当前位置:网站首页>Rich text editor copying pictures in word documents
Rich text editor copying pictures in word documents
2022-06-12 11:42:00 【Jioho_】
List of articles
It's a little long , I feel very wordy every time I write an article , If you don't want to see the process, just skip to * Hands-on practice That step , There is a core method ~
Rich text editor copy word Pictures in the document
- The problem is : from word The pictures of the contents copied in the document are
file:///agreement , At this time, if our page ishttp://perhapshttps://agreement , It is not allowed to read pictures .

Unless the page is also opened in a local file ( But in the actual project, it is basically impossible ):

And ckeditor regret we didn't meet sooner

see ,ckeditor It supports ! However, the project at this time already has too many historical burdens ( Including the plug-ins newly developed later , I use it tinymce )
Not that tinymce Not good. , It's just that you'll find ... It's really bad ( it's a long story , Record later tinymce When I was in roast )
If you also have editor requirements , And there is no historical burden , Try it directly ckeditor hold
Get a preview of the picture
To get pictures , Start with the clipboard , Because our data source was finally copied from the clipboard .
Let's get to know a few knowledge points first , In order to better understand the following content
- Why can't websites read pictures directly ? Because of security :
ckeditor No matter how powerful it is, it is impossible to http/https Read the web address under the agreement file:/// The file of . The reason is also simple , If it can be read , Isn't the website able to read all our information ?
- word Inside the document
word The document only needs to change the suffix to .zip. Then open the corresponding directory , You will find that the picture is inside , and word There is another one in the catalog webSettings.xml There is... In it word Information about the document . If you are interested, you can find one by yourself

- About the system clipboard /JS Medium clipboardData
We often use the function of copying a certain paragraph of words , In fact, the core is to use window Sub object clipboardData One way :setData()
clipboardData.setData(sDataFormat, sData)
- sDataFormat: Format of the content to be copied ;
- sData: Content to copy .
Just because clipboardData Or experimental function , So I don't use much at ordinary times . The next thing I want to say is sDataFormat Is closely linked .
Get the contents of the clipboard
- Actively seek
shortcoming :
- Only in https Use under the domain name ( See the picture below 1)
- The page must focus , The mouse doesn't work on the console ( See the picture below 2)
- Will be found , Even rejected ( See the picture below 3)
advantage :
- It allows you to get the contents of the clipboard ...



navigator.clipboard
.readText()
.then(v => {
console.log(' Get clipboard succeeded :', v)
})
.catch(v => {
console.log(' Failed to get clipboard : ', v)
})
- Controlled acquisition monitor ctrl + v / Paste the event
Use event Medium clipboardData call getData Method , At present, I know the following parameters
textGet texttext/htmlobtain html Texttext/plainGet plain text , Effect and text equallytext/rtfobtain rtf Information ( Ask no questions , What is rtf)
window.addEventListener('paste', function(e) {
const clipdata = e.clipboardData || window.clipboardData
let data = clipdata.getData('text/html')
console.log(data)
})
PS: Copy it and paste it on the page , You don't have to find the input box , Press down ctrl+v Just go
Output is as follows : There are a lot of messy labels on it ,wps Just like office Much cleaner , This is from office Copied in .

clipdata.getData('text/html')That is, the method we use for rich text , Get the pasted content html Code Note that text/html There's a pit here , We'll talk about that later
clipdata.getData('text/rtf')What you get is even more chaotic , But it contains our picture information ( My documents are 2 A picture ,11mb. terrible )

With the above basic knowledge , We can get rid of the rich text editor , First, let's implement the screenshot at the front of an article , Paste display word Functions of documents .
<body>
<p> Please press ctrl+v Paste content </p>
<div id="preview"></div>
<script> window.addEventListener("paste", function (e) {
const clipdata = e.clipboardData || window.clipboardData; document.querySelector('#preview').innerHTML = clipdata.getData("text/html") }); </script>
</body>
</html>
obtain word Pictures in the document
According to the below ckeditor Source code to learn , The specific code is in
GitHub:ckeditor5-paste-from-office
Or from npm download :@ckeditor/ckeditor5-paste-from-office
Analysis of the source code :
src/index.js -> src/pastefromoffice.js ( stay init Function , Executed a activeNormalizer.execute Method )-> src/normalizers/mswordnormalizer.js
Here we see a replaceImagesSourceWithBase64 Method , This is the core of today's learning
replaceImagesSourceWithBase64 Method
The method in :src/filters/image.js
stay replaceImagesSourceWithBase64 Function , The method related to pictures is :
findAllImageElementsWithLocalSourceFind all file:/// The first picture
createRangeIn、new Matcher、 These methods don't need too much attention , Because all that is copied in is text , These could be ckeditor The core code is converted to dom Node method
We directly render the rough point to the real dom, Then in the operation of real dom Is it
The first 12 That's ok , obtain src yes file:// At the beginning dom node
function findAllImageElementsWithLocalSource(documentFragment, writer) {
const range = writer.createRangeIn(documentFragment)
const imageElementsMatcher = new Matcher({
name: 'img'
})
const imgs = []
for (const value of range) {
if (imageElementsMatcher.match(value.item)) {
if (value.item.getAttribute('src').startsWith('file://')) {
imgs.push(value.item)
}
}
}
return imgs
}
- Then perform
replaceImagesFileSourceWithInlineRepresentationMethod . Before that, we will executeextractImageDataFromRtf
extractImageDataFromRtf Method
It's also in src/filters/image.js
This part of the code takes us from the clipboard getData('text/rtf') The obtained value is processed , Extract the picture information inside ( I admit I didn't understand what was extracted , I am right. rtf I don't know much about , Ha ha ha ha )
function extractImageDataFromRtf(rtfData) {
if (!rtfData) {
return []
}
const regexPictureHeader = /{\\pict[\s\S]+?\\bliptag-?\d+(\\blipupi-?\d+)?({\\\*\\blipuid\s?[\da-fA-F]+)?[\s}]*?/
const regexPicture = new RegExp('(?:(' + regexPictureHeader.source + '))([\\da-fA-F\\s]+)\\}', 'g')
const images = rtfData.match(regexPicture)
const result = []
if (images) {
for (const image of images) {
let imageType = false
if (image.includes('\\pngblip')) {
imageType = 'image/png'
} else if (image.includes('\\jpegblip')) {
imageType = 'image/jpeg'
}
if (imageType) {
result.push({
hex: image.replace(regexPictureHeader, '').replace(/[^\da-fA-F]/g, ''),
type: imageType
})
}
}
}
return result
}
replaceImagesFileSourceWithInlineRepresentation
The method under the same document
The first parameter passed in is src by file:// Image node array of , The second is from rtf Extracted image information array , The third is ckeditor My own way , Used to display text , Don't worry about him
There's also a _convertHexToBase64 Method , hold hex Convert to base64
Then there is a cycle , Replace the corresponding node with the corresponding base64, Set... To the picture node src On , But here they use their own packaging writer.
function replaceImagesFileSourceWithInlineRepresentation(imageElements, imagesHexSources, writer) {
// Assume there is an equal amount of image elements and images HEX sources so they can be matched accordingly based on existing order.
if (imageElements.length === imagesHexSources.length) {
for (let i = 0; i < imageElements.length; i++) {
const newSrc = `data:${
imagesHexSources[i].type};base64,${
_convertHexToBase64(imagesHexSources[i].hex)}`
writer.setAttribute('src', newSrc, imageElements[i])
}
}
}
function _convertHexToBase64(hexString) {
return btoa(
hexString
.match(/\w{2}/g)
.map(char => {
return String.fromCharCode(parseInt(char, 16))
})
.join('')
)
}
Hands-on practice , Get picture information and show
The above analyses some ckeditor After code , In fact, what we need to use is
findAllImageElementsWithLocalSource- This method has been modified , Read the actual... Directly dom node , Get the picture node
replaceImagesFileSourceWithInlineRepresentation- This method is also changed in the final assignment , Because we have recorded the actual dom node , So use it directly .setAttribute(‘src’,newSrc)
extractImageDataFromRtf_convertHexToBase64
The sorted code is as follows :
<body>
<p> Please press ctrl+v Paste content </p>
<div id="preview"></div>
<script> window.addEventListener("paste", function (e) {
const clipdata = e.clipboardData || window.clipboardData; document.querySelector('#preview').innerHTML = clipdata.getData("text/html") let rtf = clipdata.getData('text/rtf') let imgs = findAllImageElementsWithLocalSource() replaceImagesFileSourceWithInlineRepresentation(imgs, extractImageDataFromRtf(rtf)) }); function findAllImageElementsWithLocalSource() {
let imgs = document.querySelectorAll('img') return imgs; } function extractImageDataFromRtf(rtfData) {
if (!rtfData) {
return []; } const regexPictureHeader = /{\\pict[\s\S]+?\\bliptag-?\d+(\\blipupi-?\d+)?({\\\*\\blipuid\s?[\da-fA-F]+)?[\s}]*?/; const regexPicture = new RegExp('(?:(' + regexPictureHeader.source + '))([\\da-fA-F\\s]+)\\}', 'g'); const images = rtfData.match(regexPicture); const result = []; if (images) {
for (const image of images) {
let imageType = false; if (image.includes('\\pngblip')) {
imageType = 'image/png'; } else if (image.includes('\\jpegblip')) {
imageType = 'image/jpeg'; } if (imageType) {
result.push({
hex: image.replace(regexPictureHeader, '').replace(/[^\da-fA-F]/g, ''), type: imageType }); } } } return result; } function _convertHexToBase64(hexString) {
return btoa(hexString.match(/\w{2}/g).map(char => {
return String.fromCharCode(parseInt(char, 16)); }).join('')); } function replaceImagesFileSourceWithInlineRepresentation(imageElements, imagesHexSources, writer) {
// Assume there is an equal amount of image elements and images HEX sources so they can be matched accordingly based on existing order. if (imageElements.length === imagesHexSources.length) {
for (let i = 0; i < imageElements.length; i++) {
const newSrc = `data:${
imagesHexSources[i].type};base64,${
_convertHexToBase64(imagesHexSources[i].hex)}`; imageElements[i].setAttribute('src',newSrc) } } } </script>
</body>
</html>
Add a beautiful thing to a contrasting beautiful thing , Upload pictures
After going through the above series of methods , We did get it base64 Format picture , But the display is too long , If you want to upload , We have to start a new one at the back end base64 How to upload pictures ...
base64 Convert to blod object
blod We usually use input Select the picture and get it File type ( I don't know if the explanation is wrong , That's probably what it means )
The method is as follows :
/** take base64 Convert to file object * @param {String} base64 base64 character string * */
function convertBase64ToBlob(base64) {
var base64Arr = base64.split(',')
var imgtype = ''
var base64String = ''
if (base64Arr.length > 1) {
// If it's a picture base64, Remove the header information
base64String = base64Arr[1]
imgtype = base64Arr[0].substring(base64Arr[0].indexOf(':') + 1, base64Arr[0].indexOf(';'))
}
// take base64 decode
var bytes = atob(base64String)
//var bytes = base64;
var bytesCode = new ArrayBuffer(bytes.length)
// Convert to a typed array
var byteArray = new Uint8Array(bytesCode)
// take base64 Convert to ascii code
for (var i = 0; i < bytes.length; i++) {
byteArray[i] = bytes.charCodeAt(i)
}
// Generate Blob object ( File object )
return new Blob([bytesCode], {
type: imgtype })
}
The effect is as follows

Optimized display URL
The upload problem is solved , But so long base64 It's really annoying , Fortunately, we still have ObjectURL
It's much fresher all at once :
let boldFile = convertBase64ToBlob('base64 String ')
// Use it directly URL.createObjectURL Generate
imageElements[i].setAttribute('src', URL.createObjectURL(boldFile))
blod turn base64
Now that it's all here , There's another conversion, by the way
function readBlobAsDataURL(blob, callback) {
var a = new FileReader()
a.onload = function(e) {
callback(e.target.result)
}
a.readAsDataURL(blob)
}
readBlobAsDataURL('blod File object ', function(base64) {
console.log(base64)
})
Read the picture , Picture shows , Include image conversion to blod Objects also have , As long as the picture is uploaded , In echo , It's all alive ~
summary
The core principles include ckeditor Part of the source code interpretation is over , Of course, there are many details not considered , Including some label conversion , Tag filtering , Style filtering , The most important thing is to judge whether the copied ones are word file , And if you can't get it rtf And so on , Can study ckeditor Code for
Process summary
- Listen for paste events , Get clipboard data ( Include
text/htmlandtext/rtf) - Get html Rear handle
file://At the beginning img Find the node , Then use the transformation method to convertrtfThe corresponding picture information is also found one by one - Use hex turn base64 Method to get the picture base64 Information , And then we need to convert
Colored eggs - Next episode Trailer
It says there is a pit , Is what we get getData('text/html') and getData('text/rtf')
this 2 Something doesn't appear out of thin air , And artificially set ( Don't think that everything copied has text/html)
These things are all set up in the clipboard setData('text/html'). What is set , To get something ( Because I stepped into this hole in another function of rich text , Include safari Browsers also have holes !)
The next article will write about this clipboard pit !
Copy word There are really few articles on the principle of document and picture ~ I hope this article can help you
边栏推荐
- Unity connect to Microsoft SQLSERVER database
- ioremap
- 进程的创建和回收
- QT based travel query and simulation system
- Judge whether the network file exists, obtain the network file size, creation time and modification time
- rosbridge使用案例心得总结之_第26篇在同一个服务器上打开多个rosbridge服务监听端口
- Go sends SMS based on alicloud
- VirtualBox 虚拟机因系统异常关机虚拟机启动项不见了
- go基于腾讯云实现发送短信
- 【QNX Hypervisor 2.2 用户手册】4.1 构建QNX Hypervisor系统的方法
猜你喜欢

Selenium uses proxy IP

Clj3-100alh30 residual current relay

ARM指令集之批量Load/Store指令

VirtualBox virtual machine shut down due to abnormal system. The virtual machine startup item is missing
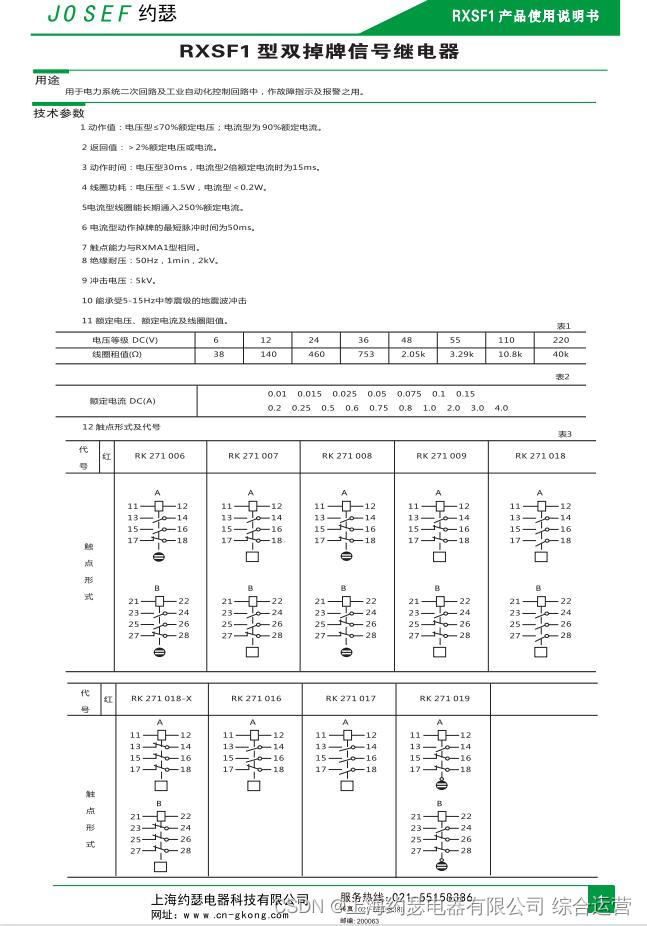
Signal relay rxsf1-rk271018dc110v

Redis summary
当自己有台服务器之后

Byte order - how to judge the big end and the small end

M-arch (fanwai 10) gd32l233 evaluation -spi drive DS1302

Mcuxpresso develops NXP rt1060 (3) -- porting lvgl to NXP rt1060
随机推荐
【QNX Hypervisor 2.2 用户手册】4 构建QNX Hypervisor系统
How to view glibc version
ioremap
Reentrantlock source code analysis
C# 36. DataGridView line number
如何确定首页和搜索之间的关系呢?首页与搜索的关系
IP地址管理
【蓝桥杯单片机 国赛 第十一届】
Problems in cross validation code of 10% discount
Differences among various cross compiling tools of arm
kubernetes集群搭建
System.IO.FileLoadException异常
邻居子系统之邻居项状态更新
Inter class and intra class relations in video classification -- regularization
B.刷墙(C语言)
ARM处理器模式与寄存器
Unit test case framework --unittest
K52. Chapter 1: installing kubernetes v1.22 based on kubeadm -- cluster deployment
ARM指令集之跳转指令
Golang基础(7)