当前位置:网站首页>Data Lake (19): SQL API reads Kafka data and writes it to Iceberg table in real time
Data Lake (19): SQL API reads Kafka data and writes it to Iceberg table in real time
2022-07-31 11:36:00 【Lanson】
SQL API 读取Kafka数据实时写入Iceberg表
从Kafka中实时读取数据写入到Iceberg表中,操作步骤如下:
一、首先需要创建对应的Iceberg表
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tblEnv = StreamTableEnvironment.create(env);
env.enableCheckpointing(1000);
//1.创建Catalog
tblEnv.executeSql("CREATE CATALOG hadoop_iceberg WITH (" +
"'type'='iceberg'," +
"'catalog-type'='hadoop'," +
"'warehouse'='hdfs://mycluster/flink_iceberg')");
//2.创建iceberg表 flink_iceberg_tbl
tblEnv.executeSql("create table hadoop_iceberg.iceberg_db.flink_iceberg_tbl3(id int,name string,age int,loc string) partitioned by (loc)");
二、编写代码读取Kafka数据实时写入Iceberg
public class ReadKafkaToIceberg {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment tblEnv = StreamTableEnvironment.create(env);
env.enableCheckpointing(1000);
/**
* 1.需要预先创建 Catalog 及Iceberg表
*/
//1.创建Catalog
tblEnv.executeSql("CREATE CATALOG hadoop_iceberg WITH (" +
"'type'='iceberg'," +
"'catalog-type'='hadoop'," +
"'warehouse'='hdfs://mycluster/flink_iceberg')");
//2.创建iceberg表 flink_iceberg_tbl
// tblEnv.executeSql("create table hadoop_iceberg.iceberg_db.flink_iceberg_tbl3(id int,name string,age int,loc string) partitioned by (loc)");
//3.创建 Kafka Connector,连接消费Kafka中数据
tblEnv.executeSql("create table kafka_input_table(" +
" id int," +
" name varchar," +
" age int," +
" loc varchar" +
") with (" +
" 'connector' = 'kafka'," +
" 'topic' = 'flink-iceberg-topic'," +
" 'properties.bootstrap.servers'='node1:9092,node2:9092,node3:9092'," +
" 'scan.startup.mode'='latest-offset'," +
" 'properties.group.id' = 'my-group-id'," +
" 'format' = 'csv'" +
")");
//4.配置 table.dynamic-table-options.enabled
Configuration configuration = tblEnv.getConfig().getConfiguration();
// 支持SQL语法中的 OPTIONS 选项
configuration.setBoolean("table.dynamic-table-options.enabled", true);
//5.写入数据到表 flink_iceberg_tbl3
tblEnv.executeSql("insert into hadoop_iceberg.iceberg_db.flink_iceberg_tbl3 select id,name,age,loc from kafka_input_table");
//6.查询表数据
TableResult tableResult = tblEnv.executeSql("select * from hadoop_iceberg.iceberg_db.flink_iceberg_tbl3 /*+ OPTIONS('streaming'='true', 'monitor-interval'='1s')*/");
tableResult.print();
}
}
启动以上代码,向Kafka topic中生产如下数据:
1,zs,18,beijing
2,ls,19,shanghai
3,ww,20,beijing
4,ml,21,shanghai
我们可以看到控制台上有对应实时数据输出,查看对应的Icberg HDFS目录,数据写入成功.
边栏推荐
- 7 天找个 Go 工作,Gopher 要学的条件语句,循环语句 ,第3篇
- 才22岁!这位'00后'博士拟任职985高校!
- 如何正确地把服务器端返回的文件二进制流写入到本地保存成文件
- 内网渗透学习(四)域横向移动——SMB和WMI服务利用
- Docker build Mysql master-slave replication
- 最全phpmyadmin漏洞汇总
- In PLC communication error or timeout or download the prompt solution of the model
- Summary of several defragmentation schemes for MySQL (to solve the problem of not releasing space after deleting a large amount of data)
- 初始JDBC 编程
- 分布式事务Seata详细使用教程
猜你喜欢

Redis-基础

透过开发抽奖小程序,体会创新与迭代

Candence学习篇(11) allegro中设置规则,布局,走线,铺铜

一周精彩内容分享(第14期)
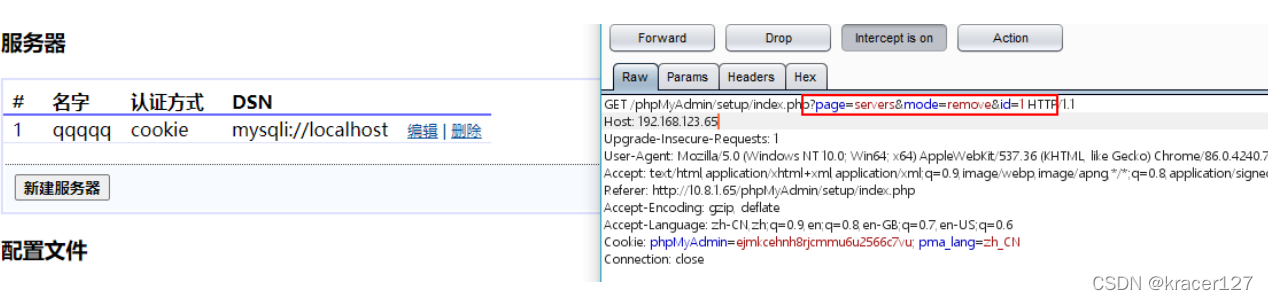
The most complete phpmyadmin vulnerability summary

“带薪划水”偷刷阿里老哥的面经宝典,三次挑战字节,终成正果
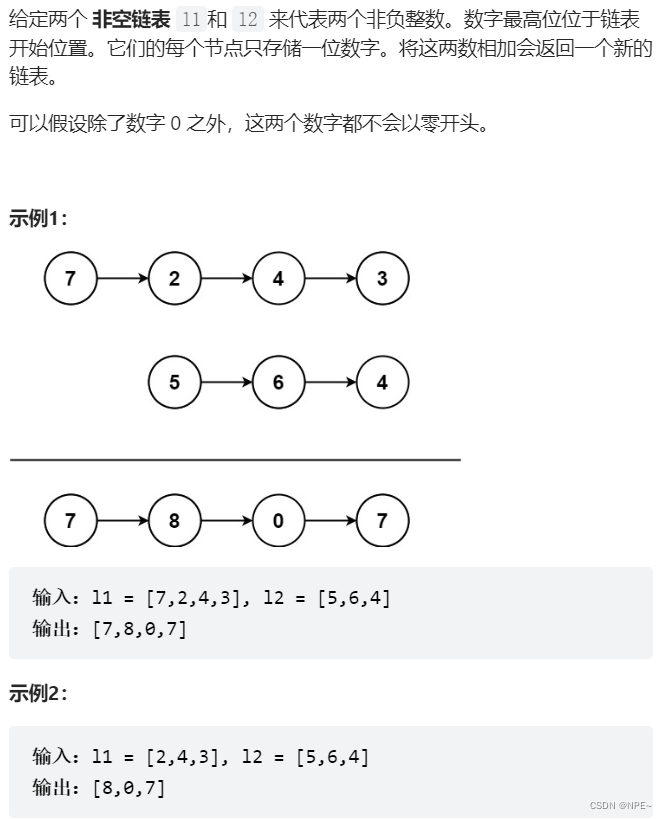
LeetCode - 025. 链表中的两数相加

一、excel转pdf格式jacob.jar
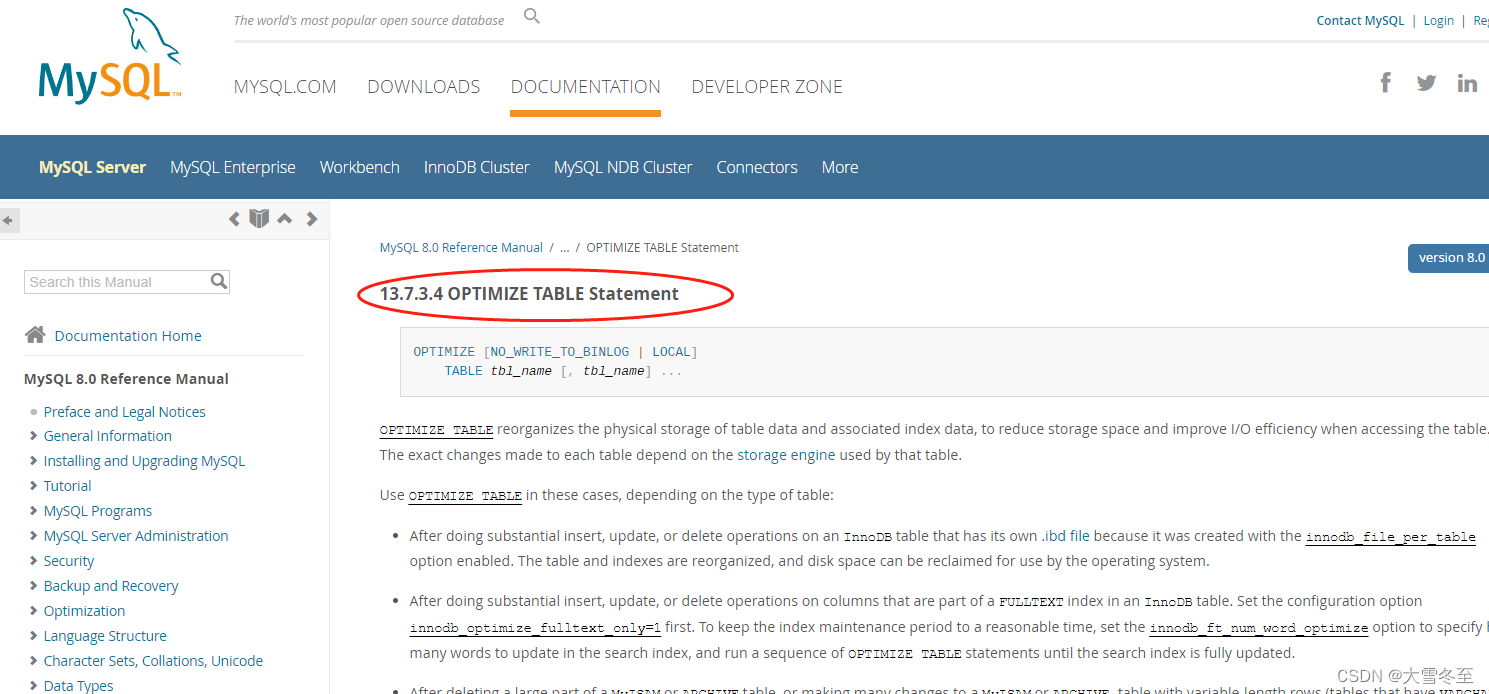
Summary of several defragmentation schemes for MySQL (to solve the problem of not releasing space after deleting a large amount of data)
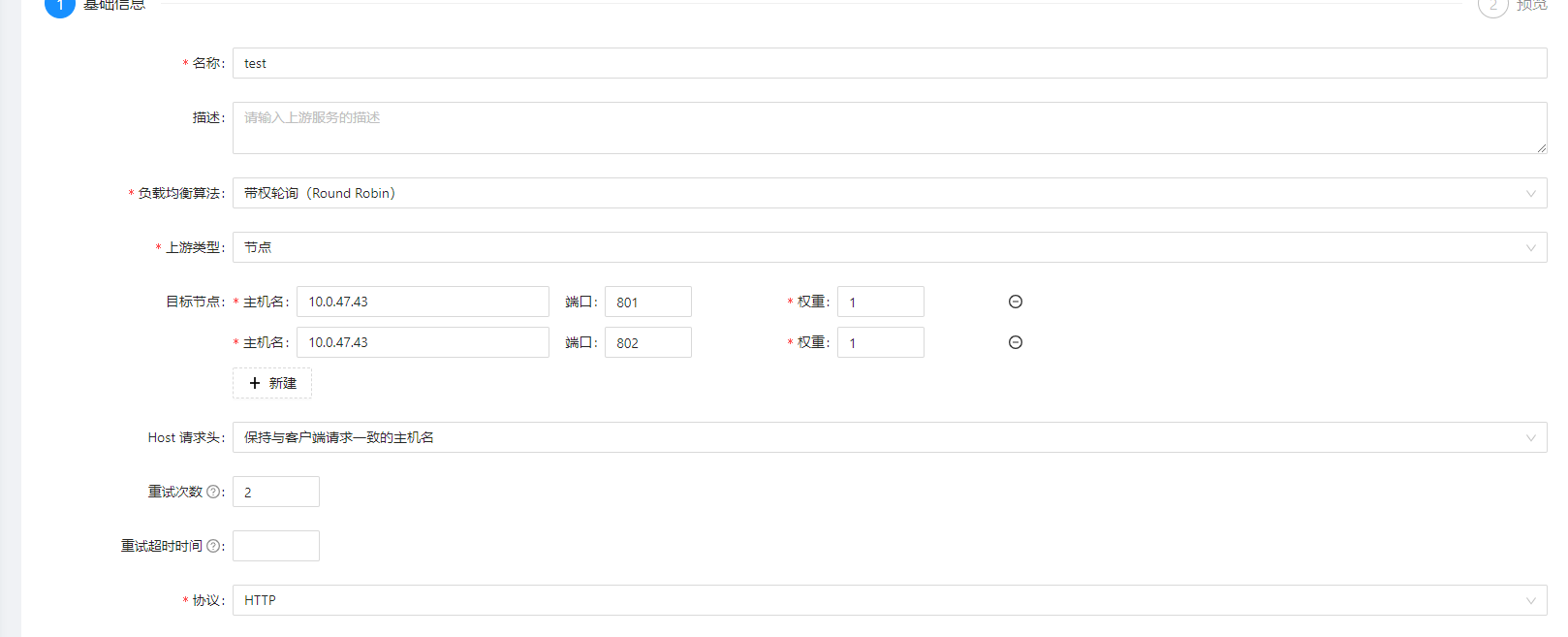
apisix-入门使用篇
随机推荐
SAP Commerce Cloud Product Review 的添加逻辑
If the value of the enum map does not exist, deserialization is not performed
结构化查询语言SQL-关系数据库标准语言
音视频基础
R语言:文本(字符串)处理与正则表达式
[Virtualization ecological platform] Raspberry Pi installation virtualization platform operation process
apisix-入门使用篇
「R」使用ggpolar绘制生存关联网络图
WSL2安装.NET 6
最全phpmyadmin漏洞汇总
Redis - Basics
使用内存映射加快PyTorch数据集的读取
Docker installs canal and mysql for simple testing and achieves cache consistency between redis and mysql
In PLC communication error or timeout or download the prompt solution of the model
mysql 索引使用与优化
7 days to learn Go, Go structure + Go range to learn
Data Persistence Technology - MP
Obsidian设置图床
Power BI----几个常用的分析方法和相适应的视觉对象
多线程学习笔记-2.final关键字和不变性