当前位置:网站首页>Pytorch学习记录(二):张量
Pytorch学习记录(二):张量
2022-07-26 22:31:00 【狸狸Arina】
1. 张量的创建
import torch
import numpy as np
# Import from numpy
a1 = np.array([2, 3.3])
b1 = torch.from_numpy(a1)
a2 = np.ones([2,3])
b2 = torch.from_numpy(a)
# Import from List
a3 = torch.tensor([2., 3.2])
a4 = torch.FloatTensor([2., 3.2])
# set default type
a5 = torch.tensor([1.2, 3]).type()
torch.set_default_tensor_type(torch.DoubleTensor)
a6 = tensor.tensor(1.2, 3).type()
# rand() 随机0-1初始化
torch.rand(2) # 向量
# tensor([0.2300, 0.7452])
torch.rand(2,3) # 矩阵
# tensor([[0.0214, 0.4409, 0.3778],
# [0.8571, 0.4957, 0.7218]])
torch.rand(2,2,3) # 三维
# tensor([[[0.7301, 0.0870, 0.0573],
# [0.4576, 0.5049, 0.9410]],
# [[0.7045, 0.6702, 0.3119],
# [0.1384, 0.9376, 0.9691]]])
# rand_like() 给定tensor的随机0-1初始化
# 创建一个向量
data = torch.tensor([1.1, 2.2, 3.3])
# 随机0-1初始化一个shape和data相同的tensor
torch.rand_like(data)
# tensor([0.7710, 0.5399, 0.4941])
# randint() 在某一范围内随机整数采样
# 需要指定最小值, 最大值, shape,随机采样包含最小值,不包含最大值
torch.randint(1, 10, size=[2,3])
# tensor([[4, 3, 2],
# [5, 2, 2]])
# randn() 随机正态分布
torch.randn(3) # 向量
# tensor([-0.8556, -1.3012, -0.1202])
torch.randn(size=[2,3]) # 矩阵
# tensor([[-0.5486, 1.0590, 2.7441],
# [ 0.4896, 0.0592, -0.5964]])
# 全为1的张量
#(1)ones() # 全为1的tensor
data = torch.ones(size=[2,3])
# tensor([[1., 1., 1.],
# [1., 1., 1.]])
# 和data的shape相同的全为1的tensor
torch.ones_like(data)
# tensor([[1., 1., 1.],
# [1., 1., 1.]])
# 全为0的张量
#(2)zeros() # 全为0的tensor
data = torch.zeros(size=[2,3])
# tensor([[0., 0., 0.],
# [0., 0., 0.]])
# 和data的shape相同的全为1的tensor
torch.zeros_like(data)
# tensor([[0., 0., 0.],
# [0., 0., 0.]])
# 全为某个值的张量
# 2行3列全为1的tensor
torch.full(size=[2,3], fill_value=7.0)
# tensor([[7., 7., 7.],
# [7., 7., 7.]])
# 初始化一个标量
torch.full(size=[], fill_value=7)
# tensor(7)
# 初始化一个向量
torch.full(size=[1], fill_value=7)
# tensor([7])
# 单位矩阵
# 三行三列,可略写(3,3)
torch.eye(3)
# tensor([[1., 0., 0.],
# [0., 1., 0.],
# [0., 0., 1.]])
torch.eye(3,4)
# tensor([[1., 0., 0., 0.],
# [0., 1., 0., 0.],
# [0., 0., 1., 0.]])
# arange() 递增张量
# 从0到10每次递增1,包含0不包含10
torch.arange(0,10)
# tensor([0, 1, 2, 3, 4, 5, 6, 7, 8, 9])
# 从0到10每次递增2,包含0不包含10
torch.arange(0, 10, 2)
# tensor([0, 2, 4, 6, 8])
# linspace 等分张量
# 从0到10,等分成4份的等差数列,包含0也包含10
torch.linspace(0, 10, 4)
# tensor([ 0.0000, 3.3333, 6.6667, 10.0000])
# 0到10等分7份
torch.linspace(0, 10, 7)
# tensor([ 0.0000, 1.6667, 3.3333, 5.0000, 6.6667, 8.3333, 10.0000])
# logspace 幂指数递增
# base代表对数的底数,0-10分成11步,计算10^(n)
torch.logspace(0, 10, steps=10, base=10)
# tensor([1.0000e+00, 1.0000e+01, 1.0000e+02, 1.0000e+03, 1.0000e+04, 1.0000e+05, 1.0000e+06, 1.0000e+07, 1.0000e+08, 1.0000e+09, 1.0000e+10])
# 计算2^(n),从0到-1分成11步
torch.logspace(0, -1, steps=10, base=2)
# tensor([1.0000, 0.9259, 0.8572, 0.7937, 0.7349, 0.6804, 0.6300, 0.5833, 0.5400, 0.5000])
# randperm() 随机打乱
# 生成0-10的随机索引[0,9]之间
torch.randperm(10)
# tensor([7, 8, 9, 6, 3, 1, 0, 4, 2, 5])
# 索引打乱后还能配对
index = torch.randperm(10)
# 创建两个张量
data1 = torch.arange(0,10)
data2 = torch.arange(0,10) * 10
# 索引配对打乱,不改变data1和data2各元素之间的对应关系
data1[index]*10 == data2[index]
# tensor([True, True, True, True, True, True, True, True, True, True])
2. Tensor的索引和切片
2.1 直接索引

2.2 连续索引

2.3 索引+步长
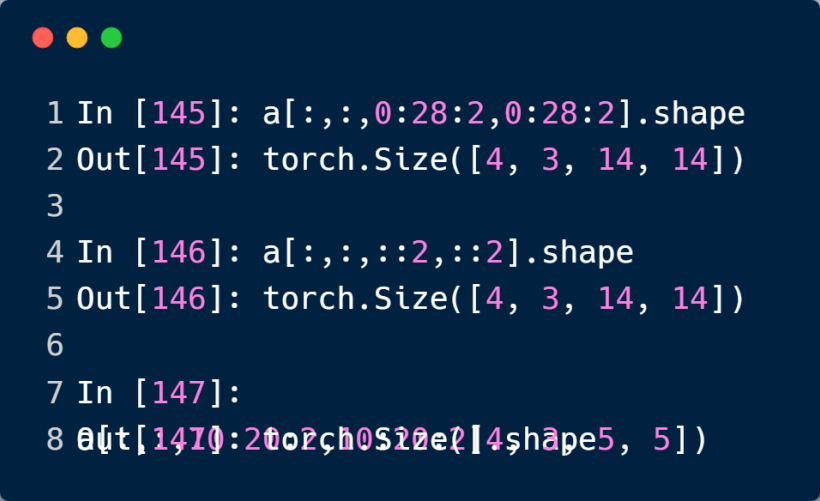
2.4 任意的维度

2.5 获取指定维度上的指定索引

2.6 使用掩码的索引

2.7 使用展平的的索引

3. 维度变换
3.1 shape转换 view/reshape
import torch
a = torch.randn(4, 1, 28, 28) #假设为MINIST数据集
print(a.shape)
b = a.view(4 ,28,28)
print(b.shape)
c = a.view(4,28*28) #将图像展平
print(c.shape)
d = a.view(4*28, 28) #关注所有图像所行
print(d.shape)
''' torch.Size([4, 1, 28, 28]) torch.Size([4, 28, 28]) torch.Size([4, 784]) torch.Size([112, 28]) '''
3.2 增加维度 unsqueeze
import torch
a = torch.randn(4, 1, 28, 28) #假设为MINIST数据集
print('a',a.shape)
b = torch.unsqueeze(a, 0) #在0维度前面插入一个维度 没有增加数据
print('b', b.shape)
c = a.unsqueeze(4) #在4维度前面插入一个维度
print('c', c.shape)
d = a.unsqueeze(2) #在第2个维度前面插入一个维度
print('d', d.shape)
e = a.unsqueeze(-1) #在最后-1维度后面插入一个维度
print('e',e.shape)
f = a.unsqueeze(-3) #在-3维度后面之后插入一个维度
print('f',f.shape)
''' a torch.Size([4, 1, 28, 28]) b torch.Size([1, 4, 1, 28, 28]) c torch.Size([4, 1, 28, 28, 1]) d torch.Size([4, 1, 1, 28, 28]) e torch.Size([4, 1, 28, 28, 1]) f torch.Size([4, 1, 1, 28, 28]) '''
3.3 维度挤压 squeeze
import torch
bias = torch.randn(32)
f = torch.rand(4, 32, 14,14) #bias相当于每个通道上的偏置
# 将bias叠加在f上
b = bias.unsqueeze(0).unsqueeze(2).unsqueeze(3) #[1,32]->[1,32,1]->[1,32,1,1]
print('b', b.shape)
c = b.squeeze() #挤压掉所有为1的维度
print('c', c.shape)
d = b.squeeze(0) #挤压掉0维数据
print('d', d.shape)
e = b.squeeze(1) #挤压掉第1维数据 如果第1维大小不为1,则挤压失败,返回原来的维度
print('e', e.shape)
f = b.squeeze(-4) #挤压第-4维维度
print('f', f.shape)
''' b torch.Size([1, 32, 1, 1]) c torch.Size([32]) d torch.Size([32, 1, 1]) e torch.Size([1, 32, 1, 1]) f torch.Size([32, 1, 1]) '''
3.4 维度扩展 Expand/repeat
- expend
import torch
bias = torch.randn(32)
f = torch.rand(4, 32, 14,14) #bias相当于每个通道上的偏置
# 将bias叠加在f上
b = bias.unsqueeze(0).unsqueeze(2).unsqueeze(3) #[1,32]->[1,32,1]->[1,32,1,1]
print('b', b.shape)
# c = b.expand(4,10,1,1) #扩展第0个维度 第1个维度不为1,所以该扩展失败(报错),其余维度不变
d = b.expand(4,32,14,14) #扩展所有维度
print(d.shape)
e = b.expand(100,32,1,1)
print(e.shape)
''' b torch.Size([1, 32, 1, 1]) torch.Size([4, 32, 14, 14]) torch.Size([100, 32, 1, 1]) '''
- repeat
import torch
bias = torch.randn(32)
f = torch.rand(4, 32, 14,14) #bias相当于每个通道上的偏置
# 将bias叠加在f上
b = bias.unsqueeze(0).unsqueeze(2).unsqueeze(3) #[1,32]->[1,32,1]->[1,32,1,1]
print('b', b.shape)
c = b.repeat(4,1,14,14) #[1,32,1,1] -> [14,32,14,14] 拷贝
print('after repeat all dim:', b.shape)
d = b.repeat(10,32,1,1) #[1,32,1,1]->[1*10,32*32,1,1]拷贝第一个维度10次,第二个维度拷贝32次, 其余的拷贝一次
print('repeat dim 0,1:', d.shape)
''' b torch.Size([1, 32, 1, 1]) after repeat all dim: torch.Size([1, 32, 1, 1]) repeat dim 0,1: torch.Size([10, 1024, 1, 1]) '''
3.5 tensor转置
- .t
import torch
b = torch.randn(3,4)
print('b', b.shape)
c = b.t()
print('b.t()', c.shape)
''' b torch.Size([3, 4]) b.t() torch.Size([4, 3]) '''
- transpose()
import torch
a = torch.randn(4,3,32,32)
b = a.transpose(1,3).contiguous().view(4,3*32*32).view(4,3,32,32) #数据污染了
c = a.transpose(1,3).contiguous().view(4,3*32*32).view(4,32,32,3).transpose(1,3)
d = a.transpose(1,3).contiguous().view(-1) #使用a.transpose(1,3).view(-1)会报错, 必须要加一个contiguous()函数
- permute转置
#将tensor图像数据转换为numpy图像数据
import torch
a = torch.randn(4,3,32,32)
print(a.shape)
b = a.transpose(1,3).transpose(1,2) #[b,c,h,w]->[b,w,h,c]->[b,h,w,c]
print(b.shape)
c = a.permute(0,2,3,1)
print(c.shape)
''' torch.Size([4, 3, 32, 32]) torch.Size([4, 32, 32, 3]) torch.Size([4, 32, 32, 3]) '''
4. 合并与分割
4.1 cat操作
#tensor拼接
import torch
a = torch.rand(4,32,8)
b = torch.rand(5,32,8)
c = torch.cat((a,b),dim=0)
print(c.shape)
''' torch.Size([9, 32, 8]) '''
4.2 stack操作
#tensor堆叠
import torch
a = torch.rand(4,32,8)
b = torch.rand(4,32,8)
c = torch.stack((a,b),dim=0)
print(c.shape)
''' torch.Size([2, 4, 32, 8]) '''
4.3 split操作
#tensor拆分
import torch
a = torch.rand(4,3,3)
aa,bb = torch.split(a,[1,3], dim=0)
print(aa.shape)
print(bb.shape)
cc,dd = torch.split(a, 2, dim = 0) #在0维度上按照单元长度为2进行拆分
print(cc.shape)
print(dd.shape)
''' torch.Size([1, 3, 3]) torch.Size([3, 3, 3]) torch.Size([2, 3, 3]) torch.Size([2, 3, 3]) '''
4.4 chunk操作
#tensor拆分
import torch
a = torch.rand(4,3,3)
bb,cc,dd,ee = torch.chunk(a,4,dim=0) #将零维度拆分为4个块
print(bb.shape)
print(cc.shape)
print(dd.shape)
print(ee.shape)
''' torch.Size([1, 3, 3]) torch.Size([1, 3, 3]) torch.Size([1, 3, 3]) torch.Size([1, 3, 3]) '''
5. 统计属性
5.1 范数 norm
import torch
a = torch.full([8],1, dtype = torch.float)
b = a.view(2,4)
c = a.view(2,2,2)
print(a.norm(1), b.norm(1), c.norm(1))
print(a.norm(2), b.norm(2), c.norm(2))
print(b.norm(1, dim = 1))
print(c.norm(2, dim = 0))
''' tensor(8.) tensor(8.) tensor(8.) tensor(2.8284) tensor(2.8284) tensor(2.8284) tensor([4., 4.]) tensor([[1.4142, 1.4142], [1.4142, 1.4142]]) '''
5.2 mean,sum,min,max,prod
import torch
a = torch.arange(8).view(2,4).float()
# mean,max,min等如果没有指定维度,则会将tensor展平,然后再统计
print(a.min(), a.max())
print(a.sum(), a.mean())
print(a.prod())
print(a.argmax(), a.argmin())
''' tensor(0.) tensor(7.) tensor(28.) tensor(3.5000) tensor(0.) tensor(7) tensor(0) '''
import torch
t = torch.arange(8).reshape(2,4).float()
print('**Caculate after flatten..')
print(t.max())
print(t.min())
print(t.sum())
print(t.mean())
print(t.prod())
print('**Get the position of the max/min elements on all dim..')
print(t.argmax())
print(t.argmin())
# dim指定维度
print('**Gaculate on special dim..')
print(t.mean(1))
print(t.max(1))
print(t.min(0))
print(t.sum(0))
print(t.prod(1))
''' **Caculate after flatten.. tensor(7.) tensor(0.) tensor(28.) tensor(3.5000) tensor(0.) **Get the position of the max/min elements on all dim.. tensor(7) tensor(0) **Gaculate on special dim.. tensor([1.5000, 5.5000]) torch.return_types.max( values=tensor([3., 7.]), indices=tensor([3, 3])) torch.return_types.min( values=tensor([0., 1., 2., 3.]), indices=tensor([0, 0, 0, 0])) tensor([ 4., 6., 8., 10.]) tensor([ 0., 840.]) '''
import torch
t = torch.arange(8).reshape(2,4).float()
print('**Gaculate on special dim..')
print(t.max(1, keepdim=True))
print(t.min(0, keepdim=True))
print(t.sum(0, keepdim=True))
''' **Gaculate on special dim.. torch.return_types.max( values=tensor([[3.], [7.]]), indices=tensor([[3], [3]])) torch.return_types.min( values=tensor([[0., 1., 2., 3.]]), indices=tensor([[0, 0, 0, 0]])) tensor([[ 4., 6., 8., 10.]]) '''
5.3 top-k k-th
import torch
t = torch.arange(8).reshape(2,4).float() #K大值
t2 = t.topk(3, dim=1)
print(t2)
t3 = t.topk(3, dim=1, largest=False) #K小值
print(t3)
print('*'*20)
t4 = t.kthvalue(2, dim=1)
print(t4)
''' torch.return_types.topk( values=tensor([[3., 2., 1.], [7., 6., 5.]]), indices=tensor([[3, 2, 1], [3, 2, 1]])) torch.return_types.topk( values=tensor([[0., 1., 2.], [4., 5., 6.]]), indices=tensor([[0, 1, 2], [0, 1, 2]])) ******************** torch.return_types.kthvalue( values=tensor([1., 5.]), indices=tensor([1, 1])) '''
6. Tensor的高阶操作
6.1 where
import torch
cond = torch.tensor([[0.6,0.7],[0.8,0.4]])
a = torch.ones(2,2)
b = torch.zeros(2,2)
c = torch.where(cond>0.6, a,b)
print(c)
''' tensor([[0., 1.], [1., 0.]]) '''
6.2 gather
import torch
table = torch.arange(4,8)
index = torch.tensor([0,2,1,0,3,0])
t = torch.gather(table,dim=0,index=index)
print(t)
''' tensor([4, 6, 5, 4, 7, 4]) '''
边栏推荐
- SQL Basics
- New employees of black maredge takeout
- Silicon Valley class lesson 6 - Tencent cloud on demand management module (I)
- 第二部分—C语言提高篇_12. 动/精态库的封装和使用
- About statefulwidget, you have to know the principle and main points!
- Distributed lock and its implementation
- Product principles of non-financial decentralized application
- Silicon Valley class lesson 5 - Tencent cloud object storage and course classification management
- 如何使用数据管道实现测试现代化
- 第二部分—C语言提高篇_9. 链表
猜你喜欢
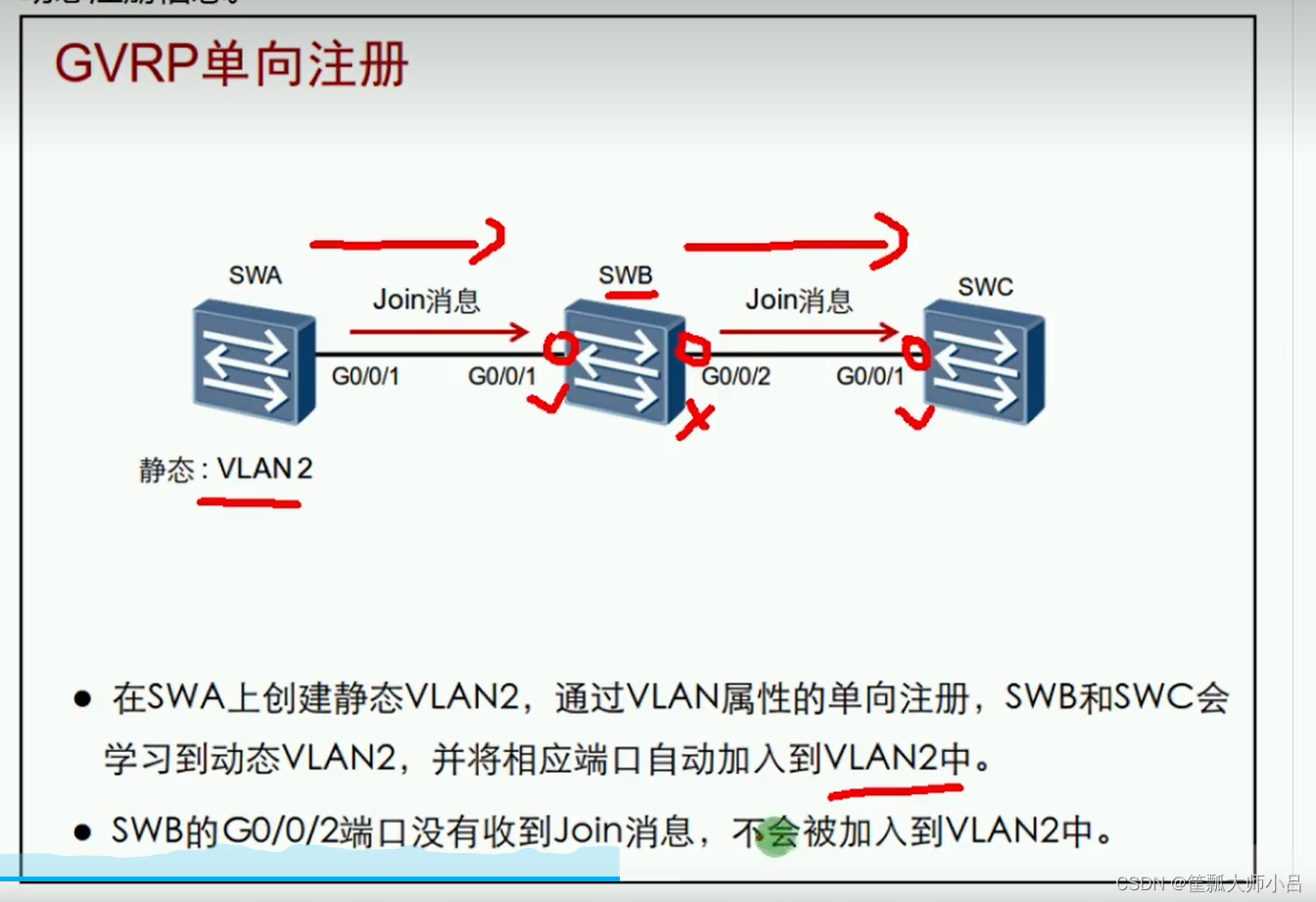
Hcia-r & s self use notes (20) VLAN comprehensive experiment, GVRP

How to transfer the GPX data collected by CTI RTK out of KML and SHP with attributes for subsequent management and analysis

np.transpose & np.expand_dims

MySQL random paging to get non duplicate data

SQL 基础知识

Basic select statement
华测RTK采集的GPX数据如何带属性转出kml、shp进行后续的管理和分析
Practical project: boost search engine

【flask高级】结合源码分析flask中的线程隔离机制

研究阿尔茨海默病最经典的Nature论文涉嫌造假
随机推荐
Download win10 system image and create virtual machine on VMware virtual machine
华测RTK采集的GPX数据如何带属性转出kml、shp进行后续的管理和分析
Thousands of tiles' tilt model browsing speeds up, saying goodbye to the embarrassment of jumping out one by one
Vit:vision transformer super detailed with code
会议OA之我的会议
DAO:OP 代币和不可转让的 NFT 致力于建立新的数字民主
[postgresql]postgresqlg use generate_ Series() function completes statistics
Concept of functional interface & definition and use of functional interface
Lesson 2 of Silicon Valley classroom - building project environment and developing lecturer management interface
2022.7.26-----leetcode.1206
上千Tile的倾斜模型浏览提速,告别一块一块往外蹦的尴尬
Dao:op token and non transferable NFT are committed to building a new digital democracy
Part II - C language improvement_ 8. File operation
P5469 [NOI2019] 机器人(拉格朗日插值、区间dp)
HCIA-R&S自用笔记(21)STP技术背景、STP基础和数据包结构、STP选举规则及案例
[shader realizes swaying effect _shader effect Chapter 4]
杭州银行面试题【杭州多测师】【杭州多测师_王sir】
Re understand the life world and ourselves
Product principles of non-financial decentralized application
Easily implement seckill system with redis! (including code)