当前位置:网站首页>JVM Part 1: memory and garbage collection -- runtime data area 4 - program counter
JVM Part 1: memory and garbage collection -- runtime data area 4 - program counter
2022-07-27 05:14:00 【_ Dean_】
JVM Part 1 : Memory and garbage collection – Runtime data area 4 - Program counter
1. Introduce
JVM Program count register in (Program Counter Register) in ,Register The name of comes from CPU The register of , register ** Store field information related to instructions .**CPU Only loading data into registers can run . here , It's not a physical register in a broad sense , Maybe translate it into PC Counter ( Or instruction counter ) It will be more appropriate ( Also known as program hook ), And it's not easy to cause some unnecessary misunderstandings .JVM Medium PC Registers are for physics PC An abstract simulation of registers .

It's a small piece of memory , I can almost ignore it . It's also JVM The fastest running storage area .
stay JVM Specification , Each thread has its own program counter , yes Thread private , The life cycle is consistent with the life cycle of the thread .
There is only one method in a thread at any time , It's the so-called current approach . The program counter stores what the current thread is executing Java Methodical JVM Instruction address ; perhaps , If it's execution native Method , The value is not specified (undefned).
- Local methods need to call C/C++ Library, so it is undefned
It's a program Indicator of control flow , Branch 、 loop 、 Jump 、 exception handling 、 Basic functions such as thread recovery rely on this counter .
Bytecode interpreterWhen you work, you know Select the next bytecode instruction to be executed by changing the value of this counter .It is the only one in Java Nothing is specified in the virtual machine specification outotMemoryError Area of situation .
- At the same time, it will not exist GC, Just store the address of the next instruction
2. effect
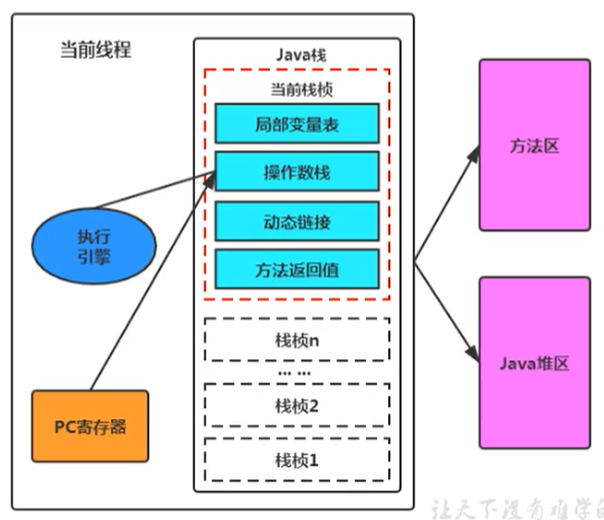
PC Registers are used to store the address to the next instruction , Also about to execute the instruction code . The execution engine reads the next instruction .
3. Code example
Write a simple code
public class PCRegisterTest {
public static void main(String[] args) {
int i = 10;
int j = 20;
int k = i + j;
String s = "abc";
System.out.println(i);
System.out.println(k);
}
}
Then compile the code into a bytecode file , Let's look at... Again , Find a line number to the left of bytecode , It's actually the instruction address , Used to point to where the current execution is .
0: bipush 10
2: istore_1
3: bipush 20
5: istore_2
6: iload_1
7: iload_2
8: iadd
9: istore_3
10: ldc #2 // String abc
12: astore 4
14: getstatic #3 // Field java/lang/System.out:Ljava/io/PrintStream;
adopt PC register , We can know where the current program is going
The execution engine finds the operation command through the instruction address in the register , To manipulate the local variable table , Operand stack and direction CPU Send machine instructions

4. Two common problems of registers
4.1 Use PC What's the use of register to store bytecode instruction address ?/ Why use PC Register records the execution address of the current thread ?
because CPU You need to switch threads all the time , Now, after switching back , You need to know where to start and continue .
JVM The bytecode interpreter needs to be changed PC Register value Specify what bytecode instructions should be executed next .

4.2PC Why are registers set to be thread private ?
We all know that the so-called multithreading will only execute one of the methods in a specific period of time ,CPU I'll keep switching tasks , This inevitably leads to frequent interruptions or recoveries , How to make sure there is no difference ? In order to accurately record the current bytecode instruction address that each thread is executing , The best way, of course, is to assign one to each thread PC register , In this way, each thread can be independently calculated , So that there will be no mutual interference .
because CPU Time slice wheel limit , Many threads are executing concurrently , Any definite moment , A core in a processor or multi-core processor , Only one instruction in a thread will be executed .
This inevitably leads to frequent interruptions or recoveries , How to make sure there is no difference ? After each thread is created , Will produce their own program counter and stack frame , Program counters do not affect each other among threads .

5. CPU Time slice
CPU Time slice is CPU Time allocated to each program , Each thread is assigned a time period , It's called a time slice .
On the macro : We can open multiple applications at the same time , Each program runs parallel , Running at the same time .
But in On the micro : Since there is only one CPU, Only part of the program's requirements can be processed at a time , How to deal with fairness , One way is to introduce time slices , Each program is executed in turn .

边栏推荐
- How does PS import LUT presets? Photoshop import LUT color preset tutorial
- Plato farm is expected to further expand its ecosystem through elephant swap
- Deep Qt5 signal slot new syntax
- Customize the viewport height, and use scrolling for extra parts
- Select user stories | the false positive rate of hole state in jushuitan is almost 0. How to do this?
- Differences among left join, inner join and right join
- QT 菜单栏、工具栏和状态栏
- Complete Binary Tree
- 安装Pygame
- 抽卡程序模拟
猜你喜欢

Jmeter 界面如何汉化?

Select user stories | the false positive rate of hole state in jushuitan is almost 0. How to do this?

Inspiration from "flying man" Jordan! Another "arena" opened by O'Neill
Another skill is to earn 30000 yuan a month+
![[error reporting] cannot read property 'parsecomponent' of undefined](/img/54/8d4225ec596d6b78348b181a3e636f.png)
[error reporting] cannot read property 'parsecomponent' of undefined

JVM上篇:内存与垃圾回收篇十一--执行引擎
【牛客讨论区】第七章:构建安全高效的企业服务

What about PS too laggy? A few steps to help you solve the problem
JVM上篇:内存与垃圾回收篇十四--垃圾回收器

pyside2____1.安装和案列
随机推荐
Deep Qt5 signal slot new syntax
35. Scroll
JVM上篇:内存与垃圾回收篇八--运行时数据区-方法区
微淼联合创始人孙延芳:以合规为第一要义,做财商教育“正规军”
There is no need to install CUDA and cudnn manually. You can install tensorflow GPU through a one-line program. Take tensorflow gpu2.0.0, cuda10.0, cudnn7.6.5 as examples
JVM上篇:内存与垃圾回收篇五--运行时数据区-虚拟机栈
How idea creates a groovy project (explain in detail with pictures and texts)
安装Pygame
事件总结-常用总结
Could not autowire.No beans of ‘userMapper‘ type found.
Introduction to dynamic memory functions (malloc free calloc realloc)
Row, table, page, share, exclusive, pessimistic, optimistic, deadlock
Detailed explanation of mvcc and its principle
pyside2____ 1. Installation and case listing
Counting Nodes in a Binary Search Tree
Use ngrok for intranet penetration
Use of file i/o in C
QT 菜单栏、工具栏和状态栏
Raspberry pie RTMP streaming local camera image
Why is count (*) slow