当前位置:网站首页>Wechat official account all article download links to get
Wechat official account all article download links to get
2022-07-25 04:47:00 【wyazyf】
First, you need to register a wechat official account , Log in to your official account in the browser ,F12 Debug function to get login cookie and token, The following code will use
You also need your favorite official account key, Articles that can be analyzed through official account , Share the qq in , Check the connection as follows ( Reference resources ),__biz=MjM5MTEwMjg3OQ== Parameters in MjM5MTEwMjg3OQ== Namely key 了
7 month 3 Day Moore afternoon review http://mp.weixin.qq.com/s?__biz=MjM5MTEwMjg3OQ==&mid=2649337370&idx=1&sn=ad215a5095251fd2022da4325f4c5ea1&chksm=bea7acea89d025fcf24f39ae7a447538df0ef8bae17a0fc7a9e8a0608e66e1c29412d4e0e426&mpshare=1&scene=23&srcid=0705ahB2wS3F8sS4ZjhEGzFn&sharer_sharetime=1657008846261&sharer_shareid=0b259c605408c21b8871b1da115b81a8#rd I don't say much nonsense , Code up ( The code is only for function , Not optimized , Buddy Light jet )
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @File : articleCollection.py
# datetime:2020/11/5 10:58
import time
import random
import requests
import json
import pandas as pd
# from cookie import getCookie, getFakeId
# Milliseconds to date
def getDate(times):
# print(times)
timearr = time.localtime(times)
date = time.strftime("%Y-%m-%d %H:%M:%S", timearr)
return date
def listAllArticle(fakeId):
# with open('cookie.txt', 'r', encoding='utf-8') as f:
# cookie = f.read()
# cookies = json.loads(cookie)
# The goal is url
url = "https://mp.weixin.qq.com/cgi-bin/appmsg"
# Use Cookie, Skip login operation
headers = {
# official account cookie
"Cookie": "pgv_pvid=3456747162; _clck=1690t1n|1|f2w|0; rewardsn=; wxtokenkey=777; wwapp.vid=; wwapp.cst=; wwapp.deviceid=; pgv_info=ssid=s1397771680; ua_id=IiLNtvCuz4ANqKgLAAAAAP6f5nxLvQkREgshZm91KBU=; wxuin=57011350107536; mm_lang=zh_CN; cert=PltRVZJFwDVVGoyK4BGpZN06yPIYe6xt; sig=h01408121ff9c7ae5071e04633dba23bfa4557bb4f04690e6c696044cc7c310da9695196544ab2b6cd7; ptui_loginuin=1058664513; uin=o1058664513; [email protected]; RK=6ZFRo5ZURT; ptcz=e11cb70127dd967ffbba629350b001d9a01e0cf3527621a418fbcbc1bcfea42e; master_key=anl4iAFrM84vz6qebDiEeYJz8tDjd9gaZQKfvPLYdMc=; pac_uid=1_1058664513; iip=0; o_cookie=1058664513; uuid=2434718c19afbfb5560eedaf940f78c5; rand_info=CAESIHpcc+3KLdYLaVdjLRasfQlfI2w4b3H/jzBZ3nsO2tFa; slave_bizuin=3933389211; data_bizuin=3933389211; bizuin=3933389211; data_ticket=EVwPkCAE9u13gfKr/+hk7VH+Occ967/k5bcvPMCM9RxHstMwuhwzgbEd2fc99eMo; slave_sid=UWJDTFlJTW1iTXg3Nmg2MlpSRjJGUVlNdEx3Q1lBS01FWmR3RGNuVmJCUFFEeDhnY2ZHb2pHU0hmVVA1UVJrVzhaS2dFTmdXV3RINk54aGE2TGpWWWw5WEJJQlV0U3JXQW9QdHY4WW1ja2pza0xYRzJ5cW04TnRtcGZhZFJGNTdTV1hCYjlxRll3ZVZ2YjZE; slave_user=gh_8c64241c1f49; xid=7f0446b9ab13c46f2c5e13a7f623aaef",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36",
}
data = {
"token": "1302392423",# official account token
"lang": "zh_CN",
"f": "json",
"ajax": "1",
"action": "list_ex",
"begin": "0",
"count": "5",
"query": "",
"fakeid": fakeId,
"type": "9",
}
for i in range(2):
data["begin"] = i * 5
# Generate 3-10 Random integer of , Convenient interval of the following procedures
sleepTime = random.randint(3, 10)
print(sleepTime)
time.sleep(sleepTime)
content_json = requests.get(url, headers=headers, params=data).json()
for item in content_json["app_msg_list"]:
# Extract the title of each page of the article and the corresponding url
items = [item["title"], item["link"], item["cover"], getDate(item["create_time"]), item["digest"],
item["item_show_type"], getDate(item["update_time"]), ''.join(fakeId)]
print(items)
# mysql.saveWeChatArticle(items)
if __name__ == '__main__':
#MjM5MTEwMjg3OQ== I like official account key
listAllArticle("MjM5MTEwMjg3OQ==")If you need to download later , Add the download code
Wechat official account wonderful blog : Number :wy15010267

边栏推荐
- Thinking of reading
- Thinking from the perspective of Aya
- Anaconda installs jupyter
- GBase 8a 关于No Suitable Driver 问题
- GDT,LDT,GDTR,LDTR
- 盐粒和冰粒分不清
- In depth understanding of service
- Apipost signs up with Chinatelecom! Work together to accelerate the digital transformation of enterprises
- Web: compiling big refactoring from 10 to 1
- Introduction to FileStream class of C #
猜你喜欢

The application could not be installed: INSTALL_ FAILED_ USER_ RESTRICTED
5年经验的大厂测试/开发程序员,怎样突破技术瓶颈?大厂通病......

推荐系统-协同过滤在Spark中的实现
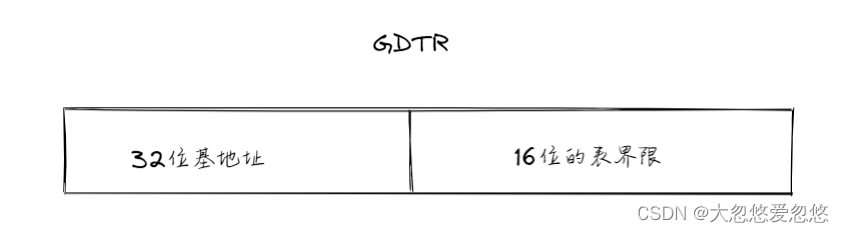
GDT,LDT,GDTR,LDTR
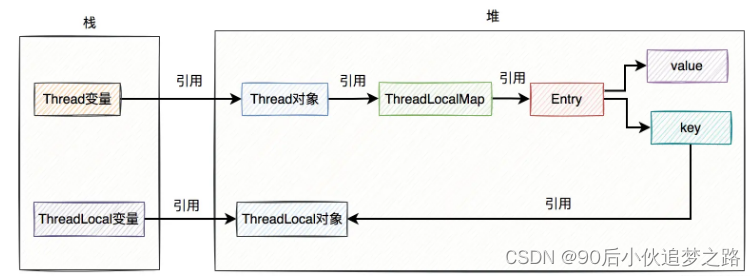
ThreadLocal Kills 11 consecutive questions

【基于stm32f103的SHT30温湿度显示】

暗黑王者|ZEGO 低照度图像增强技术解析
![[golang from introduction to practice] poker licensing game](/img/b4/4e8bc421f82e9dcdaa48381154bfc8.png)
[golang from introduction to practice] poker licensing game
![[detailed tutorial] a thorough article on mongodb aggregation query](/img/81/1ac7afa778849b8a4b103107fd9cb6.png)
[detailed tutorial] a thorough article on mongodb aggregation query

Web: compiling big refactoring from 10 to 1
随机推荐
6.7 billion dollars! The acquisition of IDT by Renesas Electronics was finally approved!
The strongest JVM in the whole network is coming!
二、MySQL数据库基础
Tiny-emitter.js: a small event subscription and Publishing Library
LVGL 8.2 Span
[golang from introduction to practice] poker licensing game
Understand Huawei's 2018 financial report with one picture
# 1. Excel的IF函数
很多时候都是概率
GDT,LDT,GDTR,LDTR
Novel capture practice
It we media shows off its wealth in a high profile, and is targeted by hacker organizations. It is bound to be imprisoned
mitt.js:小型事件发布订阅库
TS learning (VII): interface and type compatibility of TS
How to use ide tool hhdbcs to create a data table containing 1000 simulated data in Oracle database, and
Unity3d learning note 9 - loading textures
[CTF learning] steganography set in CTF -- picture steganography
Introduction to FileStream class of C #
Grafana visual configuration diagram histogram
I didn't expect Mysql to ask these questions