当前位置:网站首页>论文解读——Performance of Recommender Algorithms on Top-N Recommendation Tasks
论文解读——Performance of Recommender Algorithms on Top-N Recommendation Tasks
2022-06-22 11:38:00 【百载文枢江左】
论文解读——Performance of Recommender Algorithms on Top-N Recommendation Tasks
简介
本文是Koren等人在RecSys2010上的会议论文,文章的核心思想是
- 证明了误差指标和精度指标之间不存在强关联,即那些目标函数是RMSE并通过优化使之最小的算法,在精度指标上precision和recall上不一定好;
- 文章建议在使用测试集时去除其中的流行项目,避免使得计算的精度偏向于非个性化方法。
在常见的商业系统中,常常出现的猜你喜欢的推荐,常常被认为是一个top-N推荐任务,即寻找少数让用户感兴趣的项目。常用的基于错误度量的指标如RMSE不适合用于评价top-N推荐任务,相反一些精度指标如precision和recall则可以直接用于度量top-N的推荐效果。
本文对大量最先进的推荐算法进行了丰富的实验。实验发现,为最小化RMSE而优化的算法在top-N推荐任务中的效果不及预期,即RMSE上的提高常常不能转化为精度上的提高,甚至一个简单的非个性化算法在性能上可以胜过一些常见方法,并几乎达到复杂算法的精度。另一个发现是,很少的最流行的项目会影响top-N推荐任务的精度。因此,在评判一个推荐系统在top-N推荐任务中的效果的时候,测试集应当被谨慎选择以避免精度指标偏向非个性化解决方案。最后,本文提出了两种新的、与RMSE无关的协同过滤算法,在top-N推荐任务中显著超越其他推荐算法,并具有一些其他实用优势。
1 介绍
一个非个性化的、基于流行度的算法只能提供简单的推荐,一方面,由于这个推荐系统对让用户感到乏味和失望,而使得用户不感兴趣,另一方面,由于内容提供商投资推荐系统的目的是提高不知名产品的销量,因而也不会令内容提供商感兴趣。出于这个原因,本文在去除了特别流行的项目之后,进行了一系列额外的评判算法效果的实验。正如预期的那样,由于在去除了流行性项目后更加难以推荐成功,所有算法的精度都下降了。然后,不同算法的排序更加符合我们的期望,即非个性化的方法排名下降了。因此,在评判一个推荐系统在top-N推荐任务中的效果的时候,测试集应当被谨慎选择以避免精度指标出现严重误差。
2 测试方法
该文使用的测试方法与当前的常用方法不太一致。
首先,使用训练集M对模型进行训练,然后对于在测试集T中被每个用户u评分过的项目i计算方法如下:
- 随机选择1000个未被用户u评分过额外的项目(这1000个项目不在训练集中,也不在测试集中),可以假设这1000个项目中的大部分用户是不感兴趣的(因为没有评分过,做此假设是合理的)
- 预测这1000个项目和项目I的评分
- 对预测出来的1001个项目的评分进行排序,用p表示项目I在这1001个项目中从高到低的排名,显然最理想的情况是p为1
- 通过从高到低提取N个项目,构建一个top-N推荐列表,如果 p ≤ N p\leq N p≤N,那么就算推荐成功,算一个hit
另外,需要注意的是,该文中定义的recall和我们常用的定义方式不同
r e c a l l ( N ) = # h i t s ∣ T ∣ recall(N)=\frac{\#hits}{\vert T\vert} recall(N)=∣T∣#hits
p r e c i s i o n ( N ) = # h i t s N ⋅ ∣ T ∣ = r e c a l l ( N ) N precision(N)=\frac{\# hits}{N \cdot \vert T \vert}=\frac{recall(N)}{N} precision(N)=N⋅∣T∣#hits=Nrecall(N)
2.1 流行项目vs长尾项目
大多数评分集中于小部分最流行的商品,比如在Netflix数据集中,33%的评分数据是关于1.7%的流行项目,而在Movielens在同样存在着33%的评分数据集中于5.5%的流行项目的现象。
3 协同算法
基于协同过滤的方法可以分为两种,基于邻居的方法和隐因子方法。
3.1 非个性化方法
本文中采用的非个性化方法包括:
- MovieAvg:推荐平均评分最高的N个项目
- Top-Pop:推荐最流行的,即有最多评分数据的N个项目
3.2 近邻模型
本文的近邻模型使用的是CorNgbr(Correlation Neighborhood)
使用的是项目间相似度,考虑到稀疏性,所以定义了一个衰减因子 λ 1 \lambda_1 λ1并设置为100,从而得到了衰减相似性 d i j = n i j n i j + λ 1 d_{ij}=\frac{n_{ij}}{n_{ij}+\lambda_1} dij=nij+λ1nij,其中 n i j n_{ij} nij是项目i和项目j被相同用户的评分的次数,该算法的实现可参照推荐系统surprise库教程中的KNNBasic算法。
r ^ u i = b u i + ∑ j ∈ N u k ( i ) d i j ⋅ ( r u j − b u j ) ∑ j ∈ N u k ( i ) d i j \hat{r}_{ui} = b_{ui} + \frac{ \sum\limits_{j \in N^k_u(i)} d_{i j} \cdot (r_{uj} - b_{uj})} {\sum\limits_{j \in N^k_u(i)} d_{ij}} r^ui=bui+j∈Nuk(i)∑dijj∈Nuk(i)∑dij⋅(ruj−buj)
未加分母的模型被称为NNCosNgbr,因为未加分母,因此该模型会给那些拥有更多邻居的项目更高的评分。
3.3 隐因子模型
这个主要涉及三个模型
- AsySVD 来自于作者的另一篇论文,后期会解读,欢迎关注
- SVD++ 就是推荐系统surprise库教程中的SVDpp算法
- PureSVD算法(作者在本文中提出的新的算法) r ^ u i = r u ⋅ Q ⋅ q i T \hat r_{ui}=r_u \cdot Q \cdot q_i^T r^ui=ru⋅Q⋅qiT值得注意的是,其中的Q并非迭代得到,而是通过 R ^ = U ⋅ ∑ ⋅ Q T \hat R=U\cdot \sum \cdot Q^T R^=U⋅∑⋅QT进行SVD奇异值分解得到
4 结果
本文中定义的recall和precision存在比例关系,因此结果中展示的recall的结果其实也就是precision的结果。
在Movielens数据集上,recall从高到低依次是:PureSVD50、NNCosNgbr、SVD++、PureSVD150、TopPop、AsySVD、CorNgbr和MovieAvg。因此,在精度上最优秀的算法是非基于RMSE的PureSVD和NNCosNgbr。
去除Movielens数据集中的流行项目后的精度排名依次是PureSVD150、PureSVD50、SVD++、NNCosNgbr、AsySVD、CorNgbr、MovieAvg和TopPop,结果更加符合期望。
Netflix数据集上的结果与之类似,不过值得注意的是,在去除了流行项目后,CosNgbr的表现十分突出,值得注意。
5 关于PureSVD的讨论
PureSVD表现优异,而且简单,即在训练模型时使用SVD分解即可,而不需要进行迭代学习。同时,作者指出了常用的RMSE测试方法的缺点,即只关注那些用户提供的评分,很适用于基于RMSE优化的算法。本文中使用的top-N测试方法更贴近实际,考虑了那些目前尚未有评分的项目。
6 结论
除了常用的RMSE测试方法之外,也应该关注top-N的精度评价指标。
边栏推荐
- haas506 2.0开发教程-高级组件库-modem.info(仅支持2.2以上版本)
- Typical life cycle model of information system project
- What is homology??? Cross domain error??? How to solve???
- KNN classification of MATLAB (with source code) is used to realize pixel classification (set the proportion of training set by yourself) and print test accuracy
- Reader case of IO
- 分享7个免费超清的影视资源站!不管是剪辑还是珍藏都实用到哭!
- Macro definition usage and typedef and Const
- Redis - 5、Jedis操作Redis6
- CF751E Phys Ed Online
- Collection of IO operation cases
猜你喜欢

【李宏毅】机器学习深度学习笔记 -- 训练模型通关攻略

分享7个免费超清的影视资源站!不管是剪辑还是珍藏都实用到哭!

KNN classification of MATLAB (with source code) is used to realize pixel classification (set the proportion of training set by yourself) and print test accuracy
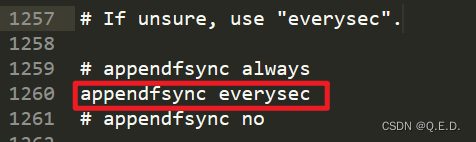
Redis - 9、持久化之AOF(Append OnlyFile)

Add custom fields to the time synchronization message based on uavcan protocol in Px4 code learning
MAUI使用Masa blazor组件库

在C#开发中使用第三方组件LambdaParser、DynamicExpresso、Z.Expressions,实现动态解析/求值字符串表达式
![[CISCN2019 总决赛 Day1 Web4]Laravel1](/img/99/4eb4d9447ac191fb9320cd8135f019.png)
[CISCN2019 总决赛 Day1 Web4]Laravel1

Dirichlet prefix and study notes

求100-200之间全部的素数
随机推荐
Linux安装部署MySQL5.7(企业常用版)超详细
Redis - 8、持久化之RDB(Redis DataBase)
Matlab的KNN分类使用(附源码),实现像素分类(自己设置训练集比例),打印测试精度
Cosmos、Polkadot
传统零售加速向新零售演进升级,零售数字化势在必行
MAUI使用Masa blazor组件库
IO之ByteStream案例
【云原生 | Kubernetes篇】Kubernetes简介(一)
Kruskal reconstruction tree
YuMinHong said that e-commerce schools may be opened in the future; Musk's son applied to sever the father son relationship; Hungry? Respond to a large number of users receiving the free order informa
成功案例 | 安超云助力兰州大学第二医院搭建新型IT基础设施平台 提升医疗信息资源利用率
宏定义使用以及typedef和const
牛客挑战赛53E题解 & 带花树学习笔记
推荐系统从入门到接着入门
arc128 C 凸包优化后缀和?
Lyndon breaks down learning notes
CF751E Phys Ed Online
马尔可夫链(Markov Chain),隐马尔可夫模型
Summary of SQL injection bypass methods
JMeter generates test reports