当前位置:网站首页>Implementation and landing of any to any real-time voice change RTC dev Meetup
Implementation and landing of any to any real-time voice change RTC dev Meetup
2022-06-21 16:12:00 【Acoustic network】
Preface
「 Voice Processing 」 It is a very important scene in the field of real-time interaction , stay 「RTC Dev Meetup Technical practice and application of voice processing in the field of real-time interaction 」 In the activity , From the sound network 、 Technical experts from Microsoft and Sumi , Relevant sharing was conducted around this topic .
This paper is based on fengjianyuan, an audio experience algorithm expert of the sound network, who shares and sorts out the content in the activity . Official account 「 Sound network developer 」, Reply key words 「DM0428」 You can download activity related PPT Information .

01 The dilemma of real-time voice change algorithm based on traditional sound effects
1、 What does sound change

■ chart 1
To recognize a person by pronunciation , There are many dimensions to consider .
First , Everyone's pronunciation cavity is different , The opening and closing of the mouth and the vibration of the vocal cords in the throat , There may be differences in individual acoustics , This leads to the fact that everyone's pronunciation has a different timbre , On this basis, use language to express , It is possible to produce different rhythms ; secondly , Everyone is in a different room , It may also be accompanied by different reverberation , Impact on identification ; Besides , Sometimes I sing by changing my voice , It may also require musical instrument coordination and some musical theory knowledge .
and , When we perceive sound , It will also be affected by psychology , The same voice , Some people may feel magnetic , But some people may find it rough . Psychological perception varies according to personal experience , There will be some differences .
2、 Why do people have different timbres
So in real time , How to change the sound in real time ? When the rhythm is long , Although we can't change the choice of words and sentences , But it can change the timbre of the pronunciation cavity , Because it requires high real-time performance .
for instance , such as “ What's the date today ” In a word , You can break these words into phonemes , such as “ today ” It can be disassembled into “J” and “in” These two phonemes , It is a voiced sound , Sound can be produced by vocal cord vibration , At this time, everyone's voice color is quite different ; and “ yes ” It's a voiceless sound , Through the air flow form of lips and teeth , For this word , Everyone's timbre has little difference . Why is that ?

■ chart 2
In essence , The vibration frequency of the vocal cord determines the pitch of the pronunciation . Different people make the same sound through different vocal cord vibration frequencies , Its timbre will be very different in voiced sound . Take the example above ,“ What's the date today ” This a few word , Different people may have different pronunciation , and “ yes ” The difference may be small .
The traditional transformation algorithm is also considered from this point of view , Different people have different fundamental frequencies , According to the frequency of vocal cord vibration , The distribution of fundamental frequency can be adjusted . Different fundamental frequencies have different harmonics , Harmonics are multiples of the fundamental frequency . In this way, you can change the sound by changing the tone .

■ chart 3
When making different sounds , The opening and closing of the mouth determines the resonance of the pronunciation cavity , The different opening and closing degree will lead to the enhancement or weakening of different frequency responses , If it reaches the same frequency as the resonance frequency of the mouth , The frequency band will be enhanced , Difference is weakened . This is the principle of formant . From the perspective of voiced sound , Vocal cord vibration produces fundamental frequency , The fundamental frequency will have corresponding harmonics , The distribution of harmonics at different frequencies is determined by the opening and closing of the cavity . such , Changing the distribution of fundamental frequency and frequency response can adjust the timbre .
3、 Sound change based on traditional sound effects
The traditional algorithm is to adjust different pronunciation dimensions through different effectors , chart 4 Shown is the effector commonly used in traditional algorithms , For example, tone sandhi , Now most of the tone changing algorithms are through pitch shifting Extend the fundamental frequency and harmonic upward or downward . under these circumstances ,shift Operation will change the formant at the same time , Make the sound move up or down according to the energy of the spectrum , So as to change people's fundamental frequency .
The fundamental frequency of girls is relatively high , The fundamental frequency of boys is relatively low , By this method, the fundamental frequency direction of both can be consistent . But the opening and closing of the oral cavity when men and women pronounce will also change with the change of words , Just changing the fundamental frequency can not achieve perfect sound transformation . Like movies 《 Despicable Me 》, One of the little yellow people speaks Spanish , As the fundamental frequency is raised, it becomes a child's voice , But it's not natural , Equalizer adjustment is also required .
The previous example only changes the fundamental frequency when changing the tone , In fact, formant and frequency response can be adjusted by equalizer or formant filter , These are also the key modules to adjust the timbre . in addition , People who have been trained in Bel Canto are singing or talking , There are many high-frequency sounds , The pronunciation is full , From this perspective , Its harmonics can be enhanced by an exciter .

■ chart 4
Most of the traditional algorithms are through the serial link of effectors , Change the sound from different dimensions . Commonly used effector software includes MorphVOX PRO perhaps voicemod, They have different effectors , By adjusting the parameters, different character characteristics can be generated . Choosing sound effect is actually the superposition of different effects , Everyone's voice turns out to be different , Because the basic position is different , So it's hard to make everyone's voice the same , But you can make directional adjustments .
I use MorphVOX The software changes from male to female or from female to male , When the male voice becomes the female voice , If you use the default options to adjust, you will feel like a little yellow man . If you change a female voice into a male voice , I found that the voice sounded a little silly , For example, the nasal sound is heavier . This happens because the female voice needs to be lowered when it becomes a male voice , Compress the entire spectrum down , In this way, a lot of high-frequency information is lost .
so , Traditional effectors have their own defects , Cause the change to be less accurate . To get a better sound , The traditional link mode requires manual parameter change , Unable to achieve accurate timbre transformation , If only the preset values are used for adjustment , The effect of timbre transformation is not ideal . in addition , It's hard for everyone's voice to become another designated person , Only a professional tuner can do it .
02 ASR+TTS=VC? be based on AI Explore the possibility of real-time sound change
1、ASR
Traditional voice changing has many limitations , Then based on AI Can we improve the real-time sound change effect by using the method of ? We know ,ASR Technology can realize the function of voice to text , In fact, when changing the sound , Semantic information also needs to be preserved , Only the overall adjustment may lead to missing words or wrong meanings .
Pictured 5 Shown , There are many recognition frameworks , such as hybrid( frame ) Of Kaldi etc. , This kind of frame will pass through the acoustic model 、 Pronunciation dictionary and language model can comprehensively judge the sound conversion , The two conditions of correct pronunciation and reasonable language should be met at the same time .

■ chart 5
From this perspective , It is a link with strong explanation , It is also easy to build , Because there are many ready-made pronunciation dictionaries 、 The language model can use . It also has some disadvantages , The decoding process is complicated , This framework contains multiple models , If one of them has a problem , Then there will be deviation in the identification .
To solve this problem, many end-to-end speech recognition frameworks have emerged , such as Espnet, Its accuracy is from the perspective of general model , With enough data , It's better than hybrid Better recognition . And the training process is relatively simple , Unlike hybrid frame , Need to train acoustic models 、 Language model , Then decode . This framework requires only voice and text data pairing , Then you can do end-to-end training directly . But its shortcomings are also obvious , Because of the end-to-end training , So its requirements are higher , Larger training sets and more accurate annotation are needed . in addition , Different scenarios may need to be customized , More data required , If it is an end-to-end model , There may be no better corpus for training .
At present, from the perspective of sound change , You don't have to recognize text , As long as the phoneme is recognized accurately , This is the ASR The difference between models .
2、TTS
ASR Can recognize pronunciation , So the same sound , Sent by different people , It needs to be used TTS. For this point , There are also many ready-made frameworks that can be used , The process is nothing more than to ASR The extracted text is normalized , Then perform spectrum prediction , And then generate sound through vocoder , Pictured 6 Shown . Google's Tacontron、 Microsoft Fastspeech Have practiced this function , Able to synthesize speech with low delay . For Graphs 6 For the link ,Fastspeech You can also directly skip the vocoder part and directly generate speech , in other words , This part can be done directly from text to speech end to end Generation . such , combination ASR Add TTS In the form of , You can change the sound .

■ chart 6
TTS The vocoder technology in is actually quite mature , What it does is , Predict speech from a compressed spectrum information , chart 7 Show the different vocoders mushra scores, It can be understood as the naturalness of pronunciation transformation , As a judge of whether the transformation is natural .
We can see , image wnet perhaps wRNN This kind of vocoder based on the main point , Good results have been achieved in speech synthesis , It is not much different from the voice of a real person in terms of naturalness . in addition ,Hifi-GAN perhaps Mel-GAN When the real-time performance is good , Can also achieve similar WaveRNN The effect of . Vocoder technology has developed to the present , It has achieved good speech generation effect , The premise of becoming a sound changing effect device .

■ chart 7
3、VC
adopt ASR+TTS The basic steps of realizing sound conversion in series are shown in the figure 8 Shown ,Speaker A Say a few words , And then through ASR Extract text or phoneme information irrelevant to the speaker , recycling TTS Technology to Speaker B To restore the timbre of , To achieve sound change .
 ■ chart 8
■ chart 8
For this link , If the voice can only change from one person to another , Namely One-to-one In the form of . and ASR In fact, it has nothing to do with the speaker , If this is the case , You can do that Any-to-one. in other words ,ASR Model no matter Speaker Who is it? , Can recognize accurate words , Make everyone become Speaker B. The ultimate goal of changing sound is to become Any-to-any In the form of , That is to say, a model can change anyone's voice into any kind of voice , Expand the sound change ability .
We know , Many end-to-end models , image CycleGAN、StarGAN perhaps VAEGAN etc. , It can realize sound transformation in a finite set , So that the people who concentrate on training can group Mutual conversion in , But this is also the limitation of its design , If you can switch TTS The timbre of , It is possible to solve the customization of sound , Make it anyone's voice . so ,ASR + TTS be equal to VC The theory of is actually realizable .
If you want to become Any-to-any In the form of , Need a shortcut , You can't add every person , Retrain the whole model . This needs to learn from the idea of transferable learning . chart 9 It shows the voice generation method based on transfer learning .

■ chart 9
The idea of transfer learning is , adopt speaker encoder The module performs... On the target voice embedding operation , To extract the characteristics of timbre , Then put the features into the speech generation module synthesizer in , In this way, the speech of different timbres can be generated . This is actually what Google found before , They will speaker encoder Module added TTS in , Different timbre changes can be achieved , When adding new ID, That is, when the speaker , It only needs to recognize the speaker's corpus of one minute or tens of seconds , You can extract speaker Characteristics of , Generate the corresponding voice . This idea is actually the method of transfer learning .
Now there are many different speaker encoding Method , such as I-vector、X-vector、 Google's GE2E (generalized end to end) This main bias loss The designed model , And Chinese ( better ) Of Deep Speaker、 Korean ( better ) Of RawNet etc. . therefore , We can take it apart , except ASR and TTS, Add this speaker encoder Module to adjust , Achieve the target speaker's voice , Achieve Any-to-any 了 .
03 Algorithm implementation of real-time sound changing system
1、 Algorithm framework of real-time sound changing system
Next, let's take a look at how the real-time voice change system is implemented , Pictured 10 Shown , The target speaker's corpus is added to voiceprint recognition (speaker encoding part ), Get voiceprint features , At the same time, the phoneme features are extracted through the speech recognition module . Then in the spectrum conversion module , Generate spectrum features , Then get the voice through the vocoder .
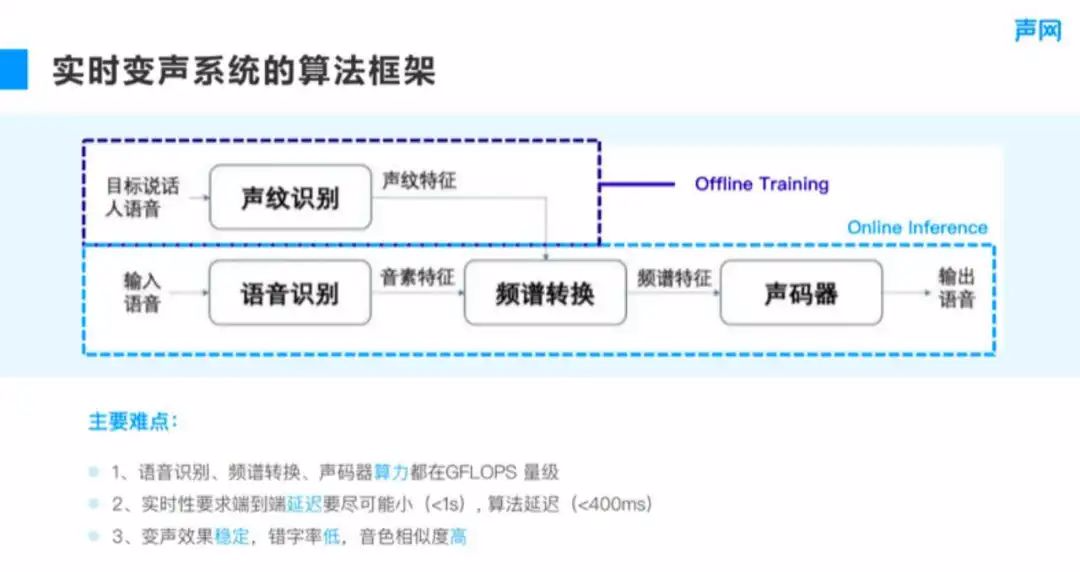
■ chart 10
In fact, the whole process exists offline and online The difference between , The voiceprint recognition module can be realized through offline training Realization . The main difficulty here is :
① Real time voice change should consider the computational power and real-time performance . Even in terms of force , speech recognition 、 Spectrum conversion and vocoder , Even with the fastest algorithm in the industry , Its calculating power is also GFLOPS Magnitude , If it is deployed on the mobile phone , It may not be possible to achieve , But it can be realized on the server .
② In terms of real-time , In real-time communication , If the sound change takes a long time , It may take a long time to react during communication , stay RTC This happens more frequently in the environment . This requires that the end-to-end delay be as small as possible , Generally speaking, it cannot exceed 1 second , If exceeded 1 second , You will feel the obvious delay effect of sound change . Of course , End to end delay also includes encoding and decoding 、 Delay on link such as acquisition and playback , Final , The delay of the whole algorithm cannot be higher than 400 millisecond .
③ To do it Any-to-any Voice change , Whether the sound change effect is stable 、 Whether the error rate is low enough is also a challenging direction . The error rate of speech recognition is 5% It is already a good effect , If you want a lower error rate , You may need a larger model or a more targeted scenario . in addition , The similarity of timbre depends on whether the voiceprint recognition module can accurately extract timbre , This is also a huge challenge .
2、 Real time sound changing system
In fact, different speech recognition frameworks 、 The voiceprint recognition frame and the vocoder frame can be combined freely , Form a complete sound change system . But in order to reduce the algorithm delay to 400 millisecond , The deployment of voiceprint system may be considered more . Pictured 11 The example shown is , When deploying the real-time sound change system , We will consider whether to change the voice in the cloud , It is also implemented on the end side , These two sets of links actually have their own advantages and disadvantages . First, let's look at the advantages and disadvantages of voice change on the cloud .
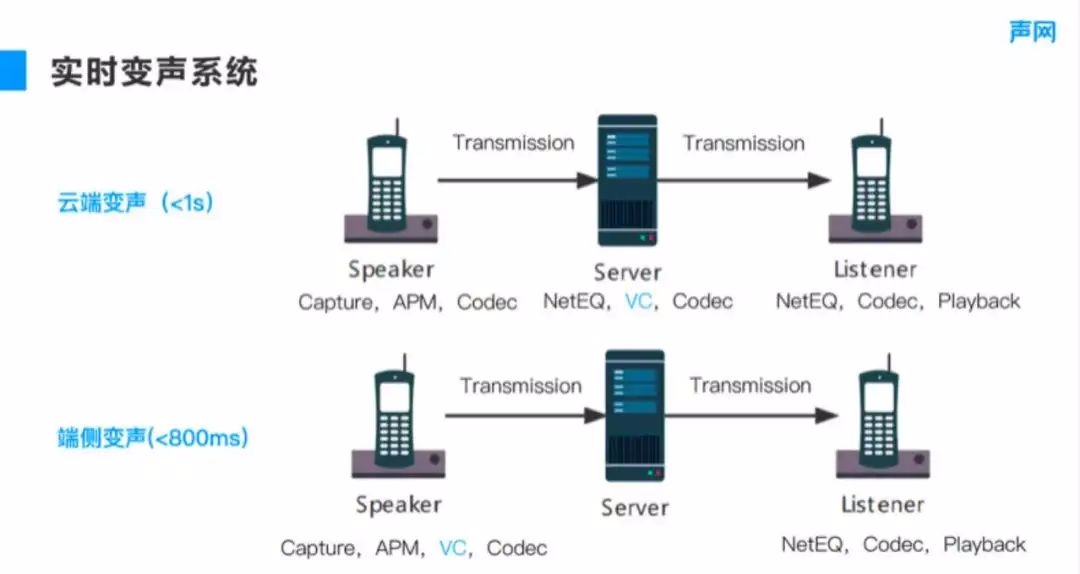
■ chart 11
If you change your voice in the cloud , It needs to be done locally speaker Audio acquisition , And then pass by APM The sound processing module removes noise 、 Echo, etc . Next, we will encode and decode the speech , After the speech is encoded, it will be transmitted to the server for voice change . This is partly due to the impact of the network , May need to introduce NetEQ The module can resist weak network , Decode and then change the sound . The audio after the sound change needs to be encoded and then transmitted listener End ,listener It will also introduce NetEQ The module can resist weak network , Then decode and play .
This type of sound change is more than that realized at the end side NetEQ And the process of encoding and decoding on the server , If there is no weak network , The delay it controls may increase 30~40 millisecond . But if there is a weak network , To prevent packet loss , The delay may reach 100 Milliseconds or 200 millisecond , Even higher .
The advantages of cloud voice change are very obvious , That is, the computing power of voice change on the server is relatively low , At the time of deployment , You can use a better vocoder 、ASR Or spectrum conversion can improve the sound quality through computing power . If it is considered from the end side , You can put the voice change at the sending end , Because there may be more than one receiver , Just make a sound change at the sending end , This eliminates NetEQ and Codec Conversion on the server , The delay on other links is the same as that of cloud deployment . From this point of view , End to end, even if there is no sound change , In general, it can do 400 Millisecond delay , Add the algorithm 400 Millisecond delay , The delay of end-to-side sound change will be less than 800 millisecond , It can greatly reduce the delay consumption in the process of real-time transmission , Make communication more smooth .
End to side sound change is also affected by computational force . Mentioned earlier , The efficiency of the end side is GFLOPS Magnitude , such as iPhone X Or the newer version has GPU Processing chip , In this case, real-time calculation can be realized on the end , But the computational power of the model should not be too great .
04 Demo Presentation and application scenarios

■ chart 12
Next, we will introduce how to change the sound through the link mentioned above Demo The effect of , And its application scenarios .Demo It is a dialogue between men and women . In virtual social networking , In fact, the voice is not necessarily consistent with the character itself , For example, girls want to express themselves in the image of boys , If the sound doesn't change , May be inconsistent with the image of boys , Produce gender dislocation . adopt Demo The comparison before and after the sound change shows that , To solve this problem , The sound changing effect can be used to realize the correspondence between the character and the pronunciation . in addition , The conversation just now was not interrupted by the change of voice .
1、 Application scenario of real-time sound change
So what kind of scene will sound change be used in ? In fact, whether it is in Yuan language chat MetaChat scene , Or in the traditional live chat , There's a place to use . For example, when chatting , You may need to customize the avatar , Including changing the image or sound , To enhance immersion . If you are a cute girl , But with a thick voice , It may be recognized soon . Another example is in the game , If you can use the target's voice , There will be more sense of substitution .
in addition , Now there are many scenes of virtual digital human , Many stars will live by customizing their own virtual images , You don't need to enter the live studio by yourself , Others can be normalized through the background simulation 24 Hours of live . The representative of the chat room scene is the online script kill , When users perform role deduction , There will be different scenarios , You need to switch between different sound lines , It can be realized by changing the sound .
2、 Better real-time sound changing effect
For the current real-time transformation effect , There are many directions that can be optimized . Here are some examples , You can discuss . First , Mentioned earlier , To ensure real-time performance , It is only adjusted by changing the speaker's voice color , In fact, the similarity of recognition can be improved through the speaker's cadence or the expression of pronunciation emotion . therefore , In the case of meeting the real-time requirements , More exploration is possible , Put the expressed features more into the sound changing effect .
secondly , In the case of vocoders , Need less computational power and better results . In fact, today's vocoders , In terms of naturalness , Has been able to perform well , But for the point by point vocoder , There are still big challenges in computing power . Therefore, the computational power and effect need to be balanced , And a more suitable vocoder is obtained on the basis of equalization .
in addition , More robust phoneme extraction module is also a problem at present ASR A big problem in speech recognition . In noisy or complex scenes , There are other voices besides the human voice , This will affect the effect of speech recognition . In this case , Noise reduction module can be introduced to extract human voice , We can also develop a phoneme extraction module that is more robust to noise , Make it recognize the human voice in the noise . When we communicate , Whether it's ASR Or change the sound , You may also encounter multilingual problems , For example, Chinese is mixed with English , Even quote Japanese and so on , under these circumstances , There will be the problem of multilingual recognition , That is to say code-switch, There is no perfect solution to this problem , It is the direction that can be improved in the future .
Last , Hardware determines how complex the upper limit of the model that can be deployed . If there is better hardware on the end for deployment , It can reduce the end-to-end delay and achieve better sound change effect . This is also a direction that needs attention in the future .
05 Q & A
1、 For real-time voice change, what methods can effectively reduce the delay ?
We are doing real-time voice change , Especially when interaction is still needed , First , It is best to deploy on the cloud , This can reduce the delay when the server is transmitting and resisting the weak network . secondly , While doing the algorithm , Such as real-time streaming ASR There will be lookahead, For example, we need to watch more frames in the future , To ensure its recognition accuracy . For this part , Whether it's ASR、TTS Or spectrum conversion , All need to be controlled lookahead Of The amount , So that it can guarantee real-time performance at the same time , So as not to have too much impact on the effect . In practice , It can control the overall algorithm delay to 400 Within milliseconds , It is divided into each module , I think it's in 100 Millisecond or so .
2、Any-to-any Where can I experience the function of changing sound ? Can I use it personally ?
This part is still in the polishing stage , But we already have demo You can experience it . It will be released in the next few months demo For you to experience .
3、 If Xiaobai wants to learn audio systematically , Are there any good learning resources or learning path recommendations ?
I worked with geek time before “ Fix the audio technology ” Column of . I found that in fact, the field of audio may be a little small , But it involves many fields . You can find some resources on the Internet to study systematically , Besides the audio itself , In fact, it also includes audio 3A Handle ( Audio link processing )、 Acoustics and based on AI Technology .
You can first look for relevant information from these perspectives , Learn from each other , The effect will be better .
Activity Notice

「RTC Dev Meetup - Hangzhou station 」, We will focus on big front-end technology , The invitation comes from Acoustic network 、 Ant group and Hikvision Technical experts , Share with us the business architecture and cross end practices in the field of real-time interaction in the era of big front-end .
Action is better than action , Click on here Sign up !
边栏推荐
- The select drop-down box prohibits drop-down and does not affect presentation submission
- 高级性能测试系列《1.思维差异、性能的概念、性能测试》
- Development case of decentralized mining LP liquidity DAPP system
- 这不会又是一个Go的BUG吧?
- PHP code to record the number of visitors
- 依靠可信AI的鲁棒性有效识别深度伪造,帮助银行对抗身份欺诈
- 鹅厂一面,有关 ThreadLocal 的一切
- Go language - Interface
- [number theory] leetcode1006 Clumsy Factorial
- Introduction to lock and initial knowledge of AQS
猜你喜欢

依靠可信AI的鲁棒性有效识别深度伪造,帮助银行对抗身份欺诈

Typescript (6) function

Native JS routing, iframe framework

WDS must know and know

深入理解零拷贝技术

去中心化游戏如何吸引传统玩家?

Goose factory, everything about ThreadLocal
When Huawei order service is called to verify the token interface, connection reset is returned

Set up your own website (4)
原生JS路由,iframe框架
随机推荐
Mid year summary of 33 year old programmer
Selection (038) - what is the output of the following code?
Graph calculation on nlive:nepal's graph calculation practice
2 万字 + 30 张图 | 细聊 MySQL undo log、redo log、binlog 有什么用?
Torch utils. Data: analyze the whole process of data processing
Cvpr2022 | defeat magic with magic, Netease Entertainment AILab new method for image forgery detection to crack forged faces
Kubernetes deployment language
Daily appointment queue assistant | user manual
Blazor overview and routing
【贪心】leetcode1005K次取反后数组后的最大值
WSL 2 的安装过程(以及介绍)
Gmail: how to track message reading status
站在数字化风口,工装企业如何'飞起来'
Score-Based Generative Modeling through Stochastic Differential Equations
WDS must know and know
[redis] string type is basically used
【深度学习】被PyTorch打爆!谷歌抛弃TensorFlow,押宝JAX
Research Report on the overall scale, major manufacturers, major regions, products and application segmentation of floor mounted laboratory centrifuges in the global market in 2022
Research Report on the overall scale, major manufacturers, major regions, products and application segments of twin-screw superchargers in the global market in 2022
When Huawei order service is called to verify the token interface, connection reset is returned