当前位置:网站首页>Beyond convnext, replknet | look 51 × 51 convolution kernel how to break ten thousand volumes!
Beyond convnext, replknet | look 51 × 51 convolution kernel how to break ten thousand volumes!
2022-07-25 17:11:00 【Tom Hardy】
Click on the above “3D Visual workshop ”, choice “ Star standard ”
The dry goods arrive at the first time

The author 丨 ChaucerG
Source: Jizhi bookboy

since
Vision Transformers(ViT) Since its appearance ,TransformersQuickly shine in the field of computer vision . Convolutional neural networks (CNN) The leading role of seems to be more and more effectively based onTransformerThe challenge of the model . lately , Some advanced convolution models are designed using the mechanism driven by local large attentionKernelConvolution module for counterattack , And show attractive performance and efficiency . One of them , namelyRepLKNet, With improved performanceKernel-sizeExtended to31×31, But withSwin TransformerWait for advancedViTCompared with the expansion trend of , WithKernel-sizeThe continuous growth of , Performance starts to saturate .
In this paper , The author explored that training is greater than 31×31 The possibility of extreme convolution , And test whether the performance gap can be eliminated by strategically expanding convolution . This research finally got an application from the perspective of sparsity kernel Methods , It can smooth kernel Extended to 61×61, And has better performance . Based on this method , The author puts forward Sparse Large Kernel Network(SLaK), This is a kind of equipment 51×51 kernel-size Pure CNN framework , Its performance can be compared with the most advanced layering Transformer And the modern ConvNet framework ( Such as ConvNeXt and RepLKNet, About ImageNet Classification and typical downstream tasks .
1 Application exceeds 31×31 Super convolution kernel
The author first studies greater than 31×31 The extremes of Kernel-size Performance of , And summarized 3 There are three main observations . Here the author ImageNet-1K Recently developed on CNN framework ConvNeXt As the subject of this study benchmark.
The author pays attention to the recent use Mixup、Cutmix、RandAugment and Random Erasing As a work of data enhancement . Random depth and Label smoothing Apply for regularization , Have and ConvNeXt The same super parameter in . use AdamW Training models . In this section , All models are aimed at 120 individual epoch The length of , To observe only the big Kernel-size Zoom trend .
Observe 1: Existing techniques cannot extend convolution beyond 31×31
lately ,RepLKNet The convolution is successfully extended to 31×31. The author further Kernel-size Add to 51×51 and 61×61, Look at the bigger kernel Whether it can bring more benefits . according to RepLKNet In the design , Put the... Of each stage in turn Kernel-size Set to [51,49,47,13] and [61,59,57,13].

The test accuracy is shown in table 1 Shown . As expected , take Kernel-size from 7×7 Add to 31×31 Will significantly reduce performance , and RepLKNet This problem can be overcome , Improve accuracy 0.5%. However , This trend does not apply to larger kernel, Because the Kernel-size Add to 51×51 Start damaging performance .
A reasonable explanation is , Although receptive field can be used by very large
kernel, Such as51×51and61×61To expand the receptive field , But it may not maintain some desirable characteristics , Such as locality . Because of the standardResNetandConvNeXtMediumstem cellResulting in the input image 4× Downsampling , have51×51The extreme nuclei of have been roughly equal to the typical224×224ImageNetGlobal convolution of . therefore , This observation is meaningful , Because inViTsIn a similar mechanism ,Local attentionUsually better thanGlobal attention. On this basis , The opportunity to solve this problem by introducing locality , At the same time, it retains the ability to capture global relationships .
Observe 2: Put a square big kernel Decompose into 2 A rectangular one parallel kernels, Can be Kernel-size Shrink smoothly into 61.

Although using a medium-sized convolution ( for example ,31×31) It seems that this problem can be avoided directly , But the author just wants to see if it can be used ( overall situation ) Extreme convolution to further promote cnn Performance of . The method used by the author here is to use 2 A combination of parallel and rectangular convolutions to approximate large M×M kernel, Their Kernel-size Respectively M×N and N×M( among N<M), Pictured 1 Shown . stay RepLKNet after , Keep one 5×5 Layer and large kernel parallel , And summarize their output after a batch norm layer .
This decomposition not only inherits big kernel The ability to capture remote dependencies , And it can extract local context features with short edges . what's more , With depth Kernel-size An increase in , Existing large kernel Training technology will be affected by secondary calculation and memory overhead .
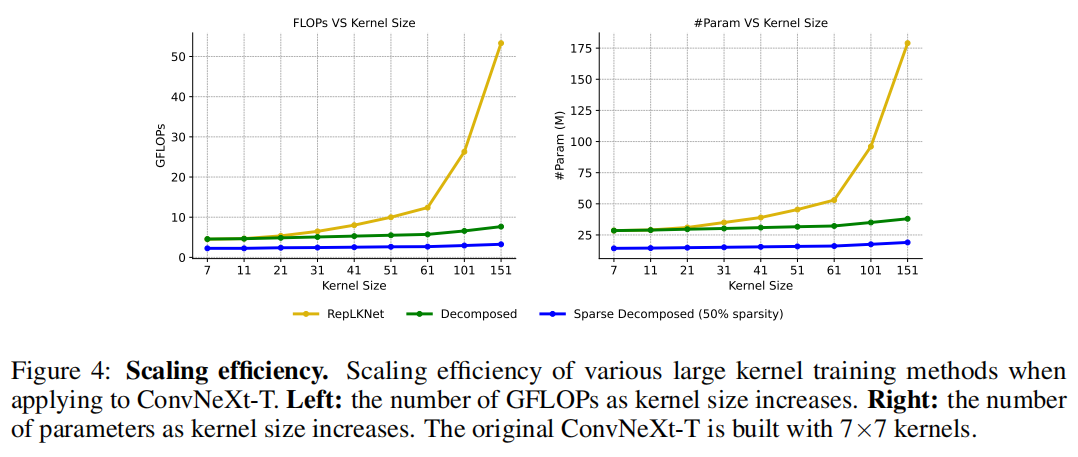
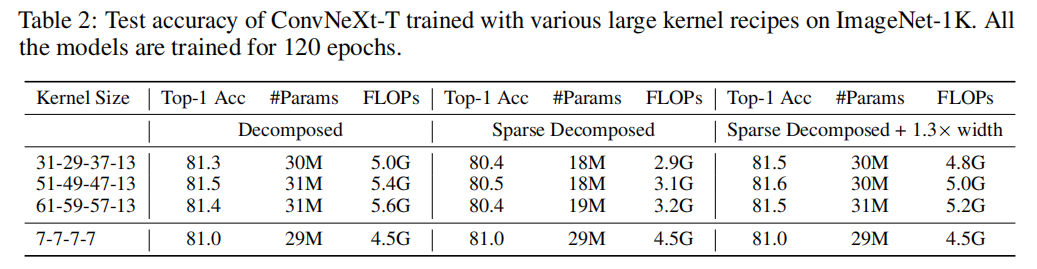
In sharp contrast to it is , The cost of this method increases with Kernel-size Linear increase ( chart 4).N = 5 Of kernel The decomposition performance is shown in table 2 It is reported as “ decompose ” Group . Due to the reduction of decomposition FLOP, With medium kernel The structure of is re parameterized (RepLKNet) comparison , It is expected that the network will sacrifice some accuracy , namely 31×31. However , As the convolution size increases to global convolution , It can amazingly Kernel-size Extended to 61 And improve performance .
Observe 3:“use sparse groups, expand more” Significantly improve the capacity of the model
Recently proposed ConvNeXt Revisited ResNeXt The principle introduced in , This principle divides the convolution filter into smaller but more groups .ConvNeXt Standard group convolution is not used , Instead, we simply use depth convolution to increase the width “use more groups, expand width” The goal of . In this paper , The author attempts to extend this principle from another alternative perspective ——“use sparse groups, expand more”.
say concretely , First use Sparse convolution Instead of Dense convolution , among Sparse kernel Is based on SNIP The hierarchical sparseness ratio of random construction . After building , Training sparse models with dynamic sparsity , Among them, the sparse weight is pruned by the weight of the minimum amplitude in the training process , Randomly increase the same number of weights for dynamic adjustment . Doing so can dynamically adapt to sparse weights , So as to obtain better local features .
because kernel It is sparse during the whole training process , Corresponding parameter counting and training / The inference flow is only proportional to the dense model . To evaluate , With 40% After sparse decomposition kernel, And report its performance as “ Sparse decomposition ” Group . It can be in the table 2 In the middle column of , Dynamic sparsity is significantly reduced FLOPs exceed 2.0G, This leads to temporary performance degradation .
Next , The author proves that the efficiency of the above dynamic sparsity can be effectively transferred to the scalability of the model . Dynamic sparsity allows the scale of the model to be friendly . for example , Use the same sparsity (40%), You can expand the width of the model 1.3×, Keep the parameter count and FLOPs It is roughly the same as the dense model . This leads to significant performance improvements , In the extreme 51×51kernel Next , Performance from 81.3% Up to 81.6%. What's impressive is that , This method is equipped with 61×61 kernel , The performance exceeds the previous RepLKNet, At the same time, it saves 55% Of FLOPs.
2Sparse Large Kernel Network - SLaK
up to now , It has been found that the method in this paper can successfully integrate Kernel-size Extended to 61, There is no need for reverse trigger performance . It includes 2 A design inspired by sparsity .
At the macro level , Built a Essentially sparse network , And further expand the network , In order to improve the network capacity while maintaining the scale of similar models .
At the micro level , Put a dense big kernel Decompose into 2 Two complements with dynamic sparsity kernel, To improve big kernel extensibility .
Different from the traditional pruning after training , A network that trains directly from scratch , Without any pre training or fine tuning . On this basis, we put forward Sparse Large Kernel Network(SLaK), This is a pure CNN framework , Extreme 51×51kernel.
SLaK Is based on ConvNeXt The architecture of . Stage calculation ratio and stem cell design are inherited from ConvNeXt. The number of blocks in each stage is for SLaK-T by [3, 3, 9, 3], about SLaK-S/B by [3, 3, 27, 3].stem cell It's just one with kernel-size by 4×4 and stride=4 The convolution of layer . The author will ConvNeXt Stage Kernel-size Increased to [51, 49, 47, 13], And will each M×M kernel Replace with M×5 and 5×M kernel The combination of , Pictured 1 Shown . The author found that adding before summing the output , Directly in each decomposed kernel After that BatchNorm Layer is crucial .
follow “use sparse groups, expand more” Guidelines for , Further sparse the entire network , Expand the stage width 1.3 times , The resulting SLaK-T/S/B. Although we know that we can improve by adjusting the trade-off between model width and sparsity SLaK There is a lot of room for performance , But for the sake of simplicity , Keep the width of all models 1.3 times . The sparsity of all models is set to 40%.
Although the model is configured with extreme 51×51kernel, But the overall parameter count and FLOP Not too much , And because of RepLKNet Excellent implementation provided , It is very effective in practice .
3 experiment
3.1 Classified experiments

3.2 Semantic segmentation

4 Reference resources
[1].More ConvNets in the 2020s : Scaling up Kernels Beyond 51 × 51 using Sparsity.
This article is only for academic sharing , If there is any infringement , Please contact to delete .
Dry goods download and learning
The background to reply : Barcelo that Autonomous University courseware , You can download the precipitation of foreign universities for several years 3D Vison High quality courseware
The background to reply : Computer vision Books , You can download it. 3D Classic books in the field of vision pdf
The background to reply :3D Visual courses , You can learn 3D Excellent courses in the field of vision
Computer vision workshop boutique course official website :3dcver.com
1. Multi sensor data fusion technology for automatic driving field
2. For the field of automatic driving 3D Whole stack learning route of point cloud target detection !( Single mode + Multimodal / data + Code )
3. Thoroughly understand the visual three-dimensional reconstruction : Principle analysis 、 Code explanation 、 Optimization and improvement
4. China's first point cloud processing course for industrial practice
5. laser - Vision -IMU-GPS The fusion SLAM Algorithm sorting and code explanation
6. Thoroughly understand the vision - inertia SLAM: be based on VINS-Fusion The class officially started
7. Thoroughly understand based on LOAM Framework of the 3D laser SLAM: Source code analysis to algorithm optimization
8. Thorough analysis of indoor 、 Outdoor laser SLAM Key algorithm principle 、 Code and actual combat (cartographer+LOAM +LIO-SAM)
10. Monocular depth estimation method : Algorithm sorting and code implementation
11. Deployment of deep learning model in autopilot
12. Camera model and calibration ( Monocular + Binocular + fisheye )
13. blockbuster ! Four rotor aircraft : Algorithm and practice
14.ROS2 From entry to mastery : Theory and practice
15. The first one in China 3D Defect detection tutorial : theory 、 Source code and actual combat
16. be based on Open3D Introduction and practical tutorial of point cloud processing
blockbuster ! Computer vision workshop - Study Communication group Established
Scan the code to add a little assistant wechat , You can apply to join 3D Visual workshop - Academic paper writing and contribution WeChat ac group , Aimed at Communication Summit 、 Top issue 、SCI、EI And so on .
meanwhile You can also apply to join our subdivided direction communication group , At present, there are mainly ORB-SLAM Series source code learning 、3D Vision 、CV& Deep learning 、SLAM、 Three dimensional reconstruction 、 Point cloud post processing 、 Autopilot 、CV introduction 、 Three dimensional measurement 、VR/AR、3D Face recognition 、 Medical imaging 、 defect detection 、 Pedestrian recognition 、 Target tracking 、 Visual products landing 、 The visual contest 、 License plate recognition 、 Hardware selection 、 Depth estimation 、 Academic exchange 、 Job exchange Wait for wechat group , Please scan the following micro signal clustering , remarks :” Research direction + School / company + nickname “, for example :”3D Vision + Shanghai Jiaotong University + quietly “. Please note... According to the format , Otherwise, it will not pass . After successful addition, relevant wechat groups will be invited according to the research direction . Original contribution Please also contact .

▲ Long press and add wechat group or contribute
▲ The official account of long click attention
3D Vision goes from entry to mastery of knowledge : in the light of 3D In the field of vision Video Course cheng ( 3D reconstruction series 、 3D point cloud series 、 Structured light series 、 Hand eye calibration 、 Camera calibration 、 laser / Vision SLAM、 Automatically Driving, etc )、 Summary of knowledge points 、 Introduction advanced learning route 、 newest paper Share 、 Question answer Carry out deep cultivation in five aspects , There are also algorithm engineers from various large factories to provide technical guidance . meanwhile , The planet will be jointly released by well-known enterprises 3D Vision related algorithm development positions and project docking information , Create a set of technology and employment as one of the iron fans gathering area , near 4000 Planet members create better AI The world is making progress together , Knowledge planet portal :
Study 3D Visual core technology , Scan to see the introduction ,3 Unconditional refund within days
There are high quality tutorial materials in the circle 、 Answer questions and solve doubts 、 Help you solve problems efficiently
Feel useful , Please give me a compliment ~
边栏推荐
- 备考过程中,这些“谣言”千万不要信!
- Frustrated Internet people desperately knock on the door of Web3
- 【南京航空航天大学】考研初试复试资料分享
- 一百个用户眼中,就有一百个QQ
- 【PHP伪协议】源码读取、文件读写、任意php命令执行
- Mindoc makes mind map
- Roson的Qt之旅#100 QML四种标准对话框(颜色、字体、文件、提升)
- From digitalization to intelligent operation and maintenance: what are the values and challenges?
- 2022 latest Beijing Construction welder (construction special operation) simulation question bank and answer analysis
- Getting started with easyUI
猜你喜欢
![[target detection] yolov5 Runtong voc2007 dataset (repair version)](/img/b6/b74e93ca5e1986e0265c58f750dce3.png)
[target detection] yolov5 Runtong voc2007 dataset (repair version)

jenkins的文件参数,可以用来上传文件

jenkins的Role-based Authorization Strategy安装配置

在华为昇腾Ascend910上复现swin_transformer
![[redis] redis installation](/img/4a/750a0b8ca72ec957987fc34e55992f.png)
[redis] redis installation

第六章 继承

MySQL linked table query, common functions, aggregate functions

EasyUI DataGrid control uses

Enterprise live broadcast: witness focused products, praise and embrace ecology

Starting from business needs, open the road of efficient IDC operation and maintenance
随机推荐
从数字化到智能运维:有哪些价值,又有哪些挑战?
气数已尽!运营 23 年,昔日“国内第一大电商网站”黄了。。。
Solution for win10 device management not recognizing gtx1080ti display device
Redis cluster deployment based on redis6.2.4
Step by step introduction of sqlsugar based development framework (13) -- package the upload component based on elementplus, which is convenient for the project
霸榜COCO!DINO: 让目标检测拥抱Transformer
【南京航空航天大学】考研初试复试资料分享
01.两数之和
为什么 4EVERLAND 是 Web 3.0 的最佳云计算平台
2022年最新北京建筑施工焊工(建筑特种作业)模拟题库及答案解析
What is the monthly salary of 10000 in China? The answer reveals the cruel truth of income
Random talk on generation diffusion model: DDPM = Bayesian + denoising
stm32F407------SPI
第五章:流程控制
ACL 2022 | 基于最优传输的对比学习实现可解释的语义文本相似性
Lvgl 7.11 tileview interface cycle switching
02. Add two numbers
Rainbow plug-in extension: monitor MySQL based on MySQL exporter
Google Earth engine - download the globalmlbuildingfootprints vector collection of global buildings
Update 3dcat real time cloud rendering V2.1.2 release