当前位置:网站首页>MobileVIT实战:使用MobileVIT实现图像分类
MobileVIT实战:使用MobileVIT实现图像分类
2022-08-03 16:17:00 【华为云】
@[toc]
MobileVIT实战
论文地址:https://arxiv.org/abs/2110.02178
官方代码:https://github.com/apple/ml-cvnets
本文使用的代码来自:https://gitcode.net/mirrors/rwightman/pytorch-image-models,也就是大名鼎鼎的timm。
目前,Transformer已经霸榜计算机视觉各种任务,但是缺点也很明显就是参数量太大无法用在移动设备,为了解决这个问题,Apple的科学家们将CNN和VIT的优势结合起来,提出了一个轻量级的视觉网络模型mobileViT。
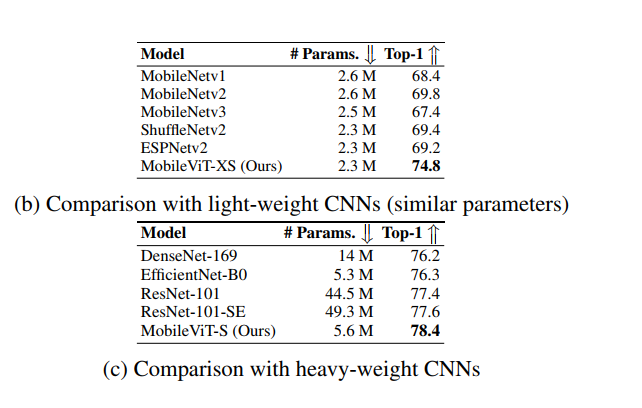
根据论文中给出的Top-1成绩的对比结果,我们可以得出,xs模型参数量比经典的MobileNetV3小,但是精度却提高了7.4%,标准的S模型比ResNet-101,还高一些,但是参数量也只有ResNet-101的九分之一。这样的成绩可谓逆天了!
本文从实战的角度出发,带领大家感受一下mobileViT,我们还是使用以前的植物分类数据集,模型采用MobileViT-S。
安装timm
安装timm,使用pip就行,命令:
pip install timm安装完成之后,才发现没有MobileViT,我以为是晚上太晚了,眼睛不好使了。后来才发现,pip安装的最新版本只有0.54,但是官方最新的版本是0.61,所以只能换种方式安装了。
登录到官方的GitHub,mirrors / rwightman / pytorch-image-models · GitCode,将其下载到本地,然后执行命令:
python setup.py install安装完成后就可以找到mobileViT了。
建议使用timm,因为timm有预训练,这样可以加快训练速度。
数据增强Cutout和Mixup
为了提高成绩我在代码中加入Cutout和Mixup这两种增强方式。实现这两种增强需要安装torchtoolbox。安装命令:
pip install torchtoolboxCutout实现,在transforms中。
from torchtoolbox.transform import Cutout# 数据预处理transform = transforms.Compose([ transforms.Resize((224, 224)), Cutout(), transforms.ToTensor(), transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])])需要导入包:from timm.data.mixup import Mixup,
定义Mixup,和SoftTargetCrossEntropy
mixup_fn = Mixup( mixup_alpha=0.8, cutmix_alpha=1.0, cutmix_minmax=None, prob=0.1, switch_prob=0.5, mode='batch', label_smoothing=0.1, num_classes=12) criterion_train = SoftTargetCrossEntropy()项目结构
MobileVIT_demo├─data│ ├─Black-grass│ ├─Charlock│ ├─Cleavers│ ├─Common Chickweed│ ├─Common wheat│ ├─Fat Hen│ ├─Loose Silky-bent│ ├─Maize│ ├─Scentless Mayweed│ ├─Shepherds Purse│ ├─Small-flowered Cranesbill│ └─Sugar beet├─mean_std.py├─makedata.py├─train.py└─test.pymean_std.py:计算mean和std的值。
makedata.py:生成数据集。
计算mean和std
为了使模型更加快速的收敛,我们需要计算出mean和std的值,新建mean_std.py,插入代码:
from torchvision.datasets import ImageFolderimport torchfrom torchvision import transformsdef get_mean_and_std(train_data): train_loader = torch.utils.data.DataLoader( train_data, batch_size=1, shuffle=False, num_workers=0, pin_memory=True) mean = torch.zeros(3) std = torch.zeros(3) for X, _ in train_loader: for d in range(3): mean[d] += X[:, d, :, :].mean() std[d] += X[:, d, :, :].std() mean.div_(len(train_data)) std.div_(len(train_data)) return list(mean.numpy()), list(std.numpy())if __name__ == '__main__': train_dataset = ImageFolder(root=r'data1', transform=transforms.ToTensor()) print(get_mean_and_std(train_dataset))数据集结构:

运行结果:
([0.3281186, 0.28937867, 0.20702125], [0.09407319, 0.09732835, 0.106712654])
把这个结果记录下来,后面要用!
生成数据集
我们整理还的图像分类的数据集结构是这样的
data├─Black-grass├─Charlock├─Cleavers├─Common Chickweed├─Common wheat├─Fat Hen├─Loose Silky-bent├─Maize├─Scentless Mayweed├─Shepherds Purse├─Small-flowered Cranesbill└─Sugar beetpytorch和keras默认加载方式是ImageNet数据集格式,格式是
├─data│ ├─val│ │ ├─Black-grass│ │ ├─Charlock│ │ ├─Cleavers│ │ ├─Common Chickweed│ │ ├─Common wheat│ │ ├─Fat Hen│ │ ├─Loose Silky-bent│ │ ├─Maize│ │ ├─Scentless Mayweed│ │ ├─Shepherds Purse│ │ ├─Small-flowered Cranesbill│ │ └─Sugar beet│ └─train│ ├─Black-grass│ ├─Charlock│ ├─Cleavers│ ├─Common Chickweed│ ├─Common wheat│ ├─Fat Hen│ ├─Loose Silky-bent│ ├─Maize│ ├─Scentless Mayweed│ ├─Shepherds Purse│ ├─Small-flowered Cranesbill│ └─Sugar beet新增格式转化脚本makedata.py,插入代码:
import globimport osimport shutilimage_list=glob.glob('data1/*/*.png')print(image_list)file_dir='data'if os.path.exists(file_dir): print('true') #os.rmdir(file_dir) shutil.rmtree(file_dir)#删除再建立 os.makedirs(file_dir)else: os.makedirs(file_dir)from sklearn.model_selection import train_test_splittrainval_files, val_files = train_test_split(image_list, test_size=0.3, random_state=42)train_dir='train'val_dir='val'train_root=os.path.join(file_dir,train_dir)val_root=os.path.join(file_dir,val_dir)for file in trainval_files: file_class=file.replace("\\","/").split('/')[-2] file_name=file.replace("\\","/").split('/')[-1] file_class=os.path.join(train_root,file_class) if not os.path.isdir(file_class): os.makedirs(file_class) shutil.copy(file, file_class + '/' + file_name)for file in val_files: file_class=file.replace("\\","/").split('/')[-2] file_name=file.replace("\\","/").split('/')[-1] file_class=os.path.join(val_root,file_class) if not os.path.isdir(file_class): os.makedirs(file_class) shutil.copy(file, file_class + '/' + file_name)训练
完成上面的步骤后,就开始train脚本的编写,新建train.py.
导入项目使用的库
import torchimport torch.nn as nnimport torch.nn.parallelimport torch.optim as optimimport torch.utils.dataimport torch.utils.data.distributedimport torchvision.datasets as datasetsimport torchvision.transforms as transformsfrom sklearn.metrics import classification_reportfrom timm.data.mixup import Mixupfrom timm.loss import SoftTargetCrossEntropyfrom timm.models.mobilevit import mobilevit_sfrom apex import ampimport warningswarnings.filterwarnings("ignore")设置全局参数
设置学习率、BatchSize、epoch等参数,判断环境中是否存在GPU,如果没有则使用CPU。建议使用GPU,CPU太慢了。
# 设置全局参数model_lr = 1e-4BATCH_SIZE = 8EPOCHS = 300DEVICE = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')use_amp=False #是否使用混合精度classes=12# 数据预处理7model_lr:学习率,根据实际情况做调整。
BATCH_SIZE:batchsize,根据显卡的大小设置。
EPOCHS:epoch的个数,一般300够用。
use_amp:是否使用混合精度。
classes:类别个数。
CLIP_GRAD:梯度的最大范数,在梯度裁剪里设置。
图像预处理与增强
数据处理比较简单,加入了Cutout、做了Resize和归一化,定义Mixup函数。
这里注意下Resize的大小,由于MobileViT的输入是256×256的大小,所以要Resize为256×256。
# 数据预处理7transform = transforms.Compose([ transforms.Resize((256, 256)), Cutout(), transforms.ToTensor(), transforms.Normalize(mean=[0.51819474, 0.5250407, 0.4945761], std=[0.24228974, 0.24347611, 0.2530049])])transform_test = transforms.Compose([ transforms.Resize((256, 256)), transforms.ToTensor(), transforms.Normalize(mean=[0.51819474, 0.5250407, 0.4945761], std=[0.24228974, 0.24347611, 0.2530049])])mixup_fn = Mixup( mixup_alpha=0.8, cutmix_alpha=1.0, cutmix_minmax=None, prob=0.1, switch_prob=0.5, mode='batch', label_smoothing=0.1, num_classes=classes)读取数据
使用pytorch默认读取数据的方式,然后将dataset_train.class_to_idx打印出来,预测的时候要用到。
将dataset_train.class_to_idx保存到txt文件或者json文件中。
# 读取数据dataset_train = datasets.ImageFolder('data/train', transform=transform)dataset_test = datasets.ImageFolder("data/val", transform=transform_test)# 导入数据train_loader = torch.utils.data.DataLoader(dataset_train, batch_size=BATCH_SIZE, shuffle=True)test_loader = torch.utils.data.DataLoader(dataset_test, batch_size=BATCH_SIZE, shuffle=False)print(dataset_train.class_to_idx)with open('class.txt','w') as file: file.write(str(dataset_train.class_to_idx))with open('class.json','w',encoding='utf-8') as file: file.write(json.dumps(dataset_train.class_to_idx))class_to_idx的结果:
{‘Black-grass’: 0, ‘Charlock’: 1, ‘Cleavers’: 2, ‘Common Chickweed’: 3, ‘Common wheat’: 4, ‘Fat Hen’: 5, ‘Loose Silky-bent’: 6, ‘Maize’: 7, ‘Scentless Mayweed’: 8, ‘Shepherds Purse’: 9, ‘Small-flowered Cranesbill’: 10, ‘Sugar beet’: 11}
设置模型
- 设置loss函数,train的loss为:SoftTargetCrossEntropy,val的loss:nn.CrossEntropyLoss()。
- 设置模型为mobilevit_s,预训练设置为true,num_classes设置为12。
- 优化器设置为adam。
- 学习率调整策略选择为余弦退火。
- 检测可用显卡的数量,如果大于1,则要用torch.nn.DataParallel加载模型,开启多卡训练。
- 开启混合精度训练。
- 如果存在多上显卡,则使用DP的方式开启多卡并行训练。
# 实例化模型并且移动到GPUcriterion_train = SoftTargetCrossEntropy()# 训练用的losscriterion_val = torch.nn.CrossEntropyLoss()# 验证用的lossmodel_ft = mobilevit_s(pretrained=True)# 定义模型,并设置预训练print(model_ft)num_ftrs = model_ft.head.fc.in_featuresmodel_ft.head.fc = nn.Linear(num_ftrs, classes)# 修改类别model_ft.to(DEVICE)print(model_ft)# 选择简单暴力的Adam优化器,学习率调低optimizer = optim.Adam(model_ft.parameters(), lr=model_lr)cosine_schedule = optim.lr_scheduler.CosineAnnealingLR(optimizer=optimizer, T_max=20, eta_min=1e-6)# 使用余弦退火算法调整学习率if use_amp: #如果使用混合精度训练,则初始化amp。 model, optimizer = amp.initialize(model_ft, optimizer, opt_level="O1") # 这里是“欧一”,不是“零一”if torch.cuda.device_count() > 1: #检测是否存在多张显卡,如果存在则使用DP的方式并行训练 print("Let's use", torch.cuda.device_count(), "GPUs!") model_ft = torch.nn.DataParallel(model_ft)定义训练和验证函数
定义训练函数和验证函数,在一个epoch完成后,使用classification_report计算详细的得分情况。
训练的主要步骤:
1、判断迭代的数据是否是奇数,由于mixup_fn只能接受偶数,所以如果不是偶数则要减去一位,让其变成偶数。但是有可能最后一次迭代只有一条数据,减去后就变成了0,所以还要判断不能小于2,如果小于2则直接中断本次循环。
2、将数据输入mixup_fn生成mixup数据,然后输入model计算loss。
3、如果使用混合精度,则使用amp.scale_loss反向传播求解梯度,否则,直接反向传播求梯度。torch.nn.utils.clip_grad_norm_函数执行梯度裁剪,防止梯度爆炸。
等待一个epoch完成后,统计类别的得分情况。
# 定义训练过程def train(model, device, train_loader, optimizer, epoch): model.train() sum_loss = 0 total_num = len(train_loader.dataset) print(total_num, len(train_loader)) for batch_idx, (data, target) in enumerate(train_loader): if len(data) % 2 != 0: if len(data) < 2: continue data = data[0:len(data) - 1] target = target[0:len(target) - 1] print(len(data)) data, target = data.to(device, non_blocking=True), target.to(device, non_blocking=True) samples, targets = mixup_fn(data, target) output = model(data) loss = criterion_train(output, targets) optimizer.zero_grad() if use_amp: with amp.scale_loss(loss, optimizer) as scaled_loss: scaled_loss.backward() torch.nn.utils.clip_grad_norm_(amp.master_params(optimizer), CLIP_GRAD) else: loss.backward() torch.nn.utils.clip_grad_norm_(model.parameters(), CLIP_GRAD) optimizer.step() lr = optimizer.state_dict()['param_groups'][0]['lr'] print_loss = loss.data.item() sum_loss += print_loss if (batch_idx + 1) % 10 == 0: print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}\tLR:{:.9f}'.format( epoch, (batch_idx + 1) * len(data), len(train_loader.dataset), 100. * (batch_idx + 1) / len(train_loader), loss.item(), lr)) ave_loss = sum_loss / len(train_loader) print('epoch:{},loss:{}'.format(epoch, ave_loss))ACC = 0# 验证过程def val(model, device, test_loader): global ACC model.eval() test_loss = 0 correct = 0 total_num = len(test_loader.dataset) print(total_num, len(test_loader)) val_list = [] pred_list = [] with torch.no_grad(): for data, target in test_loader: for t in target: val_list.append(t.data.item()) data, target = data.to(device), target.to(device) output = model(data) loss = criterion_val(output, target) _, pred = torch.max(output.data, 1) for p in pred: pred_list.append(p.data.item()) correct += torch.sum(pred == target) print_loss = loss.data.item() test_loss += print_loss correct = correct.data.item() acc = correct / total_num avgloss = test_loss / len(test_loader) print('\nVal set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format( avgloss, correct, len(test_loader.dataset), 100 * acc)) if acc > ACC: if isinstance(model, torch.nn.DataParallel): torch.save(model.module, 'model_' + str(epoch) + '_' + str(round(acc, 3)) + '.pth') else: torch.save(model, 'model_' + str(epoch) + '_' + str(round(acc, 3)) + '.pth') ACC = acc return val_list, pred_list# 训练is_set_lr = Falsefor epoch in range(1, EPOCHS + 1): train(model_ft, DEVICE, train_loader, optimizer, epoch) if epoch < 600: cosine_schedule.step() else: if is_set_lr: continue for param_group in optimizer.param_groups: param_group["lr"] = 1e-6 is_set_lr = True val_list, pred_list = val(model_ft, DEVICE, test_loader) print(classification_report(val_list, pred_list, target_names=dataset_train.class_to_idx))运行结果:
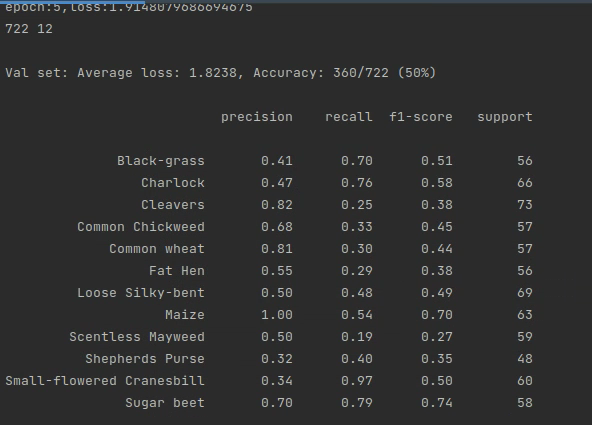
测试
测试,我们采用一种通用的方式。
测试集存放的目录如下图:
第一步 定义类别,这个类别的顺序和训练时的类别顺序对应,一定不要改变顺序!!!!
第二步 定义transforms,transforms和验证集的transforms一样即可,别做数据增强。
第三步 加载model,并将模型放在DEVICE里,
第四步 读取图片并预测图片的类别,在这里注意,读取图片用PIL库的Image。不要用cv2,transforms不支持。
import torch.utils.data.distributedimport torchvision.transforms as transformsfrom PIL import Imagefrom torch.autograd import Variableimport osclasses = ('Black-grass', 'Charlock', 'Cleavers', 'Common Chickweed', 'Common wheat', 'Fat Hen', 'Loose Silky-bent', 'Maize', 'Scentless Mayweed', 'Shepherds Purse', 'Small-flowered Cranesbill', 'Sugar beet')transform_test = transforms.Compose([ transforms.Resize((256, 256)), transforms.ToTensor(), transforms.Normalize(mean=[0.51819474, 0.5250407, 0.4945761], std=[0.24228974, 0.24347611, 0.2530049])])DEVICE = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")model = torch.load("model_52_0.954.pth")model.eval()model.to(DEVICE)path = 'test/'testList = os.listdir(path)for file in testList: img = Image.open(path + file) img = transform_test(img) img.unsqueeze_(0) img = Variable(img).to(DEVICE) out = model(img) # Predict _, pred = torch.max(out.data, 1) print('Image Name:{},predict:{}'.format(file, classes[pred.data.item()]))运行结果:
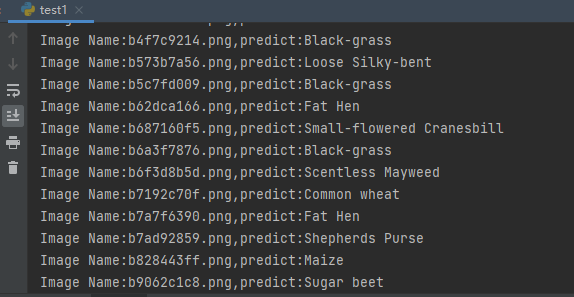
完整代码:
https://download.csdn.net/download/hhhhhhhhhhwwwwwwwwww/85232437
边栏推荐
猜你喜欢
如何启动 NFT 集合

2年开发经验去面试,吊打面试官,即将面试的程序员这些笔记建议复习
"Avnet Embedded Weekly" Issue 276: 2022.07.25--2022.07.31
MPLS的wpn实验
为教育插上数字化的翅膀,网易云信发布「互联网+教育」整体解决方案
2021年数据泄露成本报告解读

C专家编程 第3章 分析C语言的声明 3.7 typedef struct foo{... foo;}的含义

Not to be ignored!Features and advantages of outdoor LED display
Windows 事件查看器记录到 MYSQL

元宇宙系列--Value creation in the metaverse
随机推荐
元宇宙系列--Value creation in the metaverse
【Unity入门计划】基本概念(7)-Input Manager&Input类
MarkDown常用代码片段和工具
Web3 安全风险令人生畏?应该如何应对?
window.open不显示favicon.icon
protobuf 中数据编码规则
不可忽略!户外LED显示屏的特点及优势
Hannah荣获第六季完美童模全球总决赛全球人气总冠军
Difference and performance comparison between HAL and LL library of STM32
全新探险者以40万的产品击穿豪华SUV价格壁垒
简易网络传输方法
【Unity入门计划】基本概念(8)-瓦片地图 TileMap 01
为教育插上数字化的翅膀,网易云信发布「互联网+教育」整体解决方案
C语言01、数据类型、变量常量、字符串、转义字符、注释
mysql delete 执行报错:You can‘t specify target table ‘doctor_info‘ for update in FROM clause
STM32的HAL和LL库区别和性能对比
CopyOnWriteArrayList details
STM32 GPIO LED and buzzer implementation [Day 4]
Interpretation of the 2021 Cost of Data Breach Report
我写了个”不贪吃蛇“小游戏