works well on short text matching tasks , performance SOTA
Long text docment Match the general solution :
- Direct truncation , take top length , Lost the following data ;
- Fragment level recursion mechanism , Solve long text dependency , Such as Transformer-XL, To some extent, it can solve the problem of long dependence ( Look at the recursion length ), But the model is a little complicated ;
- Based on extraction model , Extract long text docment As doc A summary of the , Then the matching model is trained based on this summary , In this way, only the summary is considered , Without considering other sentences , Relatively one-sided ;
- Divide the long text into several short sentences , Choose the one with the highest matching degree to match , Similarly, other sentences are not considered .
The method of this paper
Long text recall of news corpus , First of all, this paper uses NLTK The tool divides long text into short sentences , Different from considering the most matching sentence , This paper considers top n A sentence . Final long text docment The matching score of the company is calculated as follows :
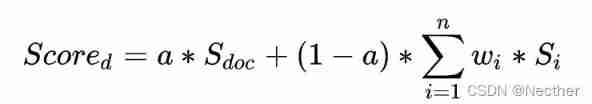
among S_doc Is the original long text score ( Text score ), for example BM25 score ,S_i It means the first one i individual top Based on the bert Sentence matching score ( Semantic score ), The parameter a Parameter range of [0,1],w1 The value of is 1,wi Parameter range [0,1], be based on gridsearch To tune in , Get a better performance .
2.2 experimental result
finetune The data of
Our original fine-tuning data is query query And long text document The relationship between , We split the long text into n After a short sentence , Not all sentences and current query It's strongly related ( Positive sample ), Therefore, we can't simply rely on the current long text data . The solution of this paper is based on external corpus , be based on QA perhaps Microblog data , First bert Based on the general unsupervised corpus, we learn the representation of words and sentences , Therefore, fine-tuning based on a small amount of data can also achieve better results , Therefore, this paper chooses external related corpus to fine tune . The specific effects are shown in the table below , We find that the method based on this paper can achieve better results in long text matching .

3. Summary and questions
summary
- This paper proposes a weighted short sentence scoring method to solve the problem of long text matching score ;
- This method can be achieved on the experimental data set of this paper SOTA The effect of , The method is simple and effective ;
reflection
- The fine-tuning data in the paper uses external data , The fine-tuning model does not fit the current data well , Can we sample positive and negative samples from the segmented short sentences , Such fine-tuning data is also derived from long text ;
- If you choose top n, If n If it's too big , Adjusting parameters is a little complicated ,n If it's too big, you can take top3 Adjustable parameter , Then average the following .
reference
边栏推荐
- D28:maximum sum (maximum sum, translation)
- How can I get the Commission discount of stock trading account opening? Is it safe to open an account online
- Arc135 partial solution
- Fashion cloud interview questions series - JS high-frequency handwritten code questions
- [BSP video tutorial] stm32h7 video tutorial phase 5: MDK topic, system introduction to MDK debugging, AC5, AC6 compilers, RTE development environment and the role of various configuration items (2022-
- Smart fan system based on stm32f407
- Fluent learning (4) listview
- Tencent interview: can you pour water?
- 股票開戶傭金最低的券商有哪些大家推薦一下,手機上開戶安全嗎
- 2022.02.14
猜你喜欢

Interesting 10 CMD commands

SPI based on firmware library
Alibaba cloud container service differentiation SLO hybrid technology practice
![[Mongodb] 2. Use mongodb --------- use compass](/img/d5/0eb7dd4c407fbf2e9ba1b175f5424d.jpg)
[Mongodb] 2. Use mongodb --------- use compass

How to write a good title of 10w+?

Common mode interference of EMC
Unity shader visualizer shader graph

Ningde times and BYD have refuted rumors one after another. Why does someone always want to harm domestic brands?
Correlation analysis summary

2022 chemical automation control instrument examination content and chemical automation control instrument simulation examination
随机推荐
在恒泰证券开户怎么样?安全吗?
Enter MySQL in docker container by command under Linux
Ningde times and BYD have refuted rumors one after another. Why does someone always want to harm domestic brands?
Ningde times and BYD have refuted rumors one after another. Why does someone always want to harm domestic brands?
Kubedl hostnetwork: accelerating the efficiency of distributed training communication
Design of logic level conversion in high speed circuit
Ningde times and BYD have refuted rumors one after another. Why does someone always want to harm domestic brands?
Report on prospects and future investment recommendations of China's assisted reproductive industry, 2022-2028 Edition
Research Report on the scale prediction of China's municipal engineering industry and the prospect of the 14th five year plan 2022-2028
How to quickly build high availability of service discovery
Maxwell equation and Euler formula - link
Gossip about redis source code 74
NPM script
Briefly understand the operation mode of developing NFT platform
C # basic knowledge (2)
It is the most difficult to teach AI to play iron fist frame by frame. Now arcade game lovers have something
No qualifying bean of type ‘com. netflix. discovery. AbstractDiscoveryClientOptionalArgs<?>‘ available
股票開戶傭金最低的券商有哪些大家推薦一下,手機上開戶安全嗎
The interviewer's biggest lie to deceive you, bypassing three years of less struggle
Iclr2022: how does AI recognize "things I haven't seen"?