当前位置:网站首页>Oracle 将数据导出到CSV(Excel)文件的方法
Oracle 将数据导出到CSV(Excel)文件的方法
2022-06-11 12:09:00 【三岁Funny】
Oracle 快速将数据导出到CSV(Excel)文件的方法及性能
1,我们工作中有需要将线上数据导出到excel给客户分析/查看的情况,如下是方法介绍情况:
工作中有需要将线上数据导出到excel给客户分析/查看的情况,如下是方法介绍情况:
| 方法 | 1分钟导出的数据量 ---- 适用于 |
|---|---|
| utl_file读写文件包 | 300万 大量导出时 |
| plsql developer->export query result | 10万 小量导出时 |
| – | – |
| excel连接数据库 | 1万 |
| spool 循环打印 | 5000 |
–excel 最大行数1048576
方案一、利用SQL_TO_CSV导出.csv文件. --.csv逗号分隔值格式文件,可用excel工具打开,显示格式和excel一样…
1. 创建SQL_TO_CSV存储过程如下:
CREATE OR REPLACE PROCEDURE SQL_TO_CSV
(
P_QUERY IN VARCHAR2, -- PLSQL文
P_DIR IN VARCHAR2, -- 导出的文件放置目录
P_FILENAME IN VARCHAR2 -- CSV名
)
IS
L_OUTPUT UTL_FILE.FILE_TYPE;
L_THECURSOR INTEGER DEFAULT DBMS_SQL.OPEN_CURSOR;
L_COLUMNVALUE VARCHAR2(4000);
L_STATUS INTEGER;
L_COLCNT NUMBER := 0;
L_SEPARATOR VARCHAR2(1000);
L_DESCTBL DBMS_SQL.DESC_TAB;
P_MAX_LINESIZE NUMBER := 32000;
BEGIN
--OPEN FILE
L_OUTPUT := UTL_FILE.FOPEN(P_DIR, P_FILENAME, 'W', P_MAX_LINESIZE);
--DEFINE DATE FORMAT
EXECUTE IMMEDIATE 'ALTER SESSION SET NLS_DATE_FORMAT=''YYYY-MM-DD HH24:MI:SS''';
--OPEN CURSOR
DBMS_SQL.PARSE(L_THECURSOR, P_QUERY, DBMS_SQL.NATIVE);
DBMS_SQL.DESCRIBE_COLUMNS(L_THECURSOR, L_COLCNT, L_DESCTBL);
--DUMP TABLE COLUMN NAME
FOR I IN 1 .. L_COLCNT LOOP
UTL_FILE.PUT(L_OUTPUT,L_SEPARATOR || '"' || L_DESCTBL(I).COL_NAME || '"'); --输出表字段
DBMS_SQL.DEFINE_COLUMN(L_THECURSOR, I, L_COLUMNVALUE, 4000);
L_SEPARATOR := ',';
END LOOP;
UTL_FILE.NEW_LINE(L_OUTPUT); --输出表字段
--EXECUTE THE QUERY STATEMENT
L_STATUS := DBMS_SQL.EXECUTE(L_THECURSOR);
--DUMP TABLE COLUMN VALUE
WHILE (DBMS_SQL.FETCH_ROWS(L_THECURSOR) > 0) LOOP
L_SEPARATOR := '';
FOR I IN 1 .. L_COLCNT LOOP
DBMS_SQL.COLUMN_VALUE(L_THECURSOR, I, L_COLUMNVALUE);
UTL_FILE.PUT(L_OUTPUT,
L_SEPARATOR || '"' ||
TRIM(BOTH ' ' FROM REPLACE(L_COLUMNVALUE, '"', '""')) || '"');
L_SEPARATOR := ',';
END LOOP;
UTL_FILE.NEW_LINE(L_OUTPUT);
END LOOP;
--CLOSE CURSOR
DBMS_SQL.CLOSE_CURSOR(L_THECURSOR);
--CLOSE FILE
UTL_FILE.FCLOSE(L_OUTPUT);
EXCEPTION
WHEN OTHERS THEN
RAISE;
END;
注:输出字段哪个地方如果是双引号,如下图: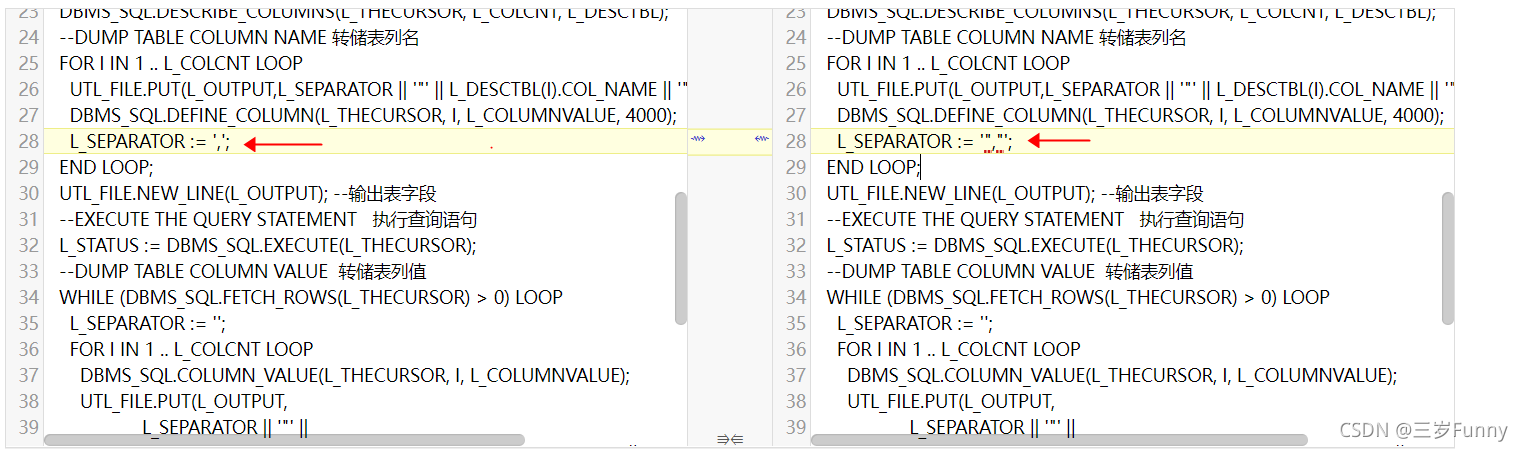
导出来的文件列名会全部在第一列:如下:
2、创建 directory目录
create or replace directory OUT_PATH as '/expdp_dir';
3、拼接出导出的语句
SELECT 'EXEC sql_to_csv(''select * from ' ||T.TABLE_NAME ||''',''OUT_PATH''' || ',''ODS_MDS.' || T.TABLE_NAME ||'.csv'');' FROM user_TABLES T where t.TABLE_NAME='表名'
4、执行导出csv的语句
begin
EXEC sql_to_csv('select * from A','OUT_PATH','ODS_MDS.A.csv');
end
注解:存储过程是通用的,使用者只需复制代码,然后执行即可,在调用存储时传相应的参数即可。
注释:我用的oracle版本是11g的,在执行第四步时报错,如下:
最后改了下调用存储的语句,如下:
begin
sql_to_csv('select * from A','OUT_PATH','ODS_MDS.A.csv');
end
现在刚才那个报错就没了,是另外一个,如图:

就错误判断,是无法操作文件之类的异常。最后原因:创建的目录没有读写的权限。所以无法进行文件操作,下面需要授权。
--查看目录
select * from dba_directories a ;
--给目录授读写权限(可登录管理员system操作)
grant read,write on directory OUT_PATH(目录名) to test(用户名);
如果是新建的用户,记得授dba权限
--创建用户
create user test(用户名) identified by test1(密码) ;
--给用户授权
grant dba to test;
最后就应该是没问题啦!
方案二、plsql developer
使用oracle的sql developer导出(这种方法有人验证过,比上面的方法大概快一倍,但是操作简单)
(1)在数据库中找到想要导出的表,右键选择导出。去掉勾选的导出DDL,把格式改成csv,选择相应的编码方式,点击下一步:

(2)可以在此处添加where子句
方案三、excel连接数据库导出
(步骤:打开excel->数据->导入数据->第一步选择数据源->ODBC DSN->根据情况输入连接信息–>选表字段等)

方案四、spool 循环打印
(1)新建spool.sql文件
set colsep ,
set feedback off
set heading off
set trimout on
spool D:\DBoracle\lfc.csv
select '"' || user_name || '","' || user_age || '","' || user_card || '","' || user_sex || '","' || user_addres || '","' || user_tel || '"' from lfc_xinxi_tbl;
spool off
exit
(2)sqlplus命令行调用:
sqlplus -s 用户名/密码@数据库名 @spool.sql
参数说明:
set colsep' '; //-域输出分隔符
set newp none //设置查询出来的数据分多少页显示,如果需要连续的数据,中间不要出现空行就把newp设置为none,这样输出的数据行都是连续的,中间没有空行之类的
set echo off; //显示start启动的脚本中的每个sql命令,缺省为on
set echo on //设置运行命令是是否显示语句
set feedback on; //设置显示“已选择XX行”
set feedback off; //回显本次sql命令处理的记录条数,缺省为on即去掉最后的 "已经选择10000行"
set heading off; //输出域标题,缺省为on 设置为off就去掉了select结果的字段名,只显示数据
set pagesize 0; //输出每页行数,缺省为24,为了避免分页,可设定为0。
set linesize 80; //输出一行字符个数,缺省为80
set numwidth 12; //输出number类型域长度,缺省为10
set termout off; //显示脚本中的命令的执行结果,缺省为on
set trimout on; //去除标准输出每行的拖尾空格,缺省为off
set trimspool on; //去除重定向(spool)输出每行的拖尾空格,缺省为off
set serveroutput on; //设置允许显示输出类似dbms_output
set timing on; //设置显示“已用时间:XXXX”
set autotrace on-; //设置允许对执行的sql进行分析
方案五、查询结果处导出相应的格式文件

边栏推荐
- Android 11+ configuring sqlserver2014+
- mysql 导入宝塔中数据库data为0000-00-00,enum为null出错
- .net core 抛异常对性能影响的求证之路
- UnicodeDecodeError: ‘utf-8‘ codec can‘t decode byte 0xc5 in position 13: invalid continuation byte
- Android 11+ 配置SqlServer2014+
- 纯数据业务的机器打电话进来时回落到了2G/3G
- flink Window Join、Interval Join、Window CoGroup (两流匹配 指定key联结,开窗口进行窗口操作)
- Acwing50+acwing51 weeks +acwing3493 Maximum sum (open)
- Wireshark packet capturing and debugging RTSP
- 7. CAS
猜你喜欢

12. AQS of abstractqueuedsynchronizer
How does Wireshark modify the display format of packet capturing time and date?

yapi安装

Installation and use of saltstack

General O & M structure diagram
JVM优化

leetcode-59. Spiral matrix II JS

Splunk 最佳实践-减轻captain 负担

Shut down THP of Splunk health check

2、CompletableFuture
随机推荐
(推荐)splunk 多少数量search head 才合适
Linux忘记MySQL密码后修改密码
Yapi installation
splunk 证书过期 使KV-store不能启动
Solving the problem of data garbled in sqlserver connection database (Chinese table)
[digital signal processing] correlation function (property of correlation function | maximum value of correlation function | maximum value of autocorrelation function | maximum value of cross correlat
Flink window table valued function
纯数据业务的机器打电话进来时回落到了2G/3G
Wechat web developers, how to learn web development
ftp服务器:serv-u 的下载及使用
Linux changes the MySQL password after forgetting it
ObjectInputStream读取文件对象ObjectOutputStream写入文件对象
反射真的很耗时吗,反射 10 万次,耗时多久。
How does data age in Splunk?
Troubleshoot Splunk kvstore "starting"
Let you understand selection sorting (C language)
Flink multi stream conversion (side output stream shunting, union, connect) real-time reconciliation of APP payment operations and third-party payment operations
Format of Jerrys at protocol package [chapter]
(solve) the kV store down problem of Splunk
线程五种状态(线程生命周期)