当前位置:网站首页>10 common high-frequency business scenarios that trigger IO bottlenecks
10 common high-frequency business scenarios that trigger IO bottlenecks
2022-06-10 02:00:00 【Liziti】
High quality resource sharing
| Learning route guidance ( Click unlock ) | Knowledge orientation | Crowd positioning |
|---|---|---|
| 🧡 Python Actual wechat ordering applet 🧡 | Progressive class | This course is python flask+ Perfect combination of wechat applet , From the deployment of Tencent to the launch of the project , Create a full stack ordering system . |
| Python Quantitative trading practice | beginner | Take you hand in hand to create an easy to expand 、 More secure 、 More efficient quantitative trading system |
** Abstract :** From the perspective of application business optimization , Trigger with common IO Slow business SQL Take the scene , Guide how to improve by optimizing the business IO Efficiency and reduction IO.
This article is shared from Huawei cloud community 《GaussDB(DWS) Performance optimization business degradation IO Optimize 》, author :along_2020.
IO high ? Business is slow ? stay DWS In the actual business scenario, there are IO high 、IO Bottlenecks cause a lot of performance problems , The problems caused by unreasonable application business design account for the majority . From the perspective of application business optimization , Trigger with common IO Slow business SQL Take the scene , Guide how to improve by optimizing the business IO Efficiency and reduction IO.
explain : Due to disk failure ( Such as slow disk )、raid Card read / write strategy ( Such as Write Through)、 The inequality between the active and standby servers in the cluster is caused by non application services IO Gao is not in this discussion .
One 、 determine IO bottleneck & Identify high IO The sentence of
1、 Check and wait for the view to confirm IO bottleneck
SELECT wait\_status,wait\_event,count(*) AS cnt FROM pgxc\_thread\_wait\_status
WHERE wait\_status <> 'wait cmd' AND wait\_status <> 'synchronize quit' AND wait\_status <> 'none'
GROUP BY 1,2 ORDER BY 3 DESC limit 50;
IO Common waiting states during bottleneck are as follows :

2、 Grab high IO The consumption of SQL
The main idea is to pass first OS The command identifies high consumption threads , Then combine DWS The thread number information of finds the business with high consumption SQL, See the attachment for the specific method iowatcher.py Scripts and README Introduction
3、SQL level IO Fundamentals of problem analysis
When grabbing to consume IO High business SQL How to analyze after ? Master the following two basic knowledge :
1)PGXC_THREAD_WAIT_STATUS View function , For details, see :
https://support.huaweicloud.com/devg2-dws/dws_0402_0892.html
2)EXPLAIN function , At least the knowledge points you need to master are Scan operator 、A-time、A-rows、E- rows, For details, see :
https://bbs.huaweicloud.com/blogs/197945
Two 、 Common triggers IO High frequency business scenarios of bottlenecks
scene 1: Column save small CU inflation
A business SQL Query out 390871 Pieces of data need 43248ms, The analysis plan mainly takes time Cstore Scan

Cstore Scan In the details of , Every DN Scan out 2w Left and right data , But I scanned those with data CU(CUSome) 155079 individual , Without data CU(CUNone) 156375 individual , Explain the current small CU、 Missing data CU A lot , That is to say CU The expansion is serious .

Triggers : Inventory table ( The partition table is especially ) High frequency small batch import will cause CU inflation
processing method :
1、 The data warehousing method of the column storage table is modified to save and batch warehousing , The data quantity of single partition and single batch warehousing is greater than DN Number *6W It is advisable to
2、 If the approval cannot be saved due to business reasons , Then consider the secondary option , regular VACUUM FULL This kind of high frequency and small batch import column storage table .
3、 When small CU When it expands rapidly , frequent VACUUM FULL It will also consume a lot of IO, Even aggravate the IO bottleneck , At this time, it is necessary to consider the rectification to save the table in rows (CU In case of serious long-term expansion , The advantages of storage space and sequential scanning performance of column storage will no longer exist ).
scene 2: Dirty data & Data cleaning
some SQL Total execution time 2.519s, among Scan Account for the 2.516s, At the same time, the scanning of the table only reaches 0 Eligible data , It's filtered out 20480 Data , That is, a total of 20480+0 Pieces of data are consumed 2s+, The scanning time is seriously inconsistent with the amount of scanning data , Basically, dirty data affects scanning and IO efficiency .

The dirty page rate of the view table is 99%,Vacuum Full After that, the performance is optimized to 100ms about

Triggers : Tables execute frequently update/delete Cause too much dirty data , And for a long time VACUUM FULL clear
processing method :
- Yes, frequently update/delete Tables that generate dirty data , regular VACUUM FULL, Because of the big watch VACUUM FULL It will also consume a lot of IO, Therefore, it is necessary to perform the following tasks when the business is at a low peak , Avoid exacerbating business peaks IO pressure .
- When dirty data is generated very quickly , frequent VACUUM FULL It will also consume a lot of IO, Even aggravate the IO bottleneck , At this time, we need to consider whether the generation of dirty data is reasonable . For frequent delete Scene , Consider the following :1) Total quantity delete It is amended as follows truncate Or use a temporary table instead 2) regular delete Data of a certain period of time , Design the composition block table and use truncate&drop Partition substitution
scene 3: Table storage skew
Such as table Scan Of A-time in ,max time dn Execution time consuming 6554ms,min time dn Time consuming 0s,dn The difference between scans exceeds 10 More than times , This collection Scan Details of , Basically, it can be determined that the table storage skew causes

adopt table_distribution It is found that all the data are tilted to dn_6009 Single dn, Modify the distribution column so that the table storage is evenly distributed ,max dn time and min dn time Basically at the same level 400ms about ,Scan The time from 6554ms Optimize to 431ms.

Triggers : Distributed scenarios , Improper selection of table distribution columns will lead to storage skew , At the same time DN Pressure unbalance between , single DN IO High pressure , whole IO Decline in efficiency .
terms of settlement : Modify the distribution column of the table so that the storage of the table is evenly distributed , For the selection principle of distribution columns, refer to 《GaussDB 8.x.x Product documentation 》 in “ Table design best practices ” And “ Select the distribution column chapter ”.
scene 4: No index 、 There's an index
For example, query at a certain point ,Seq Scan Scanning requires 3767ms, Because it involves from 4096000 Data 8240 Data , Match the scenario of index scanning ( Look for a small amount of data in a large amount of data ), After adding an index to the filter condition column , The plan remains Seq Scan And didn't go Index Scan.
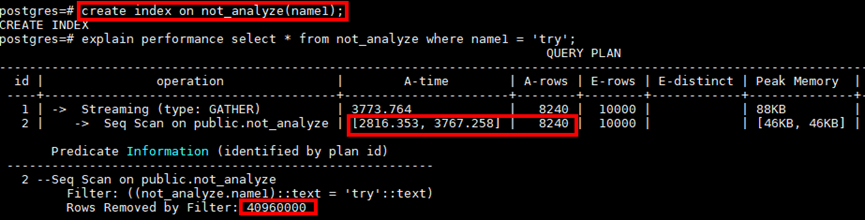
For the target table analyze after , The plan can automatically select the index , Performance from 3s+ Optimize to 2ms+, Greatly reduce IO Consume

Common scenes : The query scenario of saving large tables in rows , Access very little data from a large amount of data , Instead of an index scan, it is a sequential scan , Lead to IO Low efficiency , There are two common cases when the index is not used :
- There is no index on the filter condition column
- There is an index but no index scan is planned
Triggers :
- Common filter condition columns are not indexed
- The data in the table is due to DML The data characteristics are not changed in time ANALYZE As a result, the optimizer cannot select the index scan plan ,ANALYZE For an introduction, see https://bbs.huaweicloud.com/blogs/192029
Processing mode :
1、 Add an index to the common filter columns of the row storage table , Basic design principles of index :
- Index column selection distinct It's worth more , It is often used for filtering conditions , When there are many filtering conditions, you can consider building a composite index , In the composite index distinct Columns with many values are listed first , The number of indexes should not exceed 3 individual
- Importing a large amount of data with indexes will produce a large number of IO, If the table involves a large amount of data import , The number of indexes should be strictly controlled , It is recommended to delete the index before importing , The index will be rebuilt after the derivative is completed ;
2、 Yes, do it frequently DML Table of operations , Add timeliness to the business ANALYZE, Main scene :
- Table data from scratch
- Watch frequently INSERT/UPDATE/DELETE
- Table data plug and play , You need to access immediately and only the data you just inserted
scene 5: No zones 、 There are partitions without pruning
For example, a business table is used for mobilization createtime The time column is used as a filter condition to obtain specific time data , The table is designed as a partitioned table without partition pruning (Selected Partitions A large number ),Scan It took 701785ms,IO Extremely inefficient .

Adding partition keys creattime As a filter condition ,Partitioned scan Take the area pruning (Selected Partitions The quantity is very small ), Performance from 700s Optimize to 10s,IO The efficiency is greatly improved .

Common scenes : A large table that stores data over time , Most of the query features are to access the data of the current day or a few days , In this case, partition pruning should be done through the partition key ( Scan only a few partitions ) To greatly improve IO efficiency , The common cases of not going through zone pruning are :
- The composition area table is not designed
- Designed partition without using partition key as filter condition
- When the partition key is used as the filter condition , There are function conversions for column values
Triggers : The partition table and partition pruning function are not used properly , Resulting in low scanning efficiency
Processing mode :
- Design component area tables for large tables stored and accessed according to time characteristics
- The partition key generally has a high dispersion 、 Often used to query filter Time type field in the condition
- Partition interval generally refers to the interval used by high-frequency queries , It should be noted that for the column save table , Partition interval is too small ( For example, by hour ) It may cause too many small files , It is generally recommended that the minimum interval be by day .
scene 6: Rows are stored in tables for count value
For example, a row is frequently stored in a large table count( Without filter Conditions or filter Conditional filtering of very little data count), among Scan cost 43s, Continue to occupy a lot of IO, When such jobs are concurrent , The whole system IO continued 100%, Trigger IO bottleneck , The overall performance is slow .

Compare the column storage tables with the same amount of data (A-rows Are all 40960000), Listed Scan It only costs 14ms,IO Very low occupancy

Triggers : Row save tables are stored in different ways , Full table scan Is less efficient , Frequent large table full table scanning , Lead to IO Continue to take up .
terms of settlement :
- A comprehensive list of business side review videos count The necessity of , Lower the whole table count Frequency and concurrency of
- If the business type conforms to the inventory table , Then the row save table is modified to column save table , Improve IO efficiency
scene 7: Rows are stored in tables for max value
For example, find a row to store a column in a table max value , It cost 26772ms, When such jobs are concurrent , The whole system IO continued 100%, Trigger IO bottleneck , The overall performance is slow .

in the light of max After the column is indexed , The statement takes from 26s Optimize to 32ms, Greatly reduce IO Consume

Triggers : Bank deposit statement max Value by value scan The value that meets the condition max, When scan When there is a large amount of data , Will continue to consume IO
terms of settlement : to max Column increase index , rely on btree Index naturally ordered features , Speed up the scanning process , Reduce IO Consume .
scene 8: A large number of data are imported with indexes
The scenario data of a customer goes to DWS When the synchronization , The delay is serious , Cluster as a whole IO High pressure .

There are a large number of background view waiting views wait wal sync and WALWriteLock state , Are all xlog sync

Triggers : Mass data with index ( Generally more than 3 individual ) Import (insert/copy/merge into) It will produce a lot of xlog, This causes slow synchronization between the active and standby systems , Long term standby Catchup, whole IO Utilization is soaring . Historical case reference :https://bbs.huaweicloud.com/blogs/242269
Solution :
- Strictly control the number of indexes in each table , Suggest 3 Within a
- Delete the index before importing a large amount of data , The index will be rebuilt after the derivative is completed ;
scene 9: First query of row saving large table
A customer scenario appears DN continued Catcup,IO High pressure , Observe a sql Wait for the view to wait wal sync

It is found that a query statement takes a long time to execute ,kill After recovery
Triggers : After a large amount of data in row storage table is warehoused , The first query triggers page hint Produce a lot of XLOG, Trigger slow and large number of active and standby synchronization IO Consume .
Solutions :
- A scenario in which a large amount of new data is accessed at one time , Change to column save table
- close wal_log_hints and enable_crc_check Parameters ( There is a risk of loss of data during failure , Not recommended )
scene 10: Many small files IOPS high
After a batch of businesses at a certain business site have started , Entire cluster IOPS soar , In addition, when a cluster failure occurs , long-term building It's not over ,IOPS soar , The relevant table information is as follows :
SELECT relname,reloptions,partcount FROM pg\_class c INNER JOIN (
SELECT parented,count(*) AS partcount FROM pg\_partition
GROUP BY parentid ) s ON c.oid = s.parentid ORDER BY partcount DESC;

Triggers : A business library has a large number of columns and multiple partitions (3000+) Table of , Resulting in a large number of small files ( single DN file 2000w+), Inefficient access , Fault recovery Building Extremely slow , meanwhile building It also consumes a lot of IOPS, Direction affects business performance .
terms of settlement :
- Improve the interval of storage partition , Reduce the number of partitions to reduce the number of files
- Column save table is changed to row save table , The storage characteristics of row storage determine that the number of files will not be as bloated as column storage
3、 ... and 、 Summary
After the previous case , To sum up, it is not difficult to find , promote IO Efficiency can be summarized into two dimensions , That is, ascension IO Storage efficiency and computing efficiency ( Also called access efficiency ), Improving storage efficiency includes consolidating small CU、 Reduce dirty data 、 Eliminate storage skew, etc , Improving computing efficiency includes partition pruning 、 Index scanning, etc , You can deal with it flexibly according to the actual scene .
- The attachment :iowatcher.rar

Huawei partners and developers conference 2022 The fire is coming , Heavy content can't be missed !
【 Wonderful activities 】
March forward courageously · Be an all-around Developer →12 Technology live broadcast ,8 High energy output of the great technical treasure , And the code room 、 Many rounds of mysterious tasks such as knowledge competition are waiting for you to challenge . Break through immediately , Open the ultimate prize ! Click to embark on the promotion of all-round developers !
【 Technical topics 】
The future has to ,2022 Technical exploration → Huawei's cutting-edge technologies in various fields 、 Heavy open source project 、 Innovative application practice , Standing at the entrance of the intelligent world , Explore how the future shines into reality , Full of dry goods, click to learn
Click to follow , The first time to learn about Huawei's new cloud technology ~
边栏推荐
- MySQL 多表查询
- Brief introduction to Allan variance definition and calculation method
- Implementing nested sliding boxes in unity
- 【LeetCode】114. Expand binary tree into linked list
- 服务器停止响应是什么意思,该如何排查?
- [email protected] 项目实训
- 证明婚内出轨的几种证据
- 【LeetCode】287. Find duplicates
- 【LeetCode】128. Longest continuous sequence
- LabVIEW在波形图或波形图表上显示时间和日期
猜你喜欢

Smart Cloud Light Gateway Service pour améliorer l'efficacité de la gestion de la production

Phantom engine plug-in - Maya LIVELINK - install and use

The idea version of postman comes out, which is easy to test and use
机智云轻网关服务,提升生产管理效率

SSM framework integration - build a simple account login system

TRichView and ScaleRichView 设置默认中文

2022年广东省安全员A证第三批(主要负责人)考试模拟100题及答案

你不会还在用Xshell吧?这款开源的终端工具才是yyds!

2022年制冷与空调设备运行操作复训题库模拟考试平台操作
Free batch import software for generating sitemap maps
随机推荐
[email protected]和[email protected]装载5-Fu(5-氟尿
Graduated in 985, failed to start a business at the age of 35, returned at the age of 36, and was laid off at the age of 40. What should middle-aged couples do if they are unemployed?
D materialize function parameters
基于OpenVINO部署的工业缺陷检测产业实践范例实战
LABVIEW_课堂笔记 随机(十三)子VI
【LeetCode】287. Find duplicates
The transfer of production lines to Vietnam may not be a good choice. Samsung mobile phones have been affected and plan to return to South Korea
Brief introduction to Allan variance definition and calculation method
Experimental three character type and its operation (New)
Internet of things engineering design and Implementation
Web server-side technical test question bank
Software engineering final review
【LeetCode】221. Largest Square
iNFTnews | 元宇宙进行时:那些跑步入场的互联网大厂在如何谋篇布局?
iNFTnews | NFT在Web3经济里的未来
[image classification case] (10) three classifications of animal images of vision transformer, with complete pytoch code attached
【LeetCode】437. Path sum III
2022 mobile crane driver test questions simulation test platform operation
Is Guotai Junan safe to open an account
Full score after 5 years of "research" and 3 years of "actual combat"