当前位置:网站首页>Master slave synchronization step read / write separation + self encountered error sharing
Master slave synchronization step read / write separation + self encountered error sharing
2022-07-23 11:05:00 【Qingchi】
Necessity of existence :
MySQL There is only one server , Then there may be the following problems :
1). All the pressure of reading and writing is borne by one database , High pressure
2). If the database server disk is damaged, the data will be lost , A single point of failure
Solution : Prepare two MySQL, A master (Master) The server , One from (Slave) The server , The data of the main database changes , Need to synchronize to and from the library ( Master slave copy ). And when users visit our project , If it's a write operation (insert、update、delete), Then directly operate the main library ; If it's reading (select) operation , Then directly operate from the library ( In this read-write separation structure , There can be multiple from the library ), This structure is called Read / write separation .
MySQL Master-slave replication is an asynchronous replication process , The bottom layer is based on Mysql The database comes with Binary log function . Just one or more MySQL database (slave, namely Slave Library ) From the other MySQL database (master, namely Main library ) Copy logs , Then parse the log and apply it to itself , Final realization Slave Library The data and Main library The data are consistent .MySQL Master slave replication is MySQL The database has its own functions , No third party tools required .
Binary log :
Binary log (BINLOG) It records all the DDL( Data definition language ) Statement and DML( Data manipulation language ) sentence , But it does not include data query statements . This log plays an extremely important role in data recovery in case of disaster ,MySQL Master-slave replication of , Through this binlog Realized . Default MySQL The log is not opened .
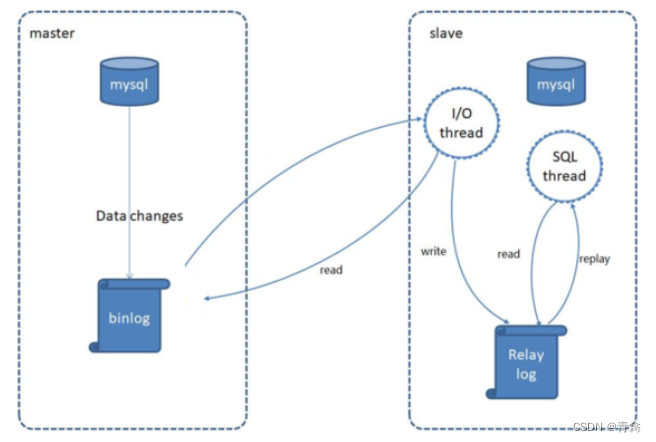
MySQL The replication process is divided into three steps :
1). MySQL master Write data changes to binary log ( binary log)
2). slave take master Of binary log Copy to its trunk log (relay log)
3). slave Redo events in relay log , Change the data to reflect its own data
Prepare two servers in advance , And install... In the server MySQL
And do the following preparations on the two servers :
Firewall opening 3306 Port number :
firewall-cmd --zone=public --add-port=3306/tcp --permanent
firewall-cmd --zone=public --list-portsMain library configuration :
The database server starts :systemctl start mysqld
Sign in mysql : mysql -u**** -p**** (**** For user name and password )
Check the status Systemctl status mysqld Database status view
modify Mysql Profile of the database /etc/my.cnf
log-bin=mysql-bin #[ must ] Enable binary logging
server-id=200 #[ must ] The server is unique ID( The only can )restart Mysql service :systemctl restart mysqld
Create a user for data synchronization and authorize
GRANT REPLICATION SLAVE ON *.* to '****'@'%' identified by '****'; (**** For user name and password )Sign in Mysql database , see master sync
Do the following SQL, Record the results File and Position Value
show master status;
The main database configuration is completed You don't need to move, which may change the state
Configuration from library :
modify Mysql Profile of the database /etc/my.cnf :
server-id=201 #[ must ] The server is unique IDrestart Mysql service systemctl restart mysqld
Sign in Mysql database , Set the main database address and synchronization location
change master to master_host='192.168. Your own host IP',master_user=' The user name of the main database ',master_password=' The password of the main database ',master_log_file='File',master_log_pos=Position;
start slave; start-up
If you make a mistake perform stop slave; Repeat the above steps
show slave status; View from database status Parameter description :
A. master_host : The main library IP Address
B. master_user : User name to access the master database for master-slave replication ( Created in the main library above )
C. master_password : The password corresponding to the user name that accesses the master database for master-slave replication
D. master_log_file : Which log file to start synchronization from ( The above query master The status shows )
E. master_log_pos : Specify the location of the log file from which to start synchronization ( The above query master The status shows )
Then through the... In the status information Slave_IO_running and Slave_SQL_running It can be seen whether the master-slave synchronization is ready , If both parameters are Yes, Indicates that master-slave synchronization has been configured .
if Slave_IO_Running: no/connecting
Slave_SQL_Running: yes
/var/lib/mysql/auto.cnf In this directory server_id need Change it ------ Put the last 0 Just set up one 1 Just numbers ( the last one 0) There are reasons for cloning virtual machines
Slave_IO_Running: no/connecting
Slave_SQL_Running: No
1. The program may be in slave Write operation on
2. It could be slave After the machine is lifted , Caused by transaction rollback .
Generally, it is caused by transaction rollback :
terms of settlement :
mysql> stop slave ;
mysql> set GLOBAL SQL_SLAVE_SKIP_COUNTER=1;
mysql> start slave ;
Then connect the graphical database interface
Try creating databases and tables , Add whether the data in the table is synchronized
Read / write separation
In the face of increasing system access , Database throughput is facing a huge bottleneck . For an application system with a large number of concurrent read operations and fewer write operations at the same time , Split the database into Main library and Slave Library , The main database is responsible for the transaction of addition, deletion and modification , The slave library is responsible for handling query operations , It can effectively avoid row lock caused by data update , The query performance of the whole system has been greatly improved .

Separate by reading and writing , You can reduce the access pressure of a single database , Improve access efficiency , It can also avoid single machine failure .
The structure of master-slave replication , We're done , In the project , adopt java Code to complete read-write separation , In execution select When querying from the library , In execution insert、update、delete When operating the main database , We need a new technology ShardingJDBC.
Sharding-JDBC Position as lightweight Java frame , stay Java Of JDBC Additional services provided by layer . It uses the client direct connection database , With jar Service in package form , No additional deployment and dependencies , Can be understood as an enhanced version of JDBC drive , Fully compatible with JDBC And all kinds of ORM frame .
Use Sharding-JDBC You can easily realize the separation of database reading and writing in the program .
Sharding-JDBC It has the following characteristics :
1). Apply to any based on JDBC Of ORM frame , Such as :JPA, Hibernate, Mybatis, Spring JDBC Template Or use it directly JDBC.
2). Support database connection pool of any third party , Such as :DBCP, C3P0, BoneCP, Druid, HikariCP etc. .
3). Support arbitrary implementation JDBC Standardized database . At present, we support MySQL,Oracle,SQLServer,PostgreSQL And any compliance with SQL92 Standard database .
rely on :
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-boot-starter</artifactId>
<version>4.0.0-RC1</version>
</dependency>stay application.yml Add the configuration of data source in
spring:
shardingsphere:
datasource:
names:
master,slave
# The main data source
master:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://192.168.*.*:3306/**?characterEncoding=utf-8&useSSL=false
username:****
password: ****
# From a data source
slave:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://192.168.*.*:3306/**?characterEncoding=utf-8&useSSL=false
username: ****
password: ****
masterslave:
# Read write separation configuration
load-balance-algorithm-type: round_robin # polling
# The final data source name
name: dataSource
# Main database data source name
master-data-source-name: master
# From the list of library data source names , Multiple commas separate
slave-data-source-names: slave
props:
sql:
show: true # Turn on SQL Show , Default false
main:
allow-bean-definition-overriding: true
notes :* Configure content for yourself 边栏推荐
- 村田muRata电源维修交换机服务器电源维修及主要功能特点
- sort
- PMP practice once a day | don't get lost in the exam -7.22
- EntityManagerFactory和EntityManager的一个用法探究
- 12 open source background management systems suitable for outsourcing projects
- 6、重心坐标插值和图形渲染管线
- Detailed explanation of structure
- H1 -- HDMI interface test application 2022-07-15
- Huck hurco industrial computer maintenance winmax CNC machine tool controller maintenance
- Basic concepts of software testing
猜你喜欢

结构体详解

Powerbi Getting Started Guide

Visual studio 2022 interesting and powerful intelligent auxiliary coding
主从同步步骤读写分离+自遇错误分享
Fundamentals of software testing - design method of test cases

防止神经网络过拟合的五种方法

Understand asp Net core - Cookie based authentication

Cadence (IX) 17.4 rules and spacing settings

Redis源碼與設計剖析 -- 7.快速列錶

C语言n番战--链表(九)
随机推荐
8. Surface geometry
PyTorch(五)——PyTorch进阶训练技巧
Redis源碼與設計剖析 -- 7.快速列錶
Redis源码与设计剖析 -- 6.压缩列表
Updated again, idea 2022.2 officially released
【Anaconda 环境管理与包管理】
6. Barycentric coordinate interpolation and graphics rendering pipeline
Concepts et différences de bits, bits, octets et mots
3DMAX first skin brush weights, then attach merge
Notes and Thoughts on the red dust of the sky (IV) invalid mutual value
Two strategies for building AI products / businesses (by Andrew ng)
6、重心坐标插值和图形渲染管线
FFmpeg 音频编码
H1 -- HDMI interface test application 2022-07-15
Single sign on - how to unify the expiration time of session between authentication server and client
A case study on the collaborative management of medical enterprise suppliers, hospitals, patients and other parties by building a low code platform
Activiti工作流使用之流程结构介绍
Data Lake: introduction to delta Lake
Visual studio 2022 interesting and powerful intelligent auxiliary coding
一次 MySQL 误操作导致的事故,「高可用」都不好使了