当前位置:网站首页>【無標題】
【無標題】
2022-06-26 10:12:00 【半_調_子】
第一:下載所有hadoop二進制包
第二:下載spark 包
第三:下載java
第四:下載anancode
# 創建虛擬環境 pyspark, 基於Python 3.8
conda create -n pyspark python=3.8
# 切換到虛擬環境內
conda activate pyspark
# 在虛擬環境內安裝包
pip install pyhive pyspark jieba -i https://pypi.tuna.tsinghua.edu.cn/simple
通過pycharm寫代碼:
# coding:utf8
from pyspark import SparkConf, SparkContext
import os
os.environ['JAVA_HOME'] = r"C:\Java\jdk1.8.0_201"
os.environ['SPARK_HOME'] = r"D:\spark-3.1.2-bin-hadoop2.7"
os.environ['PYSPARK_PYTHON'] = r"D:\anaconda3\envs\pyspark\python.exe"
os.environ['HADOOP_HOME']=r"D:\hadoop-2.7.7"
if __name__ == '__main__':
conf = SparkConf().setAppName("helloword")
# 通過SparkConf對象構建SparkContext對象
sc = SparkContext(conf=conf)
file_rdd = sc.textFile("./myfile.text")
words_rdd = file_rdd.flatMap(lambda line: line.split(" "))
# 將單詞轉換為元組對象, key是單詞, value是數字1
words_with_one_rdd = words_rdd.map(lambda x: (x, 1))
# 將元組的value 按照key來分組, 對所有的value執行聚合操作(相加)
result_rdd = words_with_one_rdd.reduceByKey(lambda a, b: a + b)
# 通過collect方法收集RDD的數據打印輸出結果
print(result_rdd.collect())
边栏推荐
- Leetcode connected to rainwater series 42 (one dimension) 407 (2D)
- Mysql database operation commands (constantly updated)
- This new change of go 1.16 needs to be adapted: the changes of go get and go install
- Why do some functions in the go standard library have only signatures but no function bodies?
- 存储过程测试入门案例
- Internationalization configuration
- Test instructions - common interface protocol analysis
- In the fragment, the input method is hidden after clicking the confirm cancel button in the alertdialog (this is valid after looking for it on the Internet for a long time)
- c语言语法基础之——指针( 多维数组、函数、总结 ) 学习
- logback
猜你喜欢
![[trajectory planning] testing of ruckig Library](/img/c7/51c0f6dc3bf7c7fa4528118a4c32fa.png)
[trajectory planning] testing of ruckig Library
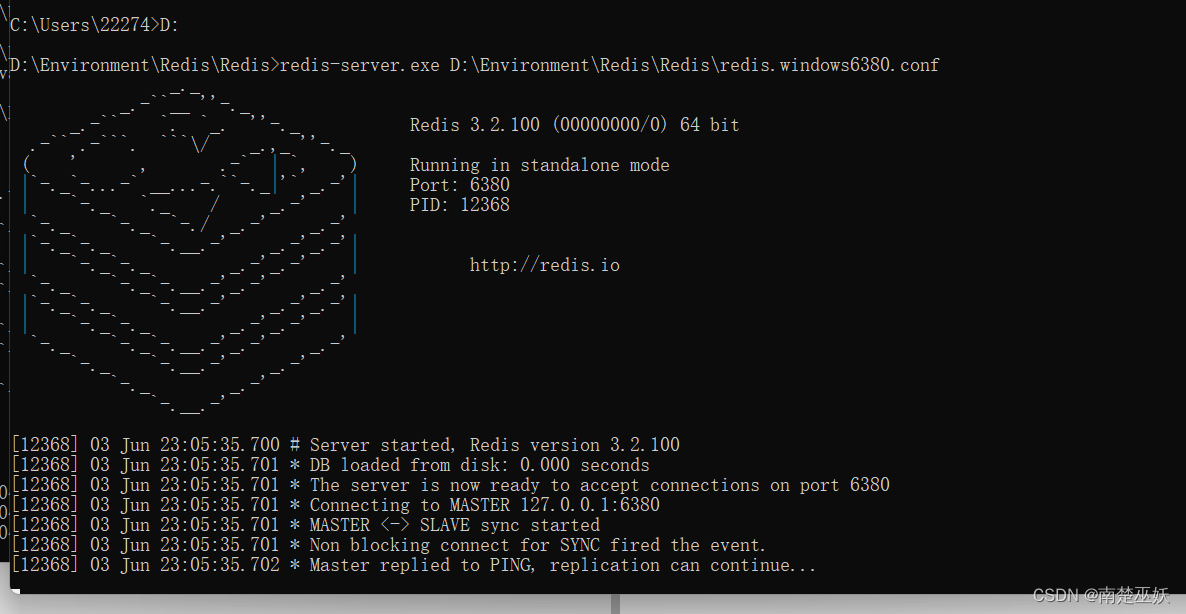
WIN10系统实现Redis主从复制

What you need to know to test -- URL, weak network, interface, automation

字符串常量池、class常量池和运行时常量池

install realsense2: The following packages have unmet dependencies: libgtk-3-dev
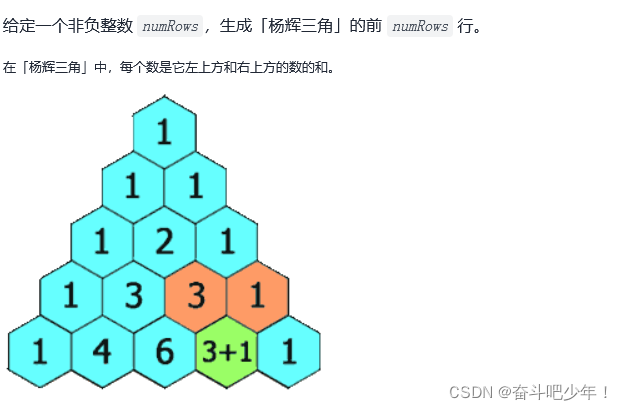
118. 杨辉三角
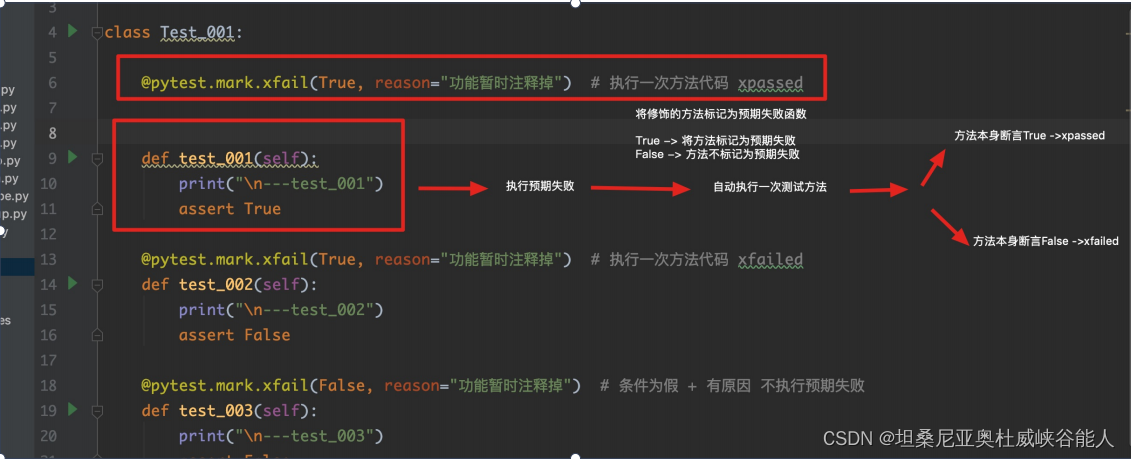
Automated testing -- Introduction and use of pytest itself and third-party modules

Test instructions - common interface protocol analysis

Notes on sports planning on November 22, 2021

Cloud native essay using Hana expression database service on Google kubernetes cluster
随机推荐
Crawler related articles collection: pyppeter, burpsuite
String类intern()方法和字符串常量池
c语言语法基础之——指针( 多维数组、函数、总结 ) 学习
pcl install
Meaning of go runtime
2. 合并两个有序数组
How do technicians send notifications?
c语言语法基础之——函数定义学习
Basic string operations in C
cmake / set 命令
什么是僵尸网络
Glide's most common instructions
Learning and understanding of thread pool (with code examples)
Various errors encountered by tensorflow
[trajectory planning] testing of ruckig Library
Custom interceptor
Nested recyclerview in nestedscrollview automatically slides to the bottom after switching
自动化测试——pytest框架介绍及示例
全渠道、多场景、跨平台,App如何借助数据分析渠道流量
c语言语法基础之——局部变量及存储类别、全局变量及存储类别、宏定义 学习