当前位置:网站首页>多表联查--07--- Hash join
多表联查--07--- Hash join
2022-06-27 06:50:00 【高高for 循环】
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
Hash join
1.简介
官网介绍:Hash join in MySQL 8
mysql8.0 开始引入 Hash join

2.什么是hash join
- 所谓的hash join 定义:使用hash 表来进行多个表中行数据的匹配操作的join 实现。
- 通常情况下,hash join 效率比nested loop join 快(当join 中的某一张表数据量小,可以完全缓存到内存中时,hash join 效率是最好的)。
3.Hash Join 处理过程
下面我们使用一个例子来进行说明。
SELECT
given_name, country_name
FROM
persons JOIN countries ON persons.country_id = countries.country_id;
- country 国家表 ,作为一个基础元素表,数据量相对较小
- persons 人员信息表, 数据量相对较大
4.Hash join过程
HashJoin一般包括两个过程,hash 表构建过程 和 基于hash 表的探测比较部分。
- 创建hash表的build过程
- 探测hash表的probe过程
5.怎么使用hash join
- 默认情况下,hash join 是开启的。
- 可以在explain 中加入 “FORMAT = tree” 查看某一个sql
mysql> EXPLAIN FORMAT=tree
-> SELECT
-> given_name, country_name
-> FROM
-> persons JOIN countries ON persons.country_id = countries.country_id;
+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| EXPLAIN |
+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| -> Inner hash join (countries.country_id = persons.country_id) (cost=0.70 rows=1)
-> Table scan on countries (cost=0.35 rows=1)
-> Hash
-> Table scan on persons (cost=0.35 rows=1)
|
+---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
1 row in set (0.01 sec)
通常情况下,如果join 使用了 等值条件 (一个或多个)、并且,没有 索引可用,就会使用hash join 。(也就是说,如果存在索引,则mysql 还是会优先使用 所有查询)
我们也可以使用通过命令来关闭 hash join :
mysql> SET optimizer_switch="hash_join=off";
Query OK, 0 rows affected (0.00 sec)
mysql> EXPLAIN FORMAT=tree
-> SELECT
-> given_name, country_name
-> FROM
-> persons JOIN countries ON persons.country_id = countries.country_id;
+----------------------------------------+
| EXPLAIN |
+----------------------------------------+
|
|
+----------------------------------------+
1 row in set (0.00 sec)
Hash join 原理解析
1.hash表构建 (build) 过程
选择数据量较小的表 来构建hash 表
- 在构建hash 表时,mysql 将join 中的某一张数据表的数据 缓存到 此hash 表中。通常情况下,选择数据量较小的表 来构建hash 表(则需要缓存的数据量相对较小)。
- hash 表使用 join 使用的 join 中的此表使用的条件作为 hash key.
- 例如上面例子中, country 表作为一个 基础元素表,数据量相对较小,则选择缓存 country表数据。另外,join 条件为persons.country_id = countries.country_id ,则使用 countries表的country_id 字段值作为 hash key。
- 当country 表中的所有相关的数据行都缓存起来是,构建过程结束。

2.hash 表探测(probe)过程
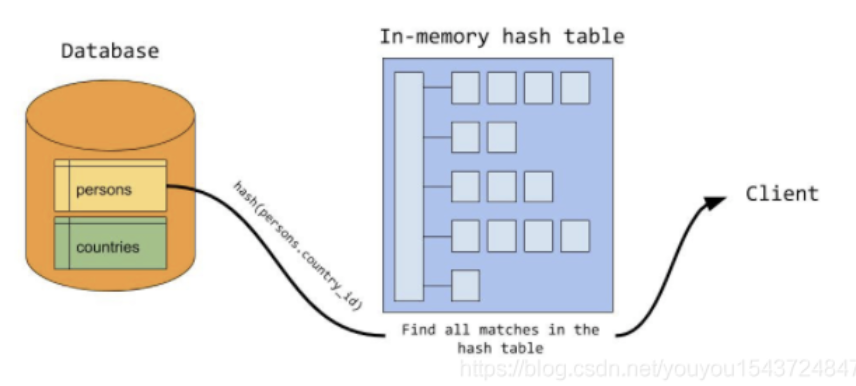
- 在探测阶段, 数据库 从需要探测的数据表读取数据行(这个例子中是 person 表)。
- 对于读取到的每一行数据, mysql 会使用 行中的 country_id 值 查询hash 表,每匹配到一行数据,则找到一个 合理的join 结果数据。
- 总体来说,mysql 只需要对每一张表,只扫描一次。对于探测表扫描时,每扫描到一条数据,然后使用常量时间基于hash 表来进 数据结果匹配。
3.数据表拆分
- 当 某一张数据表( 作为hash 表源数据的表)可以缓存到内存中时,hash join 的效率很快。
- 那 hash join 可使用的hash 缓存有多大呢?
- 这是 通过 系统 变量 join_buffer_size 控制的。该变量可以随时修改,立即生效。
- 那么如果作为join 的数据表数据量 都很大,无法完成缓存,那应该怎么处理呢?
- 如果在构建hash 表的过程中,如果达到 join_buffer_size 值,则mysql 将剩下的数据写入到磁盘中的文件块中。
- 在写文件块的时候,mysql 会尽量 控制每个块的大小,使得后续这个块可以刚好加载到 join_buffer_size 大小的hash 缓存中。(但是 mysql 也有一个最大的限制,对于每个 join ,最大128 个 磁盘数据块)。
如果作为join 的数据表数据量 都很大,无法完成缓存,则要对小表也要进行数据拆分
- 当数据写入到磁盘文件块中后,那我怎么知道哪一行数据被写入到那个文件块了呢? 这里有一个新的hash 函数,用于定位数据块。
- 那为什么会使用一个新的hash 函数呢?这个原因后续会说。

4.拆分-----数据探测阶段
- 在数据探测阶段,mysql 进行数据匹配的过程和没有写 磁盘块文件的过程是一样的(就像所有的数据都写入了内存hash 表一样):在探测表中,每扫描到一行数据,就到 内存中的hash 表中进行 匹配,找到符合条件的 数据。
- 但是不同的是,如果进行了磁盘块写的操作,则在 探测表中每扫描到一行数据A , 在 hash 表进行匹配操作后, 还需要写入到磁盘文件块中(因为对于数据行A ,也有可能匹配到 之前写入到磁盘块中的数据)。
- 需要注意的时,将探测表写入到 磁盘文件块时,将数据行定位到 特定数据块的 hash 函数 和 将hash 表源表数据写入到数据块的算法是一致的。 所以 匹配的数据 都会写入到 同一对 数据块中。
例如,country 表数据量很大,只能将 以A - D 开头的国家写入到 内存 hash 表中。另外,将 剩下的国家数据 写入到磁盘文件块中。
如果国家 HXX 写入到 hash 表块 HA 中。在扫描Person 表时,如果某一个人员的国家也是HXX ,则同理,会将 该调数据写入到 探测表HXX 块号中。

在这里,有两个地方需要说明:
- 在当初写 磁盘文件块时,就需要注意 每一个文件块大小不要超过 join buffer size, 所有,某一个 hash磁盘文件块可以正好加载到 hash join 表中;
- 为什么使用不同的hash 算法来将不同的数据行分配到不同的 磁盘数据块中? 如果算法相同,则将一个块的数据加载到 join hash表中,则大量的数据都会在hash 表的同一行,大量的冲突数据。
边栏推荐
- 【编译原理】山东大学编译原理复习提纲
- Cloud-Native Database Systems at Alibaba: Opportunities and Challenges
- pytorch Default process group is not initialized
- 在线文本数字识别列表求和工具
- AHB2APB桥接器设计(2)——同步桥设计的介绍
- Cloud-Native Database Systems at Alibaba: Opportunities and Challenges
- Bean拷贝详解
- The song of cactus -- throwing stones to ask the way (1)
- 技术人员创业一年心得
- guava 定时任务
猜你喜欢

yarn create vite 报错 ‘D:\Program‘ 不是内部或外部命令,也不是可运行的程序 或批处理文件

Park and unpark in unsafe
On gpu: historical development and structure
Memory barrier store buffer, invalid queue
Winow10 installation nexus nexus-3.20.1-01

The interviewer of a large front-line factory asked: do you really understand e-commerce order development?

win10远程连接云服务器

From 5 seconds to 1 second, the system flies
![[graduation season] graduation is the new beginning of your life journey. Are you ready](/img/4e/aa763455da974d9576a31568fc6625.jpg)
[graduation season] graduation is the new beginning of your life journey. Are you ready
winow10安装Nexus nexus-3.20.1-01
随机推荐
How to write controller layer code gracefully?
How to implement redis cache of highly paid programmers & interview questions series 116? How do I find a hot key? What are the possible problems with caching?
AHB2APB桥接器设计(2)——同步桥设计的介绍
winow10安装Nexus nexus-3.20.1-01
Interviewer: you use Lombok every day. What is its principle? I can't answer
Tidb basic functions
Get the query parameter in the address URL specify the parameter method
hutool对称加密
仙人掌之歌——投石问路(1)
Maxcompute SQL 的查询结果条数受限1W
NoViableAltException([email protected][2389:1: columnNameTypeOrConstraint : ( ( tableConstraint ) | ( columnNameT
Write an example of goroutine and practice Chan at the same time
请问网页按钮怎么绑定sql语句呀
将通讯录功能设置为数据库维护,增加用户名和密码
pytorch Default process group is not initialized
Overview of database schema in tidb
【软件工程】山东大学软件工程复习提纲
sql sever列名或所提供值的数目与表定义不匹配
Rust Async: smol源码分析-Executor篇
HTAP Quick Start Guide