当前位置:网站首页>Using skills and design scheme of redis cache (classic collection version)
Using skills and design scheme of redis cache (classic collection version)
2022-07-24 21:12:00 【Dragon back ride Shi】

Catalog
1、 Benefit and cost analysis of caching
7、 hotspot key Reconstruction optimization
Preface
Cache can effectively speed up the application's reading and writing speed , At the same time, it can reduce the back-end load , It is very important for the development of daily applications . The following will introduce the use skills and design scheme of cache , It includes the following : Benefit and cost analysis of caching 、 Selection and usage scenario of cache update strategy 、 Cache granularity control method 、 Penetration problem optimization 、 Optimization of bottomless problems 、 Avalanche optimization 、 hotspot key Reconstruction optimization .
1、 Benefit and cost analysis of caching
The left side of the figure below shows the architecture of the storage layer directly invoked by the client , On the right is a typical cache layer + Storage tier architecture .

Let's analyze the benefits and costs of adding cache .
earnings :
① Speed up reading and writing : Because caching is usually full memory , However, the read-write performance of the storage layer is usually not strong enough ( for example MySQL), Through the use of cache can effectively speed up the read and write , Optimize the user experience .
② Reduce back-end load : Help the backend reduce access and complex computing ( For example, it's very complicated SQL sentence ), It greatly reduces the load on the back end .
cost :
① Data inconsistency : There is a certain time window inconsistency between the data of cache layer and storage layer , The time window is related to the update strategy .
② Code maintenance costs : After adding the cache , You need to deal with both the cache layer and the storage layer logic , It increases the cost for developers to maintain the code .
③ O & M costs : With Redis Cluster For example , After joining, the cost of operation and maintenance has been increased .
Cache usage scenarios basically include the following two types :
① Expensive and complex calculation : With MySQL As an example , Some complicated operation or calculation ( For example, a large number of join table operations 、 Some group calculations ), Without caching , Not only can't meet the high concurrency , At the same time, I will give MySQL A huge burden .
② Speed up request response : Even if querying a single piece of back-end data is fast enough ( for example select*from table where id=), You can still use caching , With Redis As an example , It can read and write tens of thousands of times per second , And the batch operation provided can optimize the whole IO Chain response time .
2、 Cache update strategy
The data in the cache will be inconsistent with the real data in the data source for a period of time , Some policies need to be used to update , Several main cache update strategies are introduced below .
①LRU/LFU/FIFO Algorithm culling : The culling algorithm is usually used when the cache usage exceeds the preset maximum , How to eliminate the existing data . for example Redis Use maxmemory-policy This configuration is used as the culling strategy for data after the maximum memory .
② Time out culling : By setting the expiration time for cached data , Let it automatically delete... After the expiration time , for example Redis Provided expire command . If the business can tolerate a period of time , Cache layer data is inconsistent with storage layer data , Then you can set the expiration time for it . After the data expires , Then get data from real data sources , Put it back in the cache and set the expiration time . For example, the description of a video , Can tolerate data inconsistency in a few minutes , But the business involved in trading , The consequences are predictable .
③ Active update : The application side has high requirements for data consistency , After the real data is updated , Update cached data now . For example, you can use the message system or other ways to notify the cache of updates .
Comparison of three common update strategies :
There are two suggestions :
① For low consistency business, it is recommended to configure the maximum memory and elimination strategy .
② High consistency services can use a combination of timeout culling and active updating , In this way, even if there is a problem with the active update , It can also ensure that the dirty data will be deleted after the data expiration time .
3、 Cache granularity control
Cache granularity is a problem that is easily ignored , If not used properly , It may cause a lot of waste of useless space , The waste of network bandwidth , Poor code versatility and so on , Need to synthesize data commonality 、 Space occupancy ratio 、 There are three choices of code maintainability .
Cache is commonly used , Cache layer selection Redis, Storage layer selection MySQL.

4、 Penetration optimization
Cache penetration refers to querying a data that doesn't exist at all , Neither the cache tier nor the storage tier will hit , Usually for the sake of fault tolerance , If no data can be found from the storage layer, it will not be written to the cache layer .
Generally, the total number of calls can be counted separately in the program 、 Cache layer hits 、 Number of storage layer hits , If a large number of storage layer null hits are found , Maybe there is a cache penetration problem . There are two basic reasons for cache penetration . First of all , There is a problem with your own business code or data , second , Some malicious attacks 、 Reptiles and so on cause a lot of empty hits . Now let's take a look at how to solve the cache penetration problem .
① Caching empty objects : As shown below , When the first 2 After a storage tier miss , Still leave empty objects in the cache layer , Then accessing this data will get from the cache , This protects the back-end data source .

There are two problems with caching empty objects : First of all , Null values are cached , It means that there are more keys in the cache layer , Need more memory space ( If it's an attack , The problem is more serious ), The more effective way is to set a shorter expiration time for this kind of data , Let it automatically remove . second , The data of cache layer and storage layer will be inconsistent for a period of time , It may have some impact on the business . For example, the expiration time is set to 5 minute , If the storage layer adds this data at this time , Then there will be inconsistencies between the cache layer and the storage layer data in this period of time , At this time, you can use the message system or other ways to clear the empty objects in the cache layer .
② Boom filter intercept ( When I have time, I will write a separate introduction to bron filter )
As shown in the figure below , Before accessing the cache layer and storage layer , There will be key Save in advance with a bloom filter , Do the first level intercept . for example : A recommendation system has 4 Billion users id, Every hour, the algorithm engineer will calculate the recommended data according to each user's previous historical behavior and put it into the storage layer , But the latest users have no historical behavior , There will be cache penetration behavior , For this reason, users of all recommended data can be made into Bloom filters . If the bloom filter thinks that the user id non-existent , Then there is no access to the storage tier , It protects the storage layer to a certain extent .

Comparison between caching empty objects and bloom filter schemes 
another : Brief description of Bloom filter :
If you want to determine whether an element is in a set , The general idea is to save all the elements in the collection , And then through comparison to determine . Linked list 、 Trees 、 Hash table ( Also called hash table ,Hash table) And so on, the data structure is this way of thinking . But as the number of elements in the collection increases , We need more and more storage space . At the same time, the retrieval speed is getting slower and slower .
Bloom Filter It is a random data structure with high spatial efficiency ,Bloom filter It's right bit-map An extension of , Its principle is :
When an element is added to a collection , adopt K individual Hash Function maps this element to a bit array (Bit array) Medium K A little bit , Set them as 1. Search time , We just need to see if these points are all 1 Just ( about ) Know if it's in the collection :
If any of these points 0, The retrieved element must not be in ; If it's all 1, Then the retrieved element is likely to be in .
5、 Bottomless optimization
In order to meet the business needs, a large number of new cache nodes may be added , But we find that the performance is not improved, but decreased . In a popular word, the explanation is , More nodes don't mean higher performance , So-called “ Bottomless pit ” That is to say, more input does not necessarily mean more output . But distribution is inevitable , Because the amount of access and data is increasing , A node can't resist at all , So how to efficiently batch operate in distributed cache is a difficult problem .
Analysis of bottomless cave problem :
① A batch operation of the client will involve multiple network operations , This means that batch operations will increase with the number of nodes , It's going to take longer .
② More network connections , It also has a certain impact on the performance of nodes .
How to optimize batch operation under distributed conditions ? Let's take a look at the common IO Optimization idea :
Optimization of the command itself , For example, optimization SQL Statement etc. .
Reduce the number of network communications .
Reduce access costs , For example, the client uses long connection / Connection pool 、NIO etc. .
Here we assume that the command 、 The client connection has been optimized , Focus on reducing the number of network operations . Next we will combine Redis Cluster Four distributed batch operation modes are described in this paper .
① Serial command : because n individual key It's more evenly distributed in Redis Cluster On each node of , So I can't use mget Command one time get , So generally speaking, we need to get n individual key Value , The easiest way is to do it step by step n individual get command , This kind of operation has high time complexity , Its operating time =n Sub network time +n Time of the second order , The number of networks is n. Obviously this is not the best solution , But the implementation is relatively simple .
② Serial IO :Redis Cluster Use CRC16 The algorithm calculates the hash value , Take the right one again 16383 You can calculate the remainder of slot value , meanwhile Smart The client will save slot The corresponding relationship and the corresponding node , With these two data, you can transfer the data belonging to the same node key Filing , Get the... For each node key Child list , And then for each node mget perhaps Pipeline operation , Its operating time =node Sub network time +n Time of the second order , The number of networks is node The number of , The whole process is shown in the following figure , Obviously, this is a much better solution than the first one , But if there are too many nodes , There are still some performance problems .
③ parallel IO : This plan is to put the plan 2 Change the last step in to multithreading , Although the number of network times is still the number of nodes , But with multithreading, network time becomes O(1), This solution increases the complexity of programming .
④hash_tag Realization :Redis Cluster Of hash_tag function , It can transfer multiple key Force assignment to a node , Its operating time =1 Sub network time +n Time of the second order .
Comparison of four batch operation solutions 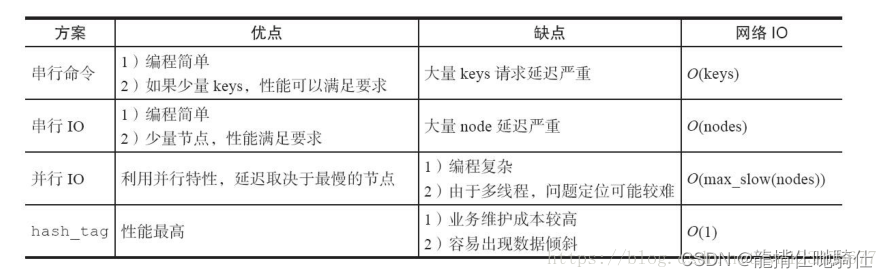
6、 Avalanche optimization
Cache avalanche : Because the cache layer carries a lot of requests , Effectively protects the storage tier , But if the cache layer cannot provide services for some reason , So all the requests will reach the storage layer , The number of calls to the storage layer will skyrocket , Cause cascading downtime in the storage tier .
Prevent and solve buffer avalanche problem , We can start from the following three aspects :
① Ensure high availability of cache layer services . If the cache layer is designed to be highly available , Even if individual nodes 、 Individual machines 、 Even the computer room went down , Services are still available , For example, as mentioned above Redis Sentinel and Redis Cluster High availability is realized .
② Rely on the isolation component to limit the flow to the back end and degrade . In the actual project , We need important resources ( for example Redis、MySQL、HBase、 External interface ) They're all quarantined , Let each resource run in its own thread pool , Even if there are problems with individual resources , No impact on other services . But how to manage thread pools , For example, how to close the resource pool 、 Open resource pool 、 Resource pool threshold management , It's quite complicated to do .
③ Drill in advance . Before the project goes online , After the walkthrough cache layer goes down , Application and backend load and possible problems , On this basis, make some plans .
7、 hotspot key Reconstruction optimization
Used by developers “ cache + Expiration time ” The strategy can speed up data reading and writing , And ensure the regular update of data , This model can basically meet most of the needs . But if there are two problems at the same time , May cause fatal damage to the application :
At present key It's a hot spot key( For example, a popular entertainment news ), The amount of concurrency is very large .
Rebuilding the cache cannot be done in a short time , It could be a complex calculation , For example, complicated SQL、 many times IO、 Multiple dependencies, etc . In the moment of cache failure , There are a lot of threads to rebuild the cache , Cause the back-end load to increase , It might even crash the app .
It's not very complicated to solve this problem , But it can't bring more trouble to the system to solve this problem , So we need to set the following goals :
Reduce the number of cache rebuilds
The data is as consistent as possible .
Less potential danger
① The mutex : This method allows only one thread to rebuild the cache , Other threads wait for the thread to rebuild the cache to finish , Get the data from the cache again , The whole process is as shown in the figure .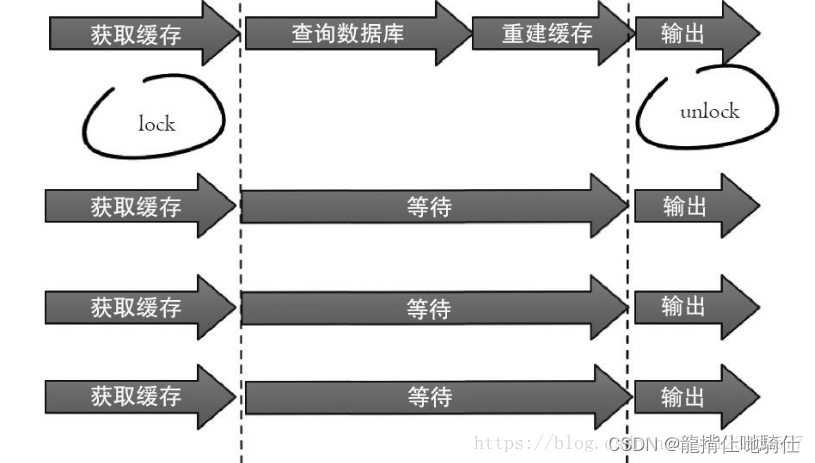
The following code uses Redis Of setnx Command to achieve the above functions :
1) from Redis get data , If the value is not null , The value is returned directly ; Otherwise, perform the following 2.1) and 2.2) step .
2.1) If set(nx and ex) The result is true, This indicates that there are no other threads rebuilding the cache at this time , Then the current thread executes the cache build logic .
2.2) If set(nx and ex) The result is false, This indicates that other threads are already building the cache , Then the current thread will rest for a specified time ( For example, here is 50 millisecond , Depends on how fast the cache is built ) after , Re execute function , Until the data is obtained .
② Never expire
“ Never expire ” It has two meanings :
At the cache level , It's true that the expiration time is not set , So there will be no hot spots key Problems after expiration , That is to say “ Physics ” Not overdue .
From a functional point of view , For each value Set a logical expiration time , When it is found that the logical expiration time is exceeded , Will use a separate thread to build the cache .
From the perspective of actual combat , This method effectively eliminates hot spots key The problems that arise , But the only drawback is refactoring the cache period , There will be data inconsistencies , It depends on whether the application tolerates this inconsistency .
Two hot spots key Solutions for 
Only when you start , You will reach your ideal and destination , Only when you work hard ,
You will achieve brilliant success , Only when you sow , You will gain something . Only pursue ,
To taste the taste of success , Sticking to yesterday is called foothold , Sticking to today is called enterprising , Sticking to tomorrow is called success . Welcome all friends to praise + Collection !!!
边栏推荐
- ERROR 2003 (HY000): Can‘t connect to MySQL server on ‘localhost:3306‘ (10061)
- Defects of matrix initialization
- 2787: calculate 24
- Vscode connected to the remote server cannot format the code / document (resolved)
- Cloud native observability tracking technology in the eyes of Baidu engineers
- Docker builds redis and clusters
- [feature selection] several methods of feature selection
- Open source demo | release of open source example of arcall applet
- Failed to create a concurrent index, leaving an invalid index. How to find it
- One bite of Stream(7)
猜你喜欢

Sword finger offer 15. number of 1 in binary

Rce (no echo)

What does software testing need to learn?

Multiplication and addition of univariate polynomials
![[jzof] 06 print linked list from end to end](/img/c7/c2ac4823b5697279b81bec8f974ea9.png)
[jzof] 06 print linked list from end to end
Native applets are introduced using vant webapp
Summary of yarn capacity scheduler

Go language pack management
Mitmproxy tampering with returned data

C synchronous asynchronous callback state machine async await demo
随机推荐
Generate self signed certificate: generate certificate and secret key
MySQL docker installation master-slave deployment
Practical skills!!
Pychart tutorial: 5 very useful tips
The relationship between cloud computing and digital transformation has finally been clarified
Shenzhen Merchants Securities account opening? Is it safe to open a mobile account?
How to buy Xinke financial products in CICC securities? Revenue 6%
Multiplication and addition of univariate polynomials
Leetcode skimming -- bit by bit record 018
Together again Net program hangs dead, a real case analysis of using WinDbg
Put apples
Evolution of network IO model
API data interface for historical data of A-share index
[install PG]
The maximum number of expressions in ora-01795 list is 1000
Press Ctrl to pop up a dialog box. How to close this dialog box?
Quick sort
Solution: 2003 cant connect to MySQL server on * * * * and use near 'identified by' * * * * 'with grant option' at
Chrome realizes automated testing: recording and playback web page actions
Intel internship mentor layout problem 1