当前位置:网站首页>[NLP] this year's college entrance examination English AI score is 134. The research of Fudan Wuda alumni is interesting
[NLP] this year's college entrance examination English AI score is 134. The research of Fudan Wuda alumni is interesting
2022-06-28 10:03:00 【Demeanor 78】
bright and quick From the Aofei temple
qubits | official account QbitAI
After the challenge of writing Chinese composition ,AI Now I'm eyeing college entrance examination English .
Turns out, good guy , This year's college entrance examination English ( National A-test paper ) Get started , Just take 134 branch .

And it's not an accidental supernormal play .
stay 2018-2021 Year of 10 In the test of true questions ,AI All scores are 125 More than , The highest record is 138.5 branch , Listening and reading comprehension have also taken Full marks .
That's why CMU Proposed by scholars , College entrance examination English test AI System Qin.
Its parameter quantity is only GPT-3 Of 16 One of the points , The average score is better than GPT-3 Higher than 15 branch .

The secret behind it is called Reconstruction pre training (reStructured Pre-training), It is a new learning paradigm proposed by the author .
The specific term , Is to put Wikipedia 、YouTube And so on , Feed me again AI Training , So that AI It has stronger generalization ability .
The two scholars used enough 100 Multi page The paper of , This new paradigm is explained in depth .

that , What does this paradigm mean ?
Let's dig deep ~
What is refactoring pre training ?
The title of the thesis is very simple , Call reStructured Pre-training( Reconstruction pre training ,RST).

The core point of view is one sentence , want Value data ah !
The author thinks that , Valuable information is everywhere in the world , And now AI The system does not make full use of the information in the data .
Like Wikipedia ,Github, It contains various signals for model learning : Entity , Relationship , Text in this paper, , Text theme, etc . These signals have not been considered before due to technical bottlenecks .
therefore , In this paper, the author proposes a method , Neural network can be used to Storage and access Data containing various types of information .
They are in units of signals 、 Structured presentation data , This is very similar to data science, where we often construct data into tables or JSON Format , And then through special language ( Such as SQL) To retrieve the required information .
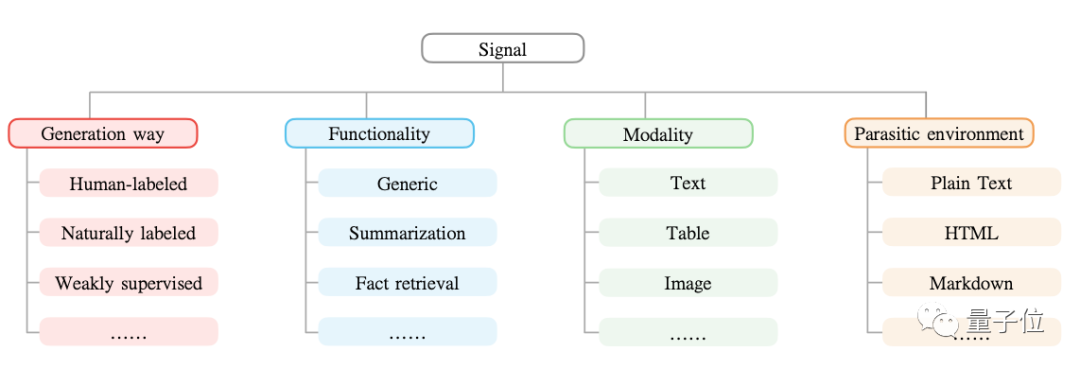
The specific term , The signal here , Actually, it refers to the useful information in the data .
For example “ Mozart was born in Salzburg ” In this sentence ,“ Mozart ”、“ Salzburg ” It's a signal .
then , It is necessary to mine data on various platforms 、 Pick up the signal , The author compares this process to looking for treasure from a mine .

Next , utilize prompt Method , These signals from different places can be unified into one form .
Last , Then integrate and store the reorganized data into the language model .
thus , The research can be started from 10 Data sources , Unified 26 Kind of Different types of signals , Make the model have strong generalization ability .
It turns out that , In multiple datasets ,RST-T、RST-A Zero sample learning performance , all be better than GPT-3 Small sample learning performance .

In order to further test the performance of the new method , The author also thought of making AI Do the college entrance examination Methods .
They said , At present, many working methods are sinicized GPT-3 The idea of , It also follows in the application scenario of evaluation OpenAI、DeepMind.
such as GLUE Evaluation benchmark 、 Protein folding score, etc .
Based on the present AI Observation of model development , The author thinks that we can open up a new track to try , So I thought of using the college entrance examination to AI Practice hands .
They found it for several years 10 Set of test papers for marking , Ask the high school teachers to grade .
Like hearing / Read pictures and understand such topics , And machine vision 、 Scholars in the field of speech recognition help .
Final , This set of college entrance examination English has been refined AI Model , You can also call her Qin.

As you can see from the test results ,Qin It's definitely Xueba level ,10 The scores of the test paper set are all higher than T0pp and GPT-3.

Besides , The author also puts forward the college entrance examination benchmark.
They feel that the task of many evaluation benchmarks is very single , Most of them have no practical value , It is also difficult to compare with human conditions .
The college entrance examination covers a variety of knowledge points , There are also human scores to compare directly , It can be said that killing two birds with one stone .
NLP The fifth paradigm of ?
If you look at it from a deeper level , The author thinks that , Refactoring pre training may become NLP A new paradigm of , Namely the Preliminary training / fine-tuning The process is regarded as data storage / visit The process .
before , The author will NLP The development of has been summed up as 4 There are paradigms :
P1. Fully supervised learning in the age of non neural networks (Fully Supervised Learning, Non-Neural Network)
P2. Fully supervised learning based on neural network (Fully Supervised Learning, Neural Network)
P3. Preliminary training , Fine tuning paradigm (Pre-train, Fine-tune)
P4. Preliminary training , Tips , Prediction paradigm (Pre-train, Prompt, Predict)

But based on the present NLP Observation of development , They thought maybe they could data-centric The way to look at things .
That is to say , Pre training / Fine tune 、few-shot/zero-shot The differentiation of such concepts will be more ambiguous , The core only focuses on one point ——
How much valuable information 、 How much .
Besides , They also put forward a NLP The evolutionary hypothesis .
The core idea is , The direction of technological development always follows this —— Do less to achieve better 、 A more general-purpose system .
The author thinks that ,NLP Experienced Feature Engineering 、 Architecture Engineering 、 Target project 、 Prompt project , At present, it is developing in the direction of data engineering .

Fudan Wuda alumni create
One of the achievements of this thesis Weizhe Yuan.
She graduated from Wuhan University , After that, he went to Carnegie Mellon University for postgraduate study , Study data science .
My research interests focus on NLP Task text generation and evaluation .
last year , She was AAAI 2022、NeurIPS 2021 Received one paper respectively , Also received ACL 2021 Best Demo Paper Award.

The corresponding author of this paper is the Institute of language technology, Carnegie Mellon University (LTI) Postdoctoral researcher of Liu Pengfei .
He is in 2019 He received his doctorate from the Department of computer science of Fudan University in , Under the guidance of Professor Qiu Xipeng 、 Professor Huang xuanjing .
Research interests include NLP Model interpretability 、 The migration study 、 Task learning, etc .
During the doctorate , He has won scholarships in various computer fields , Include IBM Doctoral Scholarship 、 Microsoft scholar Scholarship 、 Tencent AI Scholarship 、 Baidu Scholarship .

One More Thing
It is worth mentioning that , When liupengfei introduced this work to us , To be frank “ At first, we didn't plan to contribute ”.
This is because they do not want the format of the conference paper to limit the imagination of the paper .
We decided to tell this paper as a story , And give “ readers ” A movie experience .
That's why we're on page three , Set up a “ Viewing mode “ The panorama of .
Is to take you to understand NLP History of development , And what the future looks like , So that every researcher can have a certain sense of substitution , Feel yourself leading the pre training language models (PLMs) A process of mine treasure hunt towards a better tomorrow .

The end of the paper , There are also some surprise eggs .
such as PLMs Theme expression pack :

And the illustration at the end :

In this way ,100 Multi page I won't be tired after reading my thesis  ~
~
Address of thesis :
https://arxiv.org/abs/2206.11147
— End —

Past highlights
It is suitable for beginners to download the route and materials of artificial intelligence ( Image & Text + video ) Introduction to machine learning series download Chinese University Courses 《 machine learning 》( Huang haiguang keynote speaker ) Print materials such as machine learning and in-depth learning notes 《 Statistical learning method 》 Code reproduction album machine learning communication qq Group 955171419, Please scan the code to join wechat group
边栏推荐
- 纵观jBPM从jBPM3到jBPM5以及Activiti
- 通过PyTorch构建的LeNet-5网络对手写数字进行训练和识别
- Starting from full power to accelerate brand renewal, Chang'an electric and electrification products sound the "assembly number"
- What is the difference between MySQL development environment and test environment??
- Generate token
- Global exception handlers and unified return results
- dotnet 使用 Crossgen2 对 DLL 进行 ReadyToRun 提升启动性能
- 六月集训(第28天) —— 动态规划
- 各位大佬,问下Mysql不支持EARLIEST_OFFSET模式吗?Unsupported star
- [200 opencv routines] 213 Draw circle
猜你喜欢

Data visualization makes correlation analysis easier to use

mysql打不开,闪退

Solve the problem that the value of the action attribute of the form is null when transferring parameters

一文读懂 12种卷积方法(含1x1卷积、转置卷积和深度可分离卷积等)

通过PyTorch构建的LeNet-5网络对手写数字进行训练和识别

Xiaomi's payment company was fined 120000 yuan, involving the illegal opening of payment accounts, etc.: Lei Jun is the legal representative, and the products include MIUI wallet app
![[200 opencv routines] 213 Draw circle](/img/8d/a771ea7008f84ae3a3cf41507448ec.png)
[200 opencv routines] 213 Draw circle
Redis sentinel cluster main database failure data recovery ideas # yyds dry goods inventory #

理想中的接口自动化项目

Proxy mode (proxy)
随机推荐
六月集训(第28天) —— 动态规划
Redis sentinel cluster main database failure data recovery ideas # yyds dry goods inventory #
dotnet 使用 Crossgen2 对 DLL 进行 ReadyToRun 提升启动性能
sqlcmd 连接数据库报错
DolphinScheduler使用系统时间
Unity AssetBundle asset packaging and asset loading
Key summary IV of PMP examination - planning process group (2)
Read PDF image and identify content
浅谈小程序对传媒行业数字化的影响
MySQL基础知识点总结
Threads and processes
第五章 树和二叉树
SQL中的DQL、DML、DDL和DCL是怎么区分和定义的
Composite pattern
创建多线程的方法---1创建Thread类的子类及多线程原理
Stutter participle_ Principle of word breaker
适配器模式(Adapter)
Numpy array: join, flatten, and add dimensions
再见!IE浏览器,这条路由Edge替IE继续走下去
Custom exception classes and exercises