当前位置:网站首页>[Multi-task learning] Modeling Task Relationships in Multi-task Learning with Multi-gate Mixture-of-Experts KDD18
[Multi-task learning] Modeling Task Relationships in Multi-task Learning with Multi-gate Mixture-of-Experts KDD18
2022-08-01 20:01:00 【chad_lee】
Understand at the model level,We often spend a lot of energy on a single goal“Find strong features”和“Remove redundant features”输入到模型,提高模型效果.那么切换到MTL时,每个task所需要的“强特”and exclusionary“Negative”是不同的,MTLThe purpose is for eachtask Find their strong and negative specials as much as possible.
Understand at the optimization level,多个task同时优化模型,某些taskwill dominate the optimization process of the model,drowned out the otherstask.
Understand from the perspective of supervisory signals,MTL不仅仅是任务,It is also a data augmentation,相当于每个task多了k-1A supervisory signal to aid learning,Some features can be derived from otherstask学的更好.Monitor the quality of the signal andtasksimilarity between them,不相似的taskInstead, it's noise.
#SB、MOE、MMOE
《Modeling Task Relationships in Multi-task Learning with Multi-gate Mixture-of-Experts》Google KDD 2018

share-bottom
Multiple tasks share the same bottom network,The bottom network outputs the feature vector of a sample,Each subtask picks up a small by itselfNN tower.
优点:简单,并且模型过拟合的风险小(Because it is not easy to overfit multiple tasks at the same time,It can be said that multiple tasks supervise each other and penalize overfitting);Multitasking is more relevant,Complement each other the better.
缺点:If the connection between tasks is not strong(矛盾、冲突),Then the optimization direction for the underlying network may be the opposite.
Bottom output:f(x),子任务tower:$h^k_x ,Output for each subtask: ,Output for each subtask: ,Output for each subtask:y_x^k = h^k_x(f(x)) $
One-gate-MoE
将inputInput to three independentexpert(3个nn),同时将input输入到gate,gate输出每个expert被选择的概率,然后将三个expert的输出加权求和,输出给tower:
y k = h k ( ∑ i = 1 n g i f i ( x ) ) , y^{k}=h^{k}\left(\sum_{i=1}^{n} g_{i} f_{i}(x)\right) \text { ,} yk=hk(i=1∑ngifi(x)) ,
其中 g ( ) g() g() is a multi-classification module,且 ∑ i = 1 n g ( x ) i = 1 \sum_{i=1}^{n} g(x)_{i}=1 ∑i=1ng(x)i=1 ,$f_{i}(), i=1, \cdots, n 是 n 个 e x p e r t n e t w o r k , k 表示 k 个任务, 是n个expert network,k表示k个任务, 是n个expertnetwork,k表示k个任务,h^k$means afterNN tower.
So here is equivalent to givinginput当作query,给bottomThe output adds oneattention,Look at the formula to change the soup without changing the medicine,$h^k $outside the parentheses,这就导致不同的towerThe input is still the same,没有解决task冲突问题.
但是MOEIt can solve the problem of domain adaptation,用于cross domain:
MMOE
因此很自然,每个 $h_k $ Don't put it outside parentheses,不同的 h k h_k hkThe input is different.
所以每个task各分配一个gate,这样gateThe role is no longerattention了,Rather, it's personalized for eachtaskSelect important features,Filter redundant features:
f k ( x ) = ∑ i = 1 n g i k ( x ) f i ( x ) g k ( x ) = softmax ( W g k x ) \begin{aligned} f^{k}(x) &=\sum_{i=1}^{n} g_{i}^{k}(x) f_{i}(x) \\ \ \ g^{k}(x) &=\operatorname{softmax}\left(W_{gk}x\right) \end{aligned} fk(x) gk(x)=i=1∑ngik(x)fi(x)=softmax(Wgkx)
其中gis a linear change+softmax.
There is a situation in theory,gate能给每个task筛选特征,As for whether the model can be optimized to this situation,不好说.
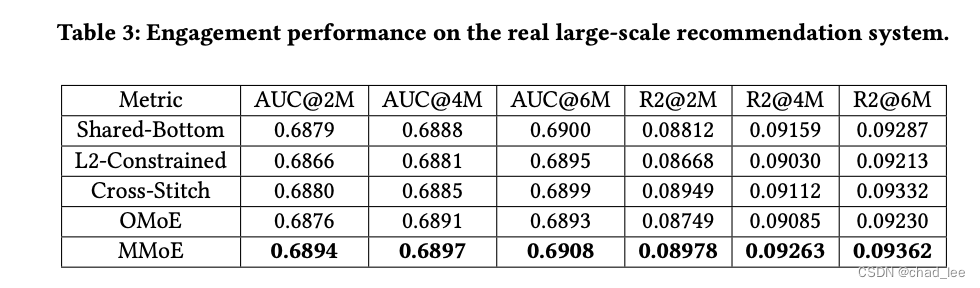
实验
边栏推荐
- Get started quickly with MongoDB
- 【多任务学习】Modeling Task Relationships in Multi-task Learning with Multi-gate Mixture-of-Experts KDD18
- 百度无人驾驶商业化已“上路”
- LTE时域、频域资源
- 数据库系统原理与应用教程(072)—— MySQL 练习题:操作题 121-130(十六):综合练习
- Pytorch模型训练实用教程学习笔记:一、数据加载和transforms方法总结
- 数据库系统原理与应用教程(071)—— MySQL 练习题:操作题 110-120(十五):综合练习
- MySQL你到底都加了什么锁?
- regular expression
- SIPp 安装及使用
猜你喜欢
Gradle系列——Gradle文件操作,Gradle依赖(基于Gradle文档7.5)day3-1

【节能学院】智能操控装置在高压开关柜的应用
The graphic details Eureka's caching mechanism/level 3 cache

WhatsApp group sending actual combat sharing - WhatsApp Business API account

通配符 SSL/TLS 证书

【无标题】
![[Multi-task optimization] DWA, DTP, Gradnorm (CVPR 2019, ECCV 2018, ICML 2018)](/img/a1/ec038eeb6c98c871eb31d92569533d.png)
[Multi-task optimization] DWA, DTP, Gradnorm (CVPR 2019, ECCV 2018, ICML 2018)

专利检索常用的网站有哪些?
LTE时域、频域资源

泰德制药董事长郑翔玲荣膺“2022卓越影响力企业家奖” 泰德制药荣获“企业社会责任典范奖”
随机推荐
mysql自增ID跳跃增长解决方案
XSS靶场中级绕过
小数据如何学习?吉大最新《小数据学习》综述,26页pdf涵盖269页文献阐述小数据学习理论、方法与应用
Redis 做签到统计
Redis 做网页UV统计
【ES】ES2021 我学不动了,这次只学 3 个。
数字孪生北京故宫,元宇宙推进旅游业进程
18. Distributed configuration center nacos
Acrel-5010重点用能单位能耗在线监测系统在湖南三立集团的应用
【Untitled】
【无标题】
1个小时!从零制作一个! AI图片识别WEB应用!
kingbaseV8R3和postgreSQL哪个版本最接近?
百度无人驾驶商业化已“上路”
图文详述Eureka的缓存机制/三级缓存
模板特例化和常用用法
面试突击70:什么是粘包和半包?怎么解决?
第59章 ApplicationPart内置依赖注入中间件
KDD2022 | Self-Supervised Hypergraph Transformer Recommendation System
洛谷 P2440 木材加工