当前位置:网站首页>Chinese text classification based on CNN
Chinese text classification based on CNN
2022-06-11 20:28:00 【biyezuopinvip】
text-classification-cnn
Using convolutional neural networks (CNN) Dealing with naturallanguageprocessing (NLP) Text classification in . This article will combine TensorFlow Code Introduction :
- Word embedding
- fill
- Embedding
- Convolution layer
- Convolution (tf.nn.conv1d)
- Pooling (pooling)
- Fully connected layer
- dropout
- Output layer
- softmax
File test

Keyboard input test

Network structure and interpretation
The main structure of the network is as follows :
The detailed flow chart of the code is :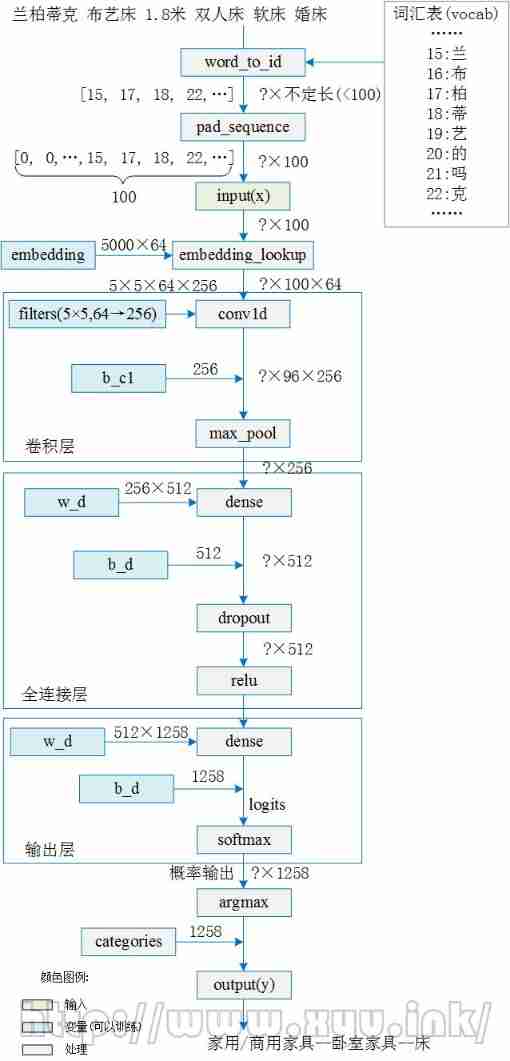
1. word embedding Word vector conversion
This is also NLP The most important step in the task of text classification , Because when we know how to use computers to understand The word vector (word vector) Express Natural language sentences (sequence) when , The text classification problem degenerates into a simple data classification problem , and MNIST There is essentially no difference in classification .
Before we solve this problem , Let's first review how language expresses .
How to express the meaning of a word
Let's first look at how to define “ Meaning ” It means , In English meaning Representing what people or words want to express idea. This is a recursive definition , Estimation query idea A dictionary can use meaning To explain it .
1. Use words 、 Phrases, etc
2. People want to use words 、 Ideas expressed by symbols, etc
3. In writing , The idea expressed in a painting
however , At present, this representation method cannot be applied in computer system processing language .
How the computer processes the meaning of words
The initial word vector is one-hot Vector of form , That is, only the dimension where the word is located is 1, Other dimensions are 0, Vector length and vocabulary (vocab) The same size . As shown in the following table :
| Text | The word vector |
|---|---|
| One | [0,0,0,0,0,0,0,1,0,……,0,0,0,0,0,0,0] |
| individual | [0,0,0,0,0,0,1,0,0,……,0,0,0,0,0,0,0] |
| Small | [0,0,0,0,0,1,0,0,0,……,0,0,0,0,0,0,0] |
| can | [0,0,1,0,0,0,0,0,0,……,0,0,0,0,0,0,0] |
| Love | [0,0,0,1,0,0,0,0,0,……,0,0,0,0,0,0,0] |
The disadvantages of this representation are obvious :
1.** Easy to cause dimensional disaster **. Suppose we want to express 5000 It's a common word , Need to use 5000 The word vector of dimension . If you represent words or idioms, you need a larger word vector .
2. It can not express the semantic relationship between words . The distance between any two words is the same , It is impossible to make words with similar meanings close .
Can we reduce the dimension of word vector ?
Dristributed representation Can solve One hot representation The problem of , The idea is to train , Map each word to a shorter word vector . All these word vectors make up vector space , Then we can use common statistical methods to study the relationship between words . How big is this shorter word vector dimension ? This generally needs to be specified by ourselves during training .
That is to say Use neural network to train and express itself .
ideally , We can train the words to express as shown in the figure below . however , In fact, in practice, we only need to specify the size of the word vector dimension , During the training I don't know what each dimension means .
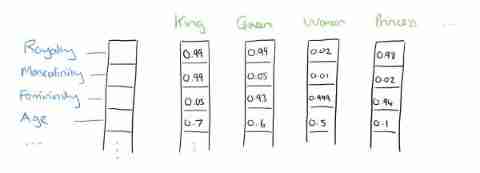
We will king The word sits in space from a vector that can be very sparse , Map to the space where the four-dimensional vector is now , The following properties must be satisfied :
(1) This mapping is a singleton ;
(2) The mapped vector does not lose the information contained in the previous vector .
This process is called word embedding( Word embedding ), That is, embedding high-dimensional word vectors into a low-dimensional space .

After a series of operations by our God of dimensionality , It works Dristributed representation A short vector of words , We can easily analyze the relationship between words , For example, we reduce the dimension of words to 2 dimension , There is an interesting study that shows , When we use the word vector below to represent our words , We can find out :
K i n g → − M a n → + W o m a n → = Q u e e n → \overrightarrow{K i n g}-\overrightarrow{M a n}+\overrightarrow{W o m a n}=\overrightarrow{Q u e e n} King−Man+Woman=Queen
Is the learning ability of machine learning also good !

How to deal with the meaning of words
Chinese text Is different from English , Because English words can be easily distinguished by spaces , And Chinese usually needs to be done first participle operation , And then, after the participle words code . Do not participle in advance , Directly encoding Chinese characters is called Character level code .
This article first uses one-hot On the text Character level code , Then the mapping method from high dimension to low dimension is trained by neural network . The detailed steps are :
1. Build a vocabulary (vocab), The glossary is containing input All possible letters 、 Numbers 、 A collection of symbols and Chinese characters ( This article uses vocab The size is 5000).vocab The form of is shown in the following table :
| id | vocabulary |
|---|---|
| … | … |
| 15 | LAN |
| 16 | cloth |
| 17 | Cypress |
| 18 | Tit |
| 19 | art |
| 20 | Of |
| 21 | Do you |
| 22 | g |
| 23 | ( Space ) |
| … | … |
2. Use a vocabulary (vocab) Convert the input text to id The form of the list , The code is :
with open_file(vocab_dir) as fp: # open vocab file
words = [_.strip() for _ in fp.readlines()] # Read words by line , And turn it into a list
word_to_id = dict(zip(words, range(len(words)))) # Combine words with id Combine , And turn it into a dictionary (dict) In the form of
# word_to_id = {' LAN ':15, ' cloth ':16, ' Cypress ':17 ...}
Suppose a text is entered as :
' Lambertic Cloth art bed 1.8 rice Double bed soft bed marriage bed '
```http://www.biyezuopin.vip
Use the vocabulary above (vocab) Turn into id After the form is :
[15, 17, 18, 22, 23, 16, …]
one-hot The coding matrix is :
```text
[ 0, 0, 0, 0, 0, 0, ...]
...
[ 1, 0, 0, 0, 0, 0, ...] # Subscript 15
[ 0, 0, 0, 0, 0, 1, ...]
[ 0, 1, 0, 0, 0, 0, ...]
[ 0, 0, 1, 0, 0, 0, ...]
[ 0, 0, 0, 0, 0, 0, ...]
[ 0, 0, 0, 0, 0, 0, ...] # Subscript 20
[ 0, 0, 0, 0, 0, 0, ...]
[ 0, 0, 0, 1, 0, 0, ...]
[ 0, 0, 0, 0, 1, 0, ...]
...
3. Put text pad Is a fixed length
x_pad = kr.preprocessing.sequence.pad_sequences(data_id, max_length)
here max_length Set to 100, The maximum length of the representative text cannot exceed max_length, Turn into id The list of forms is filled in and becomes Fixed length A list of . fill (pad) The way is in Fill the front with several 0:
[0, 0, 0, 0, 0, ...... ,15, 17, 18, 22, 23, 16, ...] # fill 0 The rear length is max_length
4. Word embedding (embedding)
embedding = tf.get_variable('embedding', [vocab_size, embedding_dim]) #5000×64
embedding_inputs = tf.nn.embedding_lookup(embedding, input_x)
The code above will 5000 dimension one-hot The encoded input text is converted to a lower dimension (embedding_dim dimension ) The use of The set of real Numbers The word vector represented by . In the project code embedding_dim Set to 64, To simplify the problem , Study tf.nn.embedding_lookup Usage of , Let's assume :
embedding_dim = 2 # Suppose the word vector only uses 2 Dimensional real number coding
input_x = [[0, 0, 0, 0, 0, ...... ,15, 17, 18, 22, 23, 16, ...]] # There are two levels of lists , The outer list represents the input statement , Because there is only one statement, the length is 1
embedding = [[0,0], .....( Subscript to be 15)[0.1,1.5], [1.0,0.1], [0.2,0.1], [1.0,0.3], [0.5,0.1], ( Subscript to be 20)[0.3,1.5
embedding Expressed in a table as :
| Subscript | Content |
|---|---|
| 0 | [0.0,0.0] |
| … | … |
| 15 | [0.1,1.5] |
| 16 | [1.0,0.1] |
| 17 | [0.2,0.1] |
| 18 | [1.0,0.3] |
| 19 | [0.5,0.1] |
| 20 | [0.3,1.5] |
| 21 | [0.1,0.6] |
| 22 | [0.4,0.8] |
| 23 | [0.5,0.5] |
| … | … |
Be careful , These parameters are constantly updated during training .
Use the above embedding,tf.nn.embedding_lookup(embedding, input_x) As the result of the :
[[[ 0.0 0.0]
....
[ 0.1 1.5] # 15- LAN
[ 0.2 0.1] # 17- Cypress
[ 1.0 0.3] # 18- Tit
[ 0.4 0.8] # 22- g
[ 0.5 0.5] # 23-( Space )
[ 1.0 0.1] # 16- cloth
...........]]
Also is to input_x from 5000×100 Dimensional one-hot The encoding map is 2×100 The word of the vector ( Each word is mapped to 2 Dimension word vector , The length is 100). The code does not explicitly appear one-hot The coding process , however tf.nn.embedding_lookup Function from embedding To take input_x Specifies the sequence of subscripts , Because the subscript i The range is [0,5000), and embedding[i] It's a 2 Dimension vector , It's equivalent to finishing 5000 dimension (one-hot form ) To 2 The mapping of dimensions , This is the same as proceeding first one-hot The result of code remapping is the same . When embedding The dimensions are n when , Principle and 2 The dimensions are the same , Just replace the array of representations with n dimension .
2. conv1d Convolution
------http://www.biyezuopin.vip
conv = tf.layers.conv1d(embedding_inputs, filters=5, kernel_size=256)
The calculation method of convolution is shown in the figure below :

It is different from the two-dimensional convolution used in image processing , One dimensional convolution is used to process text . As shown in the figure above , Used 256 Convolution kernels , The size of each convolution kernel is 1×5, Convolution kernel on each feature meanwhile Slide to the right , The calculation method is the sum of the convolution of the feature of each dimension and the convolution kernel plus the offset ( See the red area in the figure ). It can be seen that The distance between two words in a sentence exceeds 5 when , Will not be computed in a convolution kernel , That is, the relevance between them will not be considered , This is also CNN The limitations of dealing with text , Use LSTM This deficiency can be improved .
3. max_pool Maximum pooling
max_pool = tf.reduce_max(conv, reduction_indices=[1])
In the process of convolution , The length is 5 The length of the convolution kernel is 100 Slide on the text of , The resulting 96 The output values , Because of 256 Convolution kernels , The final output size after convolution is 96×256.
A simplified maximum pooling is used in the code , to 96 Outputs are directly maximized ( Instead of using pooled window sliding ), The output size after pooling is 256.
4. dense Full connection layer and output Output layer
fc = tf.layers.dense(max_pool , units=512)
fc = tf.contrib.layers.dropout(fc, self.keep_prob)
fc = tf.nn.relu(fc)
logits = tf.layers.dense(fc, units=num_classes)
y = tf.nn.softmax(self.logits) # Probability output
y_pred_cls = tf.argmax(y, 1) # Index of forecast categories
The full connection layer will 256 The intermediate feature of dimension is transformed into 512 Dimensional , The output layer is further converted to 1258 Probability output of two categories . The subscript with the highest probability is the category of prediction , Last in categories Find the category output corresponding to the subscript in , You can get the predicted results .
End of the flower ~~

边栏推荐
- In 2021, the global cement and aggregate revenue will be about USD 204320 million, and it is expected to reach USD 242670 million in 2028
- RTL arbiter design
- STL容器嵌套容器
- WR | effect of micro nano plastic pollution in Jufeng formation of West Lake University on microbial flora and nitrogen removal function of Constructed Wetland
- Windows icon display exception resolution. The desktop icon is abnormal, the start menu icon is abnormal, and the taskbar icon is abnormal. Icon cache location.
- Ora-01089 ora-19809 ora-19815 exceeded the limit for recovering files
- Detailed explanation on persistence of 2022redis7.0x
- Text to speech small software
- VS2010 cannot open when linking sql2008 database
- Chrome V8 source code 48 The secret of weak type addition,'+'source code analysis
猜你喜欢

秀创意,赢显卡!MMPose姿态估计创意大赛震撼来袭

Black circle display implementation

In 2021, the global barite product revenue was about $571.3 million, and it is expected to reach $710.2 million in 2028

电源防反接和防倒灌 - 使用MOS 管和运放实现理想二极管

2022年最新宁夏建筑八大员(标准员)考试试题及答案

A brief talk on shutter button

Detailed explanation on persistence of 2022redis7.0x

28. JS implementation mechanism

Database introduction

10 R vector operation construction
随机推荐
Object storage of CEPH distributed storage
Simulate Oracle lock waiting and manual unlocking
Power supply anti reverse connection and anti backflow - use MOS tube and op amp to realize ideal diode
A Mechanics-Informed Artificial Neural Network Approach in Data-Driven Constitutive Modeling 学习
Ora-01089 ora-19809 ora-19815 exceeded the limit for recovering files
A mechanics informed artistic neural network approach in data driven constructive modeling
In 2021, the global revenue of minoxidil will be about 1035million US dollars, and it is expected to reach 1372.6 million US dollars in 2028
ORA-01089 ORA-19809 ORA-19815 超过了恢复文件的限制
Show your creativity and win the graphics card! Mmpose attitude estimation creative contest shocks
In 2021, the global adult diaper revenue was about $11560million, which is expected to reach $15440million in 2028. From 2022 to 2028, the CAGR was 4.2%
接口隔离原则
In 2021, the global revenue of flexible fireproof sealant is about 755.2 million dollars, and it is expected to reach 1211.7 million dollars in 2028
moderlarts第二次作业
C#深拷贝
Edit the project steps to run QT and opencv in the clion
2022-2028 global and Chinese thermopile and microbolometer infrared detector Market Status and future development trend
Final examination of Dialectics of nature 1
Oracle case: ora-00600: internal error code, arguments: [4187]
Date of SQL optimization_ Format() function
Wechat applet | rotation chart