当前位置:网站首页>[elt.zip] openharmony paper Club - witness file compression system erofs
[elt.zip] openharmony paper Club - witness file compression system erofs
2022-06-25 18:32:00 【ELT. ZIP】
- This article from the
ELT.ZIPThe team ,ELT<=>Elite( elite ),.ZIP In compressed format ,ELT.ZIP That is to compress the elite . - member :
- Sophomore at Shanghai University of engineering and Technology
- Sophomores of Hefei Normal University
- Sophomores at Tsinghua University
- Freshman of Chengdu University of Information Engineering
- Freshmen of Heilongjiang University
- Freshman of South China University of Technology
- We are from
6 A place toClassmate , We areOpenHarmony Growth plan gnawing paper Clubin , AndHuawei 、 Soft power 、 Runhe software 、 Rio d information 、 ShenkaihongWait for the company , Study and ResearchOperating system technology…
List of articles
【 Looking back 】
① 2 month 23 Japan 《 I'm here for a series of tours 》 And Why is Lao Zi —— ++ Interpretation of compression coding from the perspective of overview ++
② 3 month 11 Japan 《 I'm here for a series of tours 》 And I'll show you the scenery —— ++ Multidimensional exploration universal lossless compression ++
③ 3 month 25 Japan 《 I'm here for a series of tours 》 And I witnessed the vicissitudes of life —— ++ Turn over those immortal poems ++
④ 4 month 4 Japan 《 I'm here for a series of tours 》 And I visited a river —— ++ Count the compressed bits of life ++
⑤ 4 month 18 Japan ++【ELT.ZIP】OpenHarmony Paper Club —— One article penetrates the cutting edge of multimedia ++
⑥ 4 month 18 Japan ++【ELT.ZIP】OpenHarmony Paper Club —— You shouldn't miss these little scenery ++
⑦ 4 month 18 Japan ++【ELT.ZIP】OpenHarmony Paper Club —— Analysis of sparse representation of medical images ++
⑧ 4 month 29 Japan ++【ELT.ZIP】OpenHarmony Paper Club —— Computer vision data compression application ++
⑨ 4 month 29 Japan ++【ELT.ZIP】OpenHarmony Paper Club —— Ignite the spark of main cache compression technology ++
⑩ 4 month 29 Japan ++【ELT.ZIP】OpenHarmony Paper Club —— Immediate Conquest 3D Trellis compression coding ++
⑪ 5 month 10 Japan ++【ELT.ZIP】OpenHarmony Paper Club —— Cloud computing data compression scheme ++
⑫ 5 month 10 Japan ++【ELT.ZIP】OpenHarmony Paper Club —— Big data framework performance optimization system ++
⑬ 5 month 10 Japan ++【ELT.ZIP】OpenHarmony Paper Club —— Internet of things swing door trend algorithm ++
⑭ 5 month 22 Japan ++【ELT.ZIP】OpenHarmony Paper Club —— Electronic device software update compression ++
⑮ 5 month 22 Japan ++【ELT.ZIP】OpenHarmony Paper Club —— Artificial intelligence short string compression ++
⑯ 5 month 22 Japan ++【ELT.ZIP】OpenHarmony Paper Club —— Multi tier storage hierarchical data compression ++
⑰ 6 month 3 Japan ++【ELT.ZIP】OpenHarmony Paper Club —— High throughput lossless data compression scheme ++
⑱ 6 month 3 Japan ++【ELT.ZIP】OpenHarmony Paper Club —— Fast random access string compression ++
⑲ 6 month 13 Japan ++【ELT.ZIP】OpenHarmony Paper Club ——gpu Efficient lossless compression of floating point numbers on ++
⑳ 6 month 13 Japan ++【ELT.ZIP】OpenHarmony Paper Club — A deep neural network compression algorithm ++
㉑ 6 month 13 Japan ++【ELT.ZIP】OpenHarmony Paper Club — Hardware accelerated fast lossless compression ++
【 This issue focuses on 】
Uncover Google Apps EROFS The reason for going to AndroidEROFS Why can it shine in the field of file compression systemsThe mystery of the LZ4m How to bring new vitality to the memory compression field
【 technology DNA】

【 Intelligent scene 】
| ********** | ******************** | ******************** | ******************** | ******************** | ******************** | ******************** | ******************** | ******************** | ******************** | ******************** | ******************** | ******************** | ******************** | ******************** | ***************** | ***************** | ******************** |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| scene | Autopilot / AR | Voice signals | Streaming video | GPU Rendering | science 、 Cloud computing | Memory reduction | Scientific application | Medical images | database server | Artificial intelligence image | Text transfer | GAN Media compression | Image compression | File synchronization | Database system | General data | System data reading and writing |
| technology | Point cloud compression | Sparse fast Fourier transform | Lossy video compression | Grid compression | Dynamic selection compression algorithm framework | lossless compression | Hierarchical data compression | Medical image compression | Lossless universal compression | Artificial intelligence image compression | Short string compression | GAN Compressed on-line multi particle distillation | Image compression | File transfer compression | Fast random access string compression | High throughput parallel lossless compression | Enhanced read-only file systems |
| Open source project | Draco / Based on deep learning algorithm /PCL/OctNet | SFFT | AV1 / H.266 code / H.266 decode /VP9 | MeshOpt / Draco | Ares | LZ4 | HCompress | DICOM | Brotli | RAISR | AIMCS | OMGD | OpenJPEG | rsync | FSST | ndzip | EROFS |
introduction
- In a highly information-based modern society ,
A smart phone, Has become an integral part of our lives .

- For the growing
Phubber,A smart phonePerformance is particularly important .

The current problem
Smart phones usually have limited storage space and runtime memory .
1. Low user perceived storage space
- Due to cost constraints , Smart phones are usually resource scarce . meanwhile ,
Android The space occupied by the operating systemIt's also increasing . meanwhile ,Android Storage consumption of applicationsAnd it's growing , therefore , The storage capacity of low-end smartphones available to users is quite small . Besides , Many top applications of smart phones tend to consume a lot of memory , Even on high-end smartphones , alsoOnly a small amount of memory is left for the system startup operation.
2. The design purpose of the system is contrary to the application reality
- Read only file systems are designed to minimize the use of storage . However , Using the existing compression to read only the file system on the smart phone with scarce resources will lead to huge overhead in terms of performance and memory consumption , therefore , In the long term , the nation is in peril .
3. Limitations of the old scheme
· Btrfs
- Btrfs It's a universal file system , Therefore, its internal structure must consider effective data modification ,
Not for compressionAnd actively optimize . Besides ,Compression is not the only measure.decompressionIn processMemory consumption is limited. For devices like smartphones ,performanceandResponse abilityIs an unshakable key indicator . therefore , With the burden of efficient data modification ,Btrfs It's hard to satisfy at the same timeperformanceandCompression efficiencyThe requirements of .
· Squashfs
Fixed size input compression
Existing file systems compress raw data in fixed size blocks , Generate compressed data of variable size .
This will cause great I/O Amplification and computation waste , Even if the number of compressed blocks is very large , The file system must read all related compressed blocks . meanwhile , The process of decompressing useless data can also cause huge CPU waste , This leads to other high-performance disturbances in operation .
Massive memory consumption and data movement .
- When file read request ,Squashfs The metadata will be searched first , Get the number of related compressed blocks . therefore , During decompression Squashfs Need a lot of temporary memory .
New scheme EROFS( Enhanced compressed file system )
- Android be based on Kernel Developed from , So it's been used all the time Linux Standard file system for ext4, but ext4 The storage image structure of is not suitable for mobile phone flash memory .2016 year , Huawei has launched optimized F2FS(Flash-Friendly File System) file system , It replaces the traditional ext4, Improved file reading and writing fluency , However, the system partition where the operating system read-only files are running has not been changed . To solve this problem ,2018 year , Huawei has further launched its own EROFS(Enhanced Read-Only File System), It uses an optimized fixed output size lz4 Compression algorithm , For the first time EMUI9.1, The equipment performance has been greatly improved . And more recently ,Android 13 Primordial also announced to follow up .



- Naturally, ,HarmonyOS And OpenHarmony It also has its shadow in :

characteristic
Use fixed size output compression .
Compress file data into multiple fixed size blocks , To significantly alleviate the read amplification problem , And minimize unnecessary calculations .
Efficient decompression of memory , High performance with little additional memory overhead .
By using the compression algorithm ( Such as LZ4) Characteristics ,EROFS Different memory efficient decompression schemes are designed , To reduce additional memory usage during decompression .
EROFS It also adopts a set of optimization schemes that carefully ensure a guaranteed user experience .
Detailed explanation :
1. Fixed size output compression
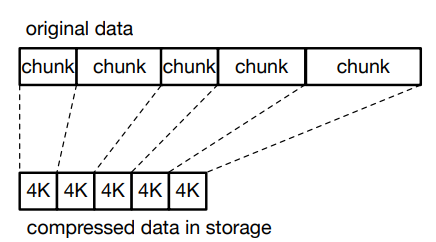
- reason : In order to overcome the read amplification caused by fixed size input compression ,EROFS A different compression method is used : Fixed size output compression
- Implementation method : Fixed size sliding window
- technological process : The compression algorithm will be called many times , Until all file data is compressed .
- for example , about 1MB Sliding window of ,EROFS Each time... Is provided to the compression algorithm 1MB Raw data . Then the algorithm compresses the original data as much as possible , Until all the 1MB All the data is consumed , Or the consumed data can just be generated 4KB Of compressed data .( The minimum size of the requested underlying storage device is 4KB) The remaining raw data is combined with more data , Form another 1MB Raw data , Used for the next call to compress .
- Compression ratio : Because fixed size output compression can compress data as much as possible , Until the output limit is reached , The fixed size input compression can only compress the fixed size data at a time .

- During decompression , Only compressed blocks containing the requested data are read and processed . When a single raw block is requested , Up to two compressed blocks will be read and decompressed .
- Post - sized output compression makes in - place decompression possible , This further reduces EROFS Memory consumption in .
2. cache I/O And local I/O(I/O—— Input / Output )
starting point : Before the actual decompression ,EROFS Need space to store compressed data retrieved from storage . Each compression retrieves only a maximum of two compressed blocks .
Strategy :
- cache I/O( Partially decomposed data block )
- EROFS Manage a special
The index node, ItsPage cachingStorage pressPhysical block ordinal indexThe compression block of . therefore , For cached I/O, EROFS Will be in a special inode Allocate a page to the page cache oflaunch I/O( Input / Output ) request, In this way, the compressed data will beStorage driveGet directly to the assigned page .- Tips:
- Page caching :
Because the speed of reading and writing hard disk is much slower than that of reading and writing memory . To avoid every time you read or write a file , All need to read and write to the hard disk ,Linux The kernel will be in page size (4KB) In units of , Divide the file into multiple data blocks , When a user reads and writes a data block in a file , The kernel first requests a memory page ( This is called page caching ) Cache with data blocks in the file . - inode:
inode Stores some meta information about file system objects , The address of the corresponding file system storage block, etc , got it 1 File inode number , You can go to inode Find out the storage address of the file content data in the metadata .
- In situ I/O( Fully decomposed compressed block )
- Every time you read a file ,
VFS( Virtual file system )In the page cache , Assign pages to the file system , To store file data . For any of these pages that do not contain meaningful data before decompression , It is called a reusable page . For local I/O,EROFS Will use the last reusable page , To initialize the I/O request . - Tips:VFS( Virtual file system ):
Interfaces that allow operating systems to use different file system implementations .
3. decompression
Take a single block as an example

front 5 Block (D0 To D4) And partial blocks D5 Compressed into blocks C0, The remaining blocks are compressed into blocks C1.
Three decompression methods are introduced below :
Vmap decompression
Decompress to get the block D3 and D4 Data in ,EROFS First read the compressed block from the memory C0, And store it in memory . then EROFS The following steps will be followed to decompress .
- Find the data stored in the compressed block (C0) The maximum encoding of the required block in , This is the fifth block in the example (D4).EROFS Just before unzipping 5 Block (D0 To D4), Instead of decompressing all the original data blocks .
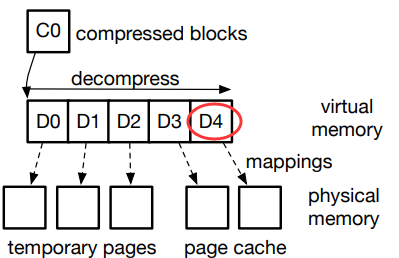
- For each data block that needs to be decomposed , Find storage space to store them . In the legend ,EROFS Allocated 3 individual Temporary physical pages to store D0、D1 and D2. For the two blocks requested D3 and D4, EROFS Reuse in the page cache VFS Two physical pages that have been allocated .

- Because the decompression algorithm needs
Continuous memoryAsDestination for decompression, EROFS adoptvmap InterfaceWill be prepared in the previous stepPhysical pages are mapped to contiguous virtual memory areas.

- If it is local I/O, under these circumstances , Compression block (C0) Stored in
Page cache pagesin ,EROFS You also need to compress the data (C0) Copied to the A temporary pre——CPU page ( The next scenario will introduce ), In this way, the decompressed data will not overwrite the compressed data during the decompression process .

- Finally, the decompression algorithm is called , Extract the data in the compressed block to the continuous storage area . After the compression , All three temporary physical pages and virtual memory areas can be reclaimed , The requested data has been written to the corresponding page cache page .
Existing problems :
Need to dynamically allocate physical memory pages , This increases memory pressure on memory constrained devices .
Use vmap and vunmap The efficiency of each decompression is very low .
There are two optimization schemes for dynamic memory allocation
Per-CPU buffer decompression
EROFS utilize percpu buffer To mitigate that the decompressed data is less than 4 Page problems .

1. A four page memory buffer is pre allocated to each CPU As every CPU buffer , For extraction no more than 4 Decompression of data blocks ,EROFS Decompress the data to per-cpu buffer .

D8 Data in is requested ,C1 Compressed data in Extract directly to per-cpu buffer .
- Then copy the requested data to the page cache page .

D8 The content of memcpy complex Make it to the page cache page .
advantage :
per-CPU The length of the buffer is determined by experience , According to this fixed length, data is extracted for caching ; meanwhile ,per-CPU Buffers can be reused in different decompression processes , To sum up, it can effectively eliminate
vmapDynamic memory allocation problem .pre-cpu Buffer decompression is a cost-effective trade-off , It relieves vmap Problems in decompression , Additional memory copies are also introduced .
Scroll to extract
principle :
- EROFS Allocated a large virtual memory area as well as for each CPU Distribute 16 A physical page . Before each compression ,EROFS Will use this 16 Physics pages , Populate with the physical pages of the page cache VM ( fictitious ) Area .

- Tips:
- EROFS Use LZ4 As a compression algorithm , You need to look back and decompress it before it exceeds 64KB The data of . therefore , For an extract more than 16 Compression of pages ,EROFS Maps can be reused 16 Physical pages of virtual pages ( namely 64 kb).
Roll
- In the picture , Used to store D0 To D15 The virtual address of the block is determined by 16 Physical pages support .
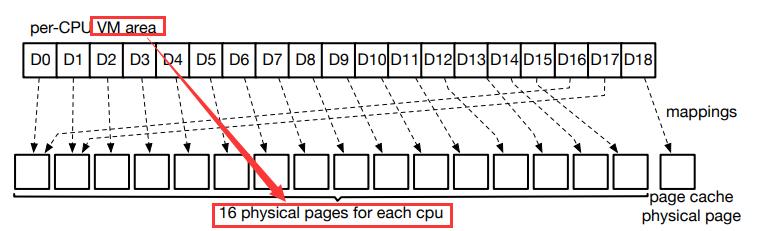
- because D16 Each virtual address in is associated with D0 The distance between the corresponding addresses in is 16 A physical page , Start a new round of rolling .

therefore D16 Virtual pages of can be created by and D0 The same physical page to support ,D17 adopt D1 The physical pages used are supported in the same way .
D18 Is requested by the file being read , Physical pages using page cache .

Sum up , By using this scrolling decompression 16 A physical page is enough to handle any decompression situation . up to now , We have a preliminary understanding of :EROFS choose 4k The reason for the fixed output size is —— 4k It is the smallest unit for page management and data storage , Can effectively avoid I/O A larger version of ; choose lz4 As a compression algorithm, I like its extremely fast decompression speed and good compression ratio ; Only the file data is in EROFS Will be compressed ,inode Metadata such as catalog entries remains the same .
The file of the operating system contains the file data itself , There are also many permissions and attributes attached . Permissions and attributes are placed in inode, The actual data is placed in the data block . without doubt , The data block records the actual contents of the file . and inode In addition to the extended attributes of the record file , The number of the corresponding data block is also recorded , And one file will occupy one inode. The super block records the overall information of the entire file system , Include inode And the total number of data blocks 、 Usage quantity 、 The remaining amount, file system format and related information, etc .
Structural layout
- Similar to many file systems ,EROFS There is also a
Super blockAt the front end of the whole structure . After that , Metadata and actual data can be stored in order or in mixed form .

As shown in the figure , Each block behind the super block corresponds to a file . Expand it , You can see that the beginning stores inode, Followed by the xattrs Extended attribute and block index , Last , An encoded block representing compressed or uncompressed file data is stored at the end of each file . The block index is used to quickly locate the corresponding encoded block of the read request , It is an inclusion of 8 An array of byte length entries , Each entry corresponds to a data block before compression , It also indicates whether the data block is a header block ( head? ), To start a new encoding block . If it's a header , The address of the encoding block will also be stored ( blkaddr? )、 Offset of the first byte in the new encoding block ( offset? )、 Whether the encoding block has been compressed ( cmpr? ) And whether this block can be decompressed in place ( dip? ); If it wasn't for the header , You must try to determine a header block before uncompressed blocks , The difference in the number of uncompressed blocks and header blocks is recorded in dist in .
The overall structural layout is now almost ready , When we need to use these data ,EROFS How to operate it ?
First , Read requests for uncompressed data blocks ,EROFS The entry of the block index will be obtained based on the requested block number . secondly , If it is for the head block ,EROFS Will be taken from blkaddr Decompress the data of the encoding block at , If the offset is non-zero , May need to be from blkaddr The last code block stored before begins to decompress . in addition , For non header blocks ,EROFS Based on stored dist Value reverses the position of the corresponding header block , From the beginning blkaddr Start decompression at , Until the data of the requested block is completely decompressed . Some data blocks are still large after compression , Therefore, most of them are not compressed , Instead, it is stored directly in the form of coding blocks , Avoid excessive time and space costs . Above situation , It is embodied in the block index cmpr The field value is set to N(false) The entry of .
Technical optimization scheme
1. Index memory optimization
EROFS Hundreds of pages of raw data can be compressed into only one compressed block , But in this case , Hundreds of pointers will be required to track the pages where the original data should be stored , It may consume a lot of memory . So ,EROFS Will try to use reusable pages to store this information . If there are more than one VFS Assigned pages can be reused , Select the last page to store compressed data , Pointers to the remaining pages are moved to the stack .
2. Scheduling optimization
In image Btrfs In such a file system , When compressed data is read into memory , Will wake up a dedicated thread to decompress the data . After the decompression , Used to implement I/O The reader thread will be awakened , To get the unzipped data from the page cache . therefore , This scheduling overhead between each other cannot be ignored . therefore ,EROFS The strategy of using reader threads throughout the process is adopted .
3. Queue decompression algorithm
You can make multiple requests to decompress at the same time . When a thread A The requested data is being processed by the thread B When decompressing , Threads A You don't need to decompress it again , You can reuse threads directly from the page cache B Extracted data , So as to realize cooperative reuse of decompressed data , Prevent single data from being decompressed multiple times .
4. Mirror patch
Even though EROFS Compressed is a read-only partition , However, the data may still change during system update and other operations . Even if only a few bits in the file data are simply modified , A large number of other relevant scattered data may also need to be modified , This causes the entire partition to recompress .EROFS Provides an image patch that can be placed at the end of the image , Exempt the modification of compressed read-only partition , Instead, apply a patch to update and patch the original data after decompression .
Scene performance
1. Compression ratio and memory usage
- The use sizes are 953.67MB、202.1MB Of enwik9 And silesia.tar Test the compression ratio as a data set , The results are as follows . You can see , And 4K Size input Squashfs comparison ,4K Size output EROFS The compression ratio is better 10% and 9%.

- The following figure shows understanding compression enwik9 The amount of memory used by :

2. Throughput and storage space

- The picture above depicts EROFS and ext4 Performance of throughput and storage space saving under different conditions . Under normal circumstances ,ext4 The throughput of is stable ;EROFS The performance is to save space while increasing , The overall level is gradually rising , When the amount of space saved is high enough , Achieved very good throughput . When the amount of space saved is low ,EROFS The performance for random reads is similar to ext4, Compared with the performance of sequential reading ext4 Poor .
3. Application start time
- The R & D personnel have tested and evaluated the startup time of several applications , It turns out that , And ext4 comparison ,EROFS The average number of low-end mobile phones app Reduced startup time 5%, High end phones are shorter 2.3%. Take one of the cameras app For example :
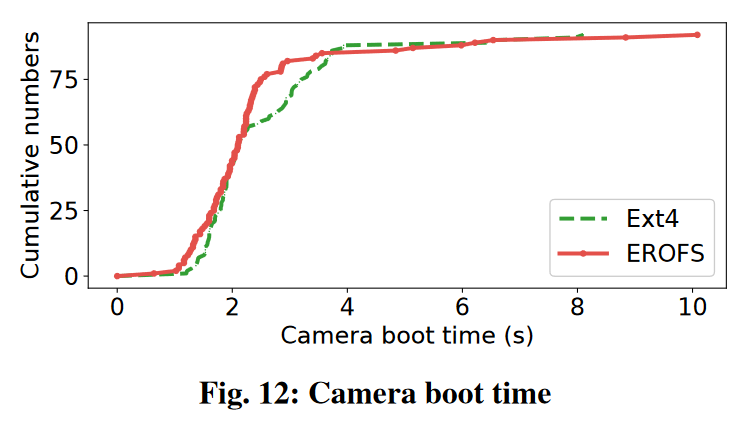
stay 90% Under the above startup status ,EROFS All better than ext4, Very long startup times occur only occasionally .
reference
Reference meetings
[1] USENIX
[2] IEEE Xplore, delivering full text access to the world’s highest quality technical literature in engi
边栏推荐
- Iet attends the 2022 World Science and technology community development and Governance Forum and offers suggestions for building an international science and technology community
- 2017 reading (word memory)
- Training of long and difficult sentences in postgraduate entrance examination day92
- Trample hole record -- a series of coincidences caused by thread pool rejection policy
- Redis trend - NVM memory
- Huawei cloud SRE deterministic operation and maintenance special issue (the first issue)
- [in depth understanding of tcapulusdb technology] tcapulusdb operation and maintenance
- Dell R530内置热备盘状态变化说明
- Under what circumstances do you need to manually write the @bean to the container to complete the implementation class
- GNU nano
猜你喜欢

【路径规划】如何给路径增加运动对象
![[in depth understanding of tcapulusdb technology] business guide for creating doc acceptance](/img/e5/9c902f5d6aaeb7113e82d2c1084005.png)
[in depth understanding of tcapulusdb technology] business guide for creating doc acceptance
![存在重复元素III[利用排序后的有序性进行剪枝]](/img/26/5c3632a64945ea3409f8240ef5b18a.png)
存在重复元素III[利用排序后的有序性进行剪枝]
158_模型_Power BI 使用 DAX + SVG 打通制作商业图表几乎所有可能
Basic operations and basic data types of MySQL database
158_ Model_ Power Bi uses DAX + SVG to open up almost all possibilities for making business charts

使用宝塔来进行MQTT服务器搭建

Anaconda download Tsinghua source

Matlab中图形对象属性gca使用

視覺SLAM十四講 第9講 卡爾曼濾波
随机推荐
Ruffian Heng embedded semimonthly issue 57
C# asp,net core框架传值方式和session使用
两轮市场红海,利尔达芯智行如何乘风破浪?
Training of long and difficult sentences in postgraduate entrance examination day85
Install spark + run Scala related projects with commands + crontab scheduled execution
Kwai 616 war report was launched, and the essence was thrown away for the second time to lead the new wave. Fast brand jumped to the top 3 of the hot list
04 program counter (PC register)
connect to address IP: No route to host
[deeply understand tcapulusdb technology] transaction execution of document acceptance
【深入理解TcaplusDB技术】 Tmonitor模块架构
Command records of common data types for redis cli operations
【深入理解TcaplusDB技术】单据受理之创建业务指南
General message publishing and subscription in observer mode
[in depth understanding of tcapulusdb technology] tcapulusdb business data backup
What is generics and the use of generics in collections [easy to understand]
2017 reading (word memory)
Good news | Haitai Fangyuan has passed the cmmi-3 qualification certification, and its R & D capability has been internationally recognized
connect to address IP: No route to host
Interrupt operation: abortcontroller learning notes
[in depth understanding of tcapulusdb technology] tcapulusdb construction data