当前位置:网站首页>Vision Transformer (ViT)
Vision Transformer (ViT)
2022-07-05 22:46:00 【Lian Li o】
Catalog
Introduction
- ViT This paper proposes , In the image classification task ,CNN It's not necessary , pure Transformer It can also achieve good results . especially Pre training on a large amount of data When migrating to small and medium-sized datasets (ImageNet, CIFAR-100, VTAB, etc.), comparison SOTA CNNs,ViT Less training resources are needed to achieve better results
Method
Vision Transformer (ViT)
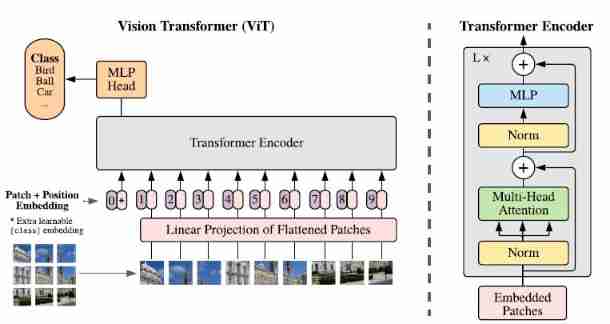
- The standard Transformer Accept token embeddings Sequence , So in order to directly Transformer Encoder Apply to images , We need to 2D Image processing is 1D vector . A very direct idea is to pass the picture pixels Embedding Feeding after layer Transformer, But a picture has many pixels , Doing so will cause the length of the input sequence to be too long . So ,ViT Divide a picture into several P × P = 16 × 16 P\times P=16\times 16 P×P=16×16 Of patches, Then put each patch Stretch into a vector , Send it into the linear layer to get the corresponding Embedding. for example , The input image size is 224 × 224 × 3 224\times224\times3 224×224×3, Can be divided into N = 22 4 2 1 6 2 = 196 N=\frac{224^2}{16^2}=196 N=1622242=196 individual patches, Every patch It is stretched into 16 × 16 × 3 = 768 16\times16\times3=768 16×16×3=768 Dimension vector , Into the linear projection layer (i.e. D × D D\times D D×D The full connection layer of ) obtain N × D = 196 × 768 N\times D=196\times768 N×D=196×768 Of patch embeddings Sequence . except patch embeddings,ViT And joined in position embeddings To express patches Location information between (learnable 1D position embeddings)
- In order to classify pictures , Be similar to BERT,ViT Also added
[class]token ( The input sequence length is 196 + 1 = 197 196+1=197 196+1=197), Its final output corresponds to the image representation y y y, Passing by a classification head Then we get the final category of pictures (classification head In pre training, it is a with a hidden layer MLP, Fine tuning is a linear layer , The activation function is GELU)
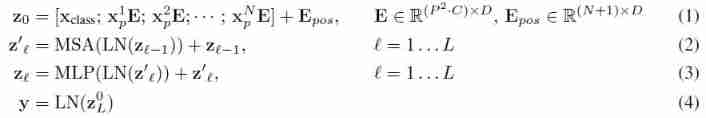
GAP v.s.
[CLS]
stay CV field , Use CNN When classifying images , A common practice is to pool the final feature map on a global average (GAP), Therefore, the author also used GAP and[CLS]Conduct classified ablation experiments , When using GAP when ,ViT Only for the final image-patch embeddings Global average pooling , Then use the linear layer to classify ( But pay attention to the learning rate and[CLS]Completely different ). The experimental results show that the effects of these two methods are similar , But to make ViT With the standard Transformer Closer to the , The author finally adopted[CLS]To classify
Inductive bias ( Inductive bias )
- ViT Than CNN There is a lot less inductive bias for images , For example, in CNN in ,locality (i.e. Locality . Adjacent areas on the image will have similar characteristics ) and translation equivariance (i.e. Translational equivariant . set up f f f For Pan operation , g g g For convolution operations , be f ( g ( x ) ) = g ( f ( x ) ) f(g(x))=g(f(x)) f(g(x))=g(f(x))) Embodied in every layer of the model , and ViT There are only MLP It is local and has translation equivariant , The self attention layer is global . Throughout ViT in , There is only a positional embedding Inductive bias for image is used , besides , The position information of all images must be learned from the model
- Therefore, due to the lack of inductive bias , When directly on a medium-sized dataset (ImageNet…) When training without strong regularization ,ViT Performance does not have the same size ResNet Good model . But if you let ViT Pre training on a larger data set , You can find that large-scale training is better than inductive bias (88.55% on ImageNet, 90.72% on ImageNet-ReaL, 94.55% on CIFAR-100, and 77.63% on the VTAB suite of 19 tasks)
Hybrid Architecture
- In addition to the above, the image is directly divided into several 16 × 16 16\times16 16×16 patches Methods ,ViT A hybrid structure is also proposed , That is, let the picture pass through a CNN The Internet , Then divide the feature map patches
Fine-tuning and Higher Resolution
- When pre training ViT When the model is fine tuned on downstream tasks , We need to Retraining classification head. If The image resolution of downstream tasks is higher , Models tend to achieve better results , At this time, if you keep patch size unchanged , Then you will get a larger sequence length , But at this time, meaningful positional embedding. So ,ViT For pre training positional embedding Conduct 2D interpolation
Experiments
Setup
Datasets
- ILSVRC-2012 ImageNet dataset (1k classes and 1.3M images)
- ImageNet-21k (21k classes and 14M images)
- JFT (18k classes and 303M high-resolution images)
The pre training data set removes the pictures that coincide with the downstream task data set
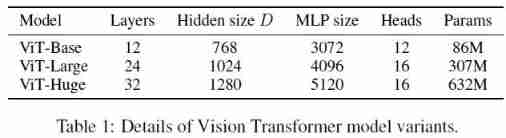
Model Variants
- “Base” and “Large” Model and BERT Agreement , In addition, it added “Huge” Model . In the later model naming , We use abbreviations , for example ViT-L/16 Express 16 × 16 16 × 16 16×16 input patch size Of “Large” Model
Baseline - ResNet (BiT)
- Internet use ResNet, But will Batch Normalization Replace for Group Normalization, And used standardized convolutions, These modifications improve the performance of transfer learning . We call the modified model “ResNet (BiT)”.
Comparison to SOTA
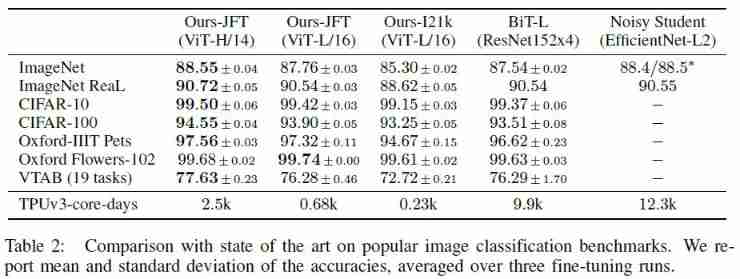
- You can see , stay JFT-300M Pre trained ViT In all benchmarks The performance exceeds ResNet-based baselines, And compared with CNN,ViT Less training resources are needed
Pre-training data requirements
- The following experiment studies Data set size is right ViT The impact of performance
After pre training on data sets of different sizes , stay ImageNet Fine tune up
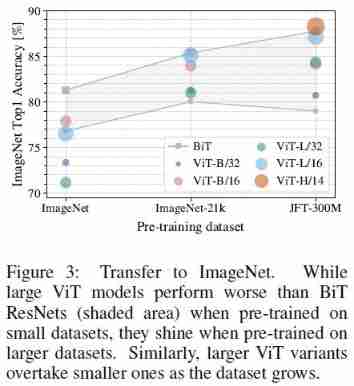
Grey shaded areas represent BiT Performance range ( Two different sizes of BiT The Internet )
In order to improve the performance of the model on small data sets , Used in the experiment 3 A regularization method - weight decay, dropout, and label smoothing And the corresponding parameters are optimized
Use JFT Pre train subsets of different sizes of data sets , stay ImageNet Fine tune up
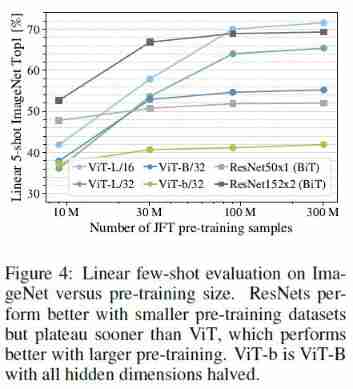
During the experiment, no additional regularization is carried out to eliminate the influence of regularization
Scaling study
stay JFT-300M Pre training , Migrate to other datasets
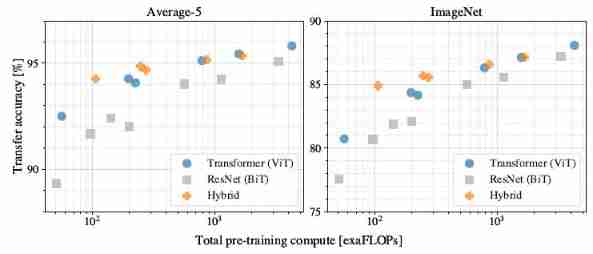
- (1) ViT stay performance/compute trade-off Crushed on ResNet, With less training resources, we can achieve ResNet Same performance ( Suppose you pre train on a large enough data set )
- (2) When there are few training resources ,hybrids The performance of the model is slightly better than ViT, However, the gap gradually decreases with the increase of model parameters
- (3) With the increase of model parameters ,ViT There is no sign of saturation , This shows that increasing the size of the model can further improve the performance of the model
Inspecting ViT
Patch embedding layer
- ViT Of patch embedding Layers will flattened patches Linear projection , The following figure shows what you have learned embedding filters The principal component of . These principal components seem to form a group that can express patch Basis function of texture structure

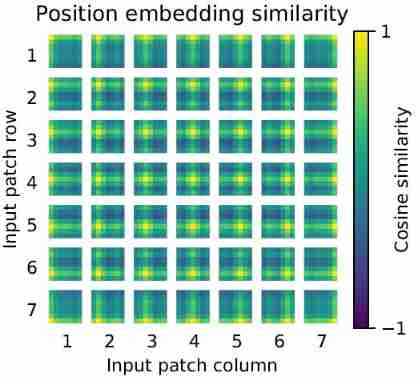
Position embeddings
- The figure below shows each of them patch And the rest patch Cosine similarity of . You can see , More similar in space patches Corresponding position embeddings Also more similar , besides , stay Of the same row or column patches Corresponding position embeddings Also more similar (a row-column structure)
Self-attention
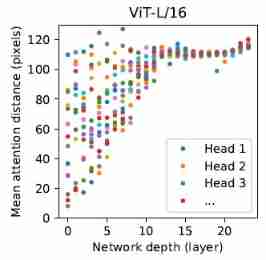
- Self-attention bring ViT It can integrate the global information of pictures from the bottom , The following experiment explores ViT To what extent has this ability been utilized . So , We calculated each Transformer Different blocks heads Of mean attention distance ( According to each head Different from patches The space distance between and attention weight Calculation , Be similar to CNN Receptive field in ), You can find , Somewhat heads At the bottom, we have begun to integrate the global information of the image , And others heads At the bottom, it is only responsible for integrating local information ( This locality lies in hybrids Less in the model , This indicates that their functions may be related to CNN Similar to the lower layer of ), also Overall speaking ,attention distances As the network depth increases , It shows that with the increase of the number of layers ,ViT Gradually pay attention to higher-level information
Attention map

- Use here Attention Rollout Visualizing . In short , That's right ViT-L/16 All of the heads Medium attention weights Calculate average , Then for all layers , Multiply the weight matrix recursively
Self-Supervision
- Transformers stay NLP The success of the field is not only due to its strong scalability , It is more about its large-scale self-monitoring pre training method . therefore , similar BERT, We also tried masked patch prediction, The final ViT-B/16 Model in ImageNet We got it 79.9% The accuracy of the , This is more accurate than the training from scratch 2%, But it is also less accurate than supervised learning 4%. This shows that ViT Self supervised learning It is still a direction worth exploring
References
边栏推荐
- 鏈錶之雙指針(快慢指針,先後指針,首尾指針)
- Record several frequently asked questions (202207)
- 70. Climbing Stairs. Sol
- How to reverse a string fromCharCode? - How to reverse String. fromCharCode?
- Unity Max and min constraint adjustment
- Request preview display of binary data and Base64 format data
- What if win11 is missing a DLL file? Win11 system cannot find DLL file repair method
- Distance entre les points et les lignes
- Global and Chinese market of diesel fire pump 2022-2028: Research Report on technology, participants, trends, market size and share
- 二叉树(三)——堆排序优化、TOP K问题
猜你喜欢
从 1.5 开始搭建一个微服务框架——日志追踪 traceId
I closed the open source project alinesno cloud service

Technology cloud report: how many hurdles does the computing power network need to cross?
基于STM32的ADC采样序列频谱分析
Editor extensions in unity
Arduino 测量交流电流
How can easycvr cluster deployment solve the massive video access and concurrency requirements in the project?
700. Search in a Binary Search Tree. Sol

Navigation day answer applet: preliminary competition of navigation knowledge competition

Metaverse ape received $3.5 million in seed round financing from negentropy capital
随机推荐
Win11 runs CMD to prompt the solution of "the requested operation needs to be promoted"
FBO and RBO disappeared in webgpu
Usage Summary of scriptable object in unity
从 1.5 开始搭建一个微服务框架——日志追踪 traceId
2022.02.13 - SX10-30. Home raiding II
What if the files on the USB flash disk cannot be deleted? Win11 unable to delete U disk file solution tutorial
Nacos 的安装与服务的注册
Global and Chinese market of networked refrigerators 2022-2028: Research Report on technology, participants, trends, market size and share
Record several frequently asked questions (202207)
QT creator 7 beta release
一文搞定JVM常见工具和优化策略
Editor extensions in unity
Binary tree (III) -- heap sort optimization, top k problem
Global and Chinese markets for children's amusement facilities 2022-2028: Research Report on technology, participants, trends, market size and share
Tiktok__ ac_ signature
Ultrasonic sensor flash | LEGO eV3 Teaching
记录几个常见问题(202207)
[agc009e] eternal average - conclusion, DP
Arduino 测量交流电流
Go language learning tutorial (XV)