当前位置:网站首页>Federal learning: dividing non IID samples by Dirichlet distribution
Federal learning: dividing non IID samples by Dirichlet distribution
2022-06-30 02:55:00 【Illusory private school】
Python Wechat ordering applet course video
https://edu.csdn.net/course/detail/36074
Python Actual quantitative transaction financial management system
https://edu.csdn.net/course/detail/35475
We are 《Python Random sampling and probability distribution in ( Two )》 It describes how to use Python The existing library samples a probability distribution , Among them Dirichlet The distribution must be familiar to everyone . The probability density function of this distribution is
P(x;α)∝k∏i=1xαi−1ix=(x1,x2,…,xk),xi>0,k∑i=1xi=1α=(α1,α2,…,αk).αi>0P(\bm{x}; \bm{\alpha}) \propto \prod_{i=1}^{k} x_{i}^{\alpha_{i}-1} \
\bm{x}=(x_1,x_2,…,x_k),\quad x_i > 0 , \quad \sum_{i=1}^k x_i = 1\
\bm{\alpha} = (\alpha_1,\alpha_2,…, \alpha_k). \quad \alpha_i > 0
among α\bm{\alpha} Is the parameter .
We are studying in the Federation , Different assumptions are often made client The data set between does not satisfy independent identically distributed (Non-IID). So how do we compare an existing dataset to Non-IID Division ? We know that the generation distribution of labeled samples can be expressed as p(x,y)p(\bm{x}, y), We further write it p(x,y)=p(x|y)p(y)p(\bm{x}, y)=p(\bm{x}|y)p(y). If you want to estimate p(x|y)p(\bm{x}|y) The computational overhead is very large , But estimate p(y)p(y) The computing overhead is very small . So we analyze the samples according to the label distribution of the samples Non-IID Partitioning is a very efficient 、 Simple approach .
To make a long story short , The algorithm we adopt is to make every client The sample labels on the are distributed differently . We have KK Category tags ,NN individual client, The sample of each category label needs to be divided into different categories according to different proportions client On . Let's set the matrix X∈RK∗N\bm{X}\in \mathbb{R}^{K*N} Distribution matrix for category labels , Its row vector xk∈RN\bm{x}_k\in \mathbb{R}^N Presentation category kk In different client Probability distribution vector on ( Each dimension represents kk Samples of categories are divided into different client The proportion of ), The random vector is sampled from Dirichlet Distribution .
Accordingly , We can write the following partition algorithm :
import numpy as np
np.random.seed(42)
def split\_noniid(train\_labels, alpha, n\_clients):
'''
Parameter is alpha Of Dirichlet Distribution divides the data index into n\_clients A subset of
'''
n_classes = train_labels.max()+1
label_distribution = np.random.dirichlet([alpha]*n_clients, n_classes)
# (K, N) Class label distribution matrix X, Record each client How much of each category
class_idcs = [np.argwhere(train_labels==y).flatten()
for y in range(n_classes)]
# Record each K Sample subscripts corresponding to categories
client_idcs = [[] for _ in range(n_clients)]
# Record N individual client Respectively corresponding to the index of the sample set
for c, fracs in zip(class_idcs, label_distribution):
# np.split Categorize proportionally as k The sample is divided into N A subset of
# for i, idcs To traverse the i individual client The index of the corresponding sample set
for i, idcs in enumerate(np.split(c, (np.cumsum(fracs)[:-1]*len(c)).astype(int))):
client_idcs[i] += [idcs]
client_idcs = [np.concatenate(idcs) for idcs in client_idcs]
return client_idcs
Plus, we're EMNIST Call this function on the dataset to test , And visualize it . We set up client Number N=10N=10,Dirichlet Parameter vector of probability distribution α\bm{\alpha} Satisfy αi=1.0, i=1,2,…N\alpha_i=1.0,\space i=1,2,…N:
import torch
from torchvision import datasets
import numpy as np
import matplotlib.pyplot as plt
torch.manual_seed(42)
if __name__ == "\_\_main\_\_":
N_CLIENTS = 10
DIRICHLET_ALPHA = 1.0
train_data = datasets.EMNIST(root=".", split="byclass", download=True, train=True)
test_data = datasets.EMNIST(root=".", split="byclass", download=True, train=False)
n_channels = 1
input_sz, num_cls = train_data.data[0].shape[0], len(train_data.classes)
train_labels = np.array(train_data.targets)
# Let's make each client Different label The number of samples is different , To do so Non-IID Divide
client_idcs = split_noniid(train_labels, alpha=DIRICHLET_ALPHA, n_clients=N_CLIENTS)
# Show different client Different label Data distribution of
plt.figure(figsize=(20,3))
plt.hist([train_labels[idc]for idc in client_idcs], stacked=True,
bins=np.arange(min(train_labels)-0.5, max(train_labels) + 1.5, 1),
label=["Client {}".format(i) for i in range(N_CLIENTS)], rwidth=0.5)
plt.xticks(np.arange(num_cls), train_data.classes)
plt.legend()
plt.show()
The final visualization results are as follows :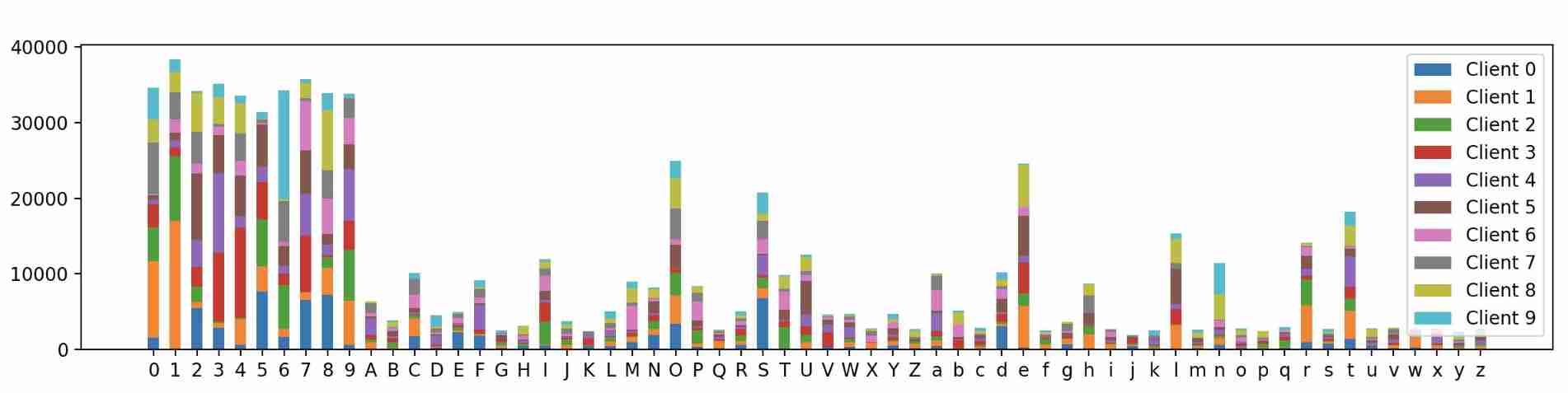
You can see ,62 Category labels are in different client The distribution on is really different , It is proved that our sample partition algorithm is effective .
边栏推荐
- Summary of knowledge points about eigenvalues and eigenvectors of matrices in Chapter 5 of Linear Algebra (Jeff's self perception)
- Xunwei enzhipu ITop - imx6 Development Platform
- (图论) 连通分量(模板) + 强连通分量(模板)
- Uniapp address translation latitude and longitude
- Five cheapest wildcard SSL certificate brands
- How to prevent duplicate submission under concurrent requests
- HTA introductory basic tutorial | GUI interface of vbs script HTA concise tutorial, with complete course and interface beautification
- 并发请求下如何防重复提交
- Servlet面试题
- 怎样的外汇交易平台是有监管的,是安全的?
猜你喜欢

CMake教程系列-02-使用cmake代碼生成二進制

Mysql表数据比较大情况下怎么修改添加字段

How to prevent phishing emails? S/mime mail certificate

Five cheapest wildcard SSL certificate brands

What is certificate transparency CT? How to query CT logs certificate logs?

Linear algebra Chapter 4 Summary of knowledge points of linear equations (Jeff's self perception)
微信小程序页面跳转以及参数传递

Raki's notes on reading paper: discontinuous named entity recognition as maximum clique discovery

IBM WebSphere channel connectivity setup and testing

2.< tag-动态规划和0-1背包问题>lt.416. 分割等和子集 + lt.1049. 最后一块石头的重量 II
随机推荐
中断操作:AbortController学习笔记
Study diary: February 15, 2022
Xunwei enzhipu ITop - imx6 Development Platform
怎么利用Redis实现点赞功能
Two methods of SSL certificate format conversion
可视化HTA窗体设计器-HtaMaker 界面介绍及使用方法,下载 | HTA VBS可视化脚本编写
Welfare lottery | what are the highlights of open source enterprise monitoring zabbix6.0
Cmake tutorial series -04- compiling related functions
2022 underground coal mine electrical test and underground coal mine electrical simulation test
外汇交易平台哪个好?有监管的资金就安全吗?
uniapp 地址转换经纬度
自定义JvxeTable的按钮及备注下$set的用法
怎样的外汇交易平台是有监管的,是安全的?
Servlet面试题
2022 the action of protecting the net is imminent. Things about protecting the net
Global and Chinese markets for light cargo conveyors 2022-2028: Research Report on technology, participants, trends, market size and share
Sitelock nine FAQs
[dry goods sharing] the latest WHQL logo certification application process
Uniapp address translation latitude and longitude
High paid programmers & interview questions series 63: talk about the differences between sleep (), yield (), join (), and wait ()