当前位置:网站首页>不止于ZeRO:BMTrain技术原理浅析
不止于ZeRO:BMTrain技术原理浅析
2022-06-21 12:32:00 【智源社区】

支撑起 BMTrain 优异性能表现的是其采用的多项分布式训练优化技术,它们共同解决了大模型训练过程中的 显存占用 问题。为了深刻理解这一关键问题,我们不妨分析一下模型训练过程中的显存占用情况。
模型训练中的显存占用主要包括:模型参数、模型梯度、优化器状态、运算中间变量。以下图为例,训练过程中的显存占用包括一份模型参数以及对应的一份梯度,比较常用的 Adam 会保留两倍参数量的优化器参数,除此之外还有一些运算的中间变量。

 背景知识
背景知识
01 Broadcast
张量位于某张显卡中,广播后,每张显卡都会获得一个同样的张量。

02 Reduce
每张显卡中存有一个张量,将这些张量进行如求和、取max等计算后,其结果被置于指定的某张显卡上。

03 All Reduce



![]() 分布式训练
分布式训练
一种典型的分布式训练方法是使用数据并行,然而对于大模型来说,仅通过数据并行进行显存优化是远远不够的,我们需要更进一步地进行切割。进一步优化的技术主要来自两大技术路线:在算子层面进行切割的 模型并行、流水线并行技术 以及在显存上进行切割的 ZeRO技术。在BMTrain中,我们采用了 数据并行 和 ZeRO技术 来进行模型的分布式训练,并将陆续支持模型并行与流水线并行。
数据并行

模型并行
 ,通过将参数矩阵分解为n个小矩阵
,通过将参数矩阵分解为n个小矩阵 ,每张显卡上计算
,每张显卡上计算  , 然后通过 all-gather 通信即可获得完整的结果
, 然后通过 all-gather 通信即可获得完整的结果 。在这种方法中,各张显卡均处理同一批次的数据,在计算时进行合作。
。在这种方法中,各张显卡均处理同一批次的数据,在计算时进行合作。 
ZeRO
在实际训练中,优化器 ( 如 Adam ) 状态占用的显存要比参数和梯度二者加起来还要多,因此 ZeRO(Zero Redundancy Optimizer,零冗余优化器)技术首次提出对优化器状态进行切分,每张显卡上只负责优化器状态对应的部分参数的更新。训练策略上,ZeRO 基于数据并行,不同的数据被划分到不同的显卡上进行计算。根据对优化器状态、梯度、参数划分程度的不同,ZeRO 技术包含 ZeRO-1/2/3 三个层次。
ZeRO-1

ZeRO-2

ZeRO-3


不过在 ZeRO 的原论文中指出, ZeRO-3 增加了额外的一次参数通信时间(即反向传播时的 all-gather ),因此会引入额外的通信开销,在部分场景下性能不及 ZeRO-2 和模型并行。为了减少额外通信量带来的效率损失,我们还额外引入了通信计算重叠的策略,这将在后面被介绍到。根据我们的实现,实验结果表明 ZeRO-3 在 NVLink+IB 的环境下训练超大规模模型较联合使用 ZeRO-2 和模型并行的方案会带来更大的计算吞吐量提升。
![]()
 显存优化
显存优化
Optimizer Offload


- 图 Optimizer Offload 技术
Checkpointing
Checkpointing 技术是一项很早就被提出,用于优化神经网络模型训练时计算图开销的方法。这种方法在 Transformers 等结构的模型训练中,能够起到非常明显的作用。目前主流的 Transformers 模型由大量的全连接层组成,我们以全连接层为例进行计算图的显存分析。

 与输入
与输入 ,这两部分参数随着正向传播逐层累积,消耗了非常多的显存。
,这两部分参数随着正向传播逐层累积,消耗了非常多的显存。
框架实现的优化
混合精度
传统模型使用单精度参数进行训练,在大模型训练中,我们可以通过使用半精度参数来降低参数量并节省运算时间。具体实现上,BMTrain 在正向传播和反向传播的过程中均使用半精度进行计算,并在优化器中维护单精度的模型参数和优化器参数。
使用混合精度的另一个好处在于能够更好地利用显卡中的 tensor core。较新的显卡在 CUDA core 之外,还设置了专门用于张量运算的核心 tensor core,利用 tensor core 将为程序带来进一步的性能提升。使用混合精度训练能够更好地利用 tensor core 特性,从而为训练过程进一步加速。
算子融合
为了进一步提升性能,我们在 CPU 和 GPU 层面均进行了算子层面的实现优化。在 CPU 上,我们使用多线程 + SIMD(单指令流多数据流) 的 CPU 编程方式,对 Offload 至 CPU 计算的 Adam 优化器进行 CPU 上的计算加速,使其不会成为系统的性能瓶颈。在 GPU 上,我们使用算子融合的方式,将 Softmax 与 NLLLoss 算子合二为一,减小了中间结果的显存占用。
通信计算重叠
上文中提到,ZeRO3 技术将引入额外的通信时间,我们采用通信计算策略来进行通信时间的优化。以反向传播为例,由于使用了 ZeRO-3 技术,需要将切碎至各个计算卡上的模型进行临时的重组装(对应图中的 Gather );而在反向传播 ( 对应图中的 Calculate ) 之后,我们还需要将得到的局部梯度重新切碎至不同的计算卡上(对应图中的 Scatter )。我们通过不同的 CUDA stream 区分不同的操作,让运算和通信得以同时运行,通过大量的计算时间隐藏通信的时间开销。
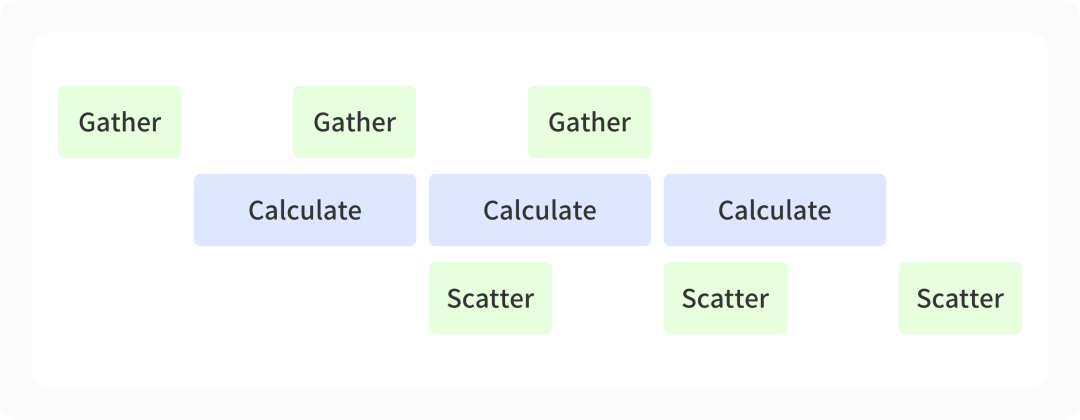
- 图 通信计算重叠
性能展示

未来展望
关注我们


边栏推荐
- 12 tips for achieving it agility in the digital age
- uva11292
- 如何手动删除浮动ip
- Workbench常见网格划分方法讲解
- 智能辅助系统在配电室内的施工方案 安装位置
- uva11991
- 为什么世界上只有13个根域名服务器
- Educoder web exercises -- text level semantic elements
- Methods commonly used in uniapp (part) - timestamp problem and rich text parsing image problem
- PingCAP 入选 2022 Gartner 云数据库“客户之声”,获评“卓越表现者”最高分
猜你喜欢
Five (seven) principles - systematic learning III

Educator table labels - settings for Advanced Table Styles

Educator web exercise - creating input controls
STM32 notes swj (jtag-dp and sw-dp)
![[安洵杯 2019]easy_web-1](/img/1d/f164c220f6c8e98b981ef79b0e96bc.png)
[安洵杯 2019]easy_web-1

TOOD: Task-aligned One-stage Object Detection

一篇文章带你搞懂什么是DevOps?

Educator web exercises - grouping elements

一文掌握SQLite3基本用法

卷积神经网络“卷积”的深层理解
随机推荐
[100 unity pit knowledge points] | unity uses quaternion Angleaxis random one direction
Educoder web exercises - interactive elements
Redis最大内存淘汰策略
uva11995
Router telnet and ACL configuration
Educator web exercises - grouping elements
【Appium踩坑】关闭inspector后打开weditor,uiautomator2.exceptions.NullPointerExceptionError: -32001 Jsonrpc er
Educoder Web练习题---对表单进行验证
常用的17个运维监控系统
Educator web exercise - create a drop-down list
Common instructions for five basic data types in redis
EasyUI input fetch / assign
五大(七大)原则-系统学习三
配電室環境監控系統技術方案
TOOD: Task-aligned One-stage Object Detection
PostgreSQL 逻辑存储结构
TOOD: Task-aligned One-stage Object Detection
Educoder Web练习题---分组元素
Educoder 表格标签—表格高级样式的设置
[appium stepping pit] close the inspector and open the WebEditor, uiautomator2 exceptions. NullPointerExceptionError: -32001 Jsonrpc er