当前位置:网站首页>Some memory problems summarized
Some memory problems summarized
2022-06-30 22:13:00 【Embedded Linux,】

Preface
When I was an intern , Listen to the OOM After sharing , That's right Linux Kernel memory management is of great interest , But this knowledge is huge , Not necessarily accumulated , Dare not write down , Worry about hurting people's children , So after a period of accumulation , After a certain understanding of kernel memory , I only wrote this article today , Share .
This article mainly analyzes the memory layout and allocation of a single process space , It analyzes the memory management of the kernel from a global perspective ;
The following mainly introduces Linux memory management :
Memory application and allocation of process ;
After running out of memory OOM;
Where is the requested memory ?
The system reclaims memory ;
1、 Memory application and allocation of process
Previous article introduction hello world How the program loads memory and how it requests memory , Here again : Again , Let's give the address space of the process first , I think this diagram must be remembered by any developer , Another one is the operation disk ,memory as well as cpu cache Time chart of .

When we start a program at the terminal , Terminal process call exec Function loads the executable into memory , The code snippet appears , Data segment ,bbs paragraph ,stack All paragraphs passed mmap Function maps to memory space , The heap should be mapped according to whether memory is requested on the heap .
exec After performing , The execution process has not really started at this time , It's going to be cpu Control is given to the dynamic link library loader , It loads the dynamic link library required by the process into memory . Then start the execution of the process , This process can be achieved through strace The command traces the system functions called by the process to analyze .

This is recognition pipe Program in , From this output process , It can be seen that it is consistent with my above description .
When the first call malloc When applying for memory , By system call brk Embedded into kernel , First, a judgment will be made , Is there anything about the heap vma, without , Through mmap Anonymously map a piece of memory to the heap , And establish vma structure , Hang up mm_struct Red and black trees on descriptors and linked lists .
Then return to the user state , Via memory allocator (ptmaloc,tcmalloc,jemalloc) The algorithm manages the allocated memory , Return to the memory required by the user .
If large memory is requested in user mode , It's a direct call to mmap Allocate memory , At this time, the memory returned to the user state is still virtual memory , Until the first access to the returned memory , To really allocate memory .
Actually, through brk What is returned is also virtual memory , But after cutting and allocating through the memory allocator ( Cutting must access memory ), All allocated to physical memory
When the process is in user mode, it calls free When freeing memory , If this memory is through mmap Distribute , Call munmap Return directly to the system .
Otherwise, the memory is returned to the memory allocator first , Then the memory allocator returns it to the system , That's why when we call free After reclaiming memory , When accessing this memory again , The reason why the error may not be reported .
Of course , When the whole process exits , The memory occupied by this process will be returned to the system .
2、 After running out of memory OOM
During the internship , There is one on the tester mysql Instances are often oom Kill ,OOM(out of memory) This is the self rescue measure of the system when the memory is exhausted , He will choose a process , Kill it , Free up memory , Obviously , Which process uses the most memory , That is, most likely to be killed , But is it true that ?
Go to work this morning , Just met together OOM, Suddenly found that ,OOM once , The world is quiet , ha-ha , On the test machine redis Was killed .

OOM Key documents oom_kill.c, It introduces when there is not enough memory , How the system selects the process that should be killed most , There are many selection factors , In addition to the memory occupied by the process , And the running time of the process , Priority of the process , Is it root User process , The number of subprocesses, memory occupied and user control parameters oom_adj It's all about .
When there is oom after , function select_bad_process Will traverse all processes , Through the factors mentioned earlier , Each process will get a oom_score fraction , The highest score , Is selected as the process to kill .
We can set /proc/<pid>/oom_adj Score to interfere with the process the system chooses to kill .

This is about this oom_adj Definition of adjustment value , The maximum can be adjusted to 15, The minimum is -16, If -17, Then the process is like buying vip Like members , Will not be expelled and killed by the system , therefore , If there are many servers running on one machine , And you don't want your service to be killed , You can set your own service oom_adj by -17.
Of course , Speaking of this , You have to mention another parameter /proc/sys/vm/overcommit_memory,man proc The explanation is as follows :

It means when overcommit_memory by 0 when , Is heuristic oom, That is, when the applied virtual memory is not exaggerated larger than the physical memory , The system allows you to apply , But when the virtual memory requested by the process is exaggerated to be larger than the physical memory , Then there will be OOM.
For example, only 8g Physical memory , then redis Virtual memory occupied 24G, Physical memory footprint 3g, If you do this bgsave, Child processes and parent processes share physical memory , But virtual memory is its own , That is, the sub process will apply 24g Virtual memory , This is exaggerated, larger than physical memory , Once OOM.
When overcommit_memory by 1 when , Is always allowed overmemory Memory application , That is, no matter how large your virtual memory application is, it is allowed , But when the system runs out of memory , This will happen oom, That is to say redis Example , stay overcommit_memory=1 when , Will not produce oom Of , Because there is enough physical memory .
When overcommit_memory by 2 when , Memory requests that can never exceed a certain limit , The limit is swap+RAM* coefficient (/proc/sys/vm/overcmmit_ratio, Default 50%, You can adjust it yourself ), If so many resources have been used up , Then any subsequent attempt to request memory will return an error , This usually means that no new program can be run at this time
That's all OOM The content of , Understand the principle , And how to use it according to your own application , Reasonable setting OOM.
3、 Where is the memory requested by the system ?
After we know the address space of a process , Would you be curious , Where is the physical memory applied for ? Maybe a lot of people think , Isn't it physical memory ?
I'm here to say where the applied memory is , Because physical memory is divided into cache And general physical memory , Can pass free Command view , And the physical memory has points DMA,NORMAL,HIGH Three districts , Here is the main analysis cache And general memory .
Through the first part , We know that the address space of a process is almost mmap Function request , There are file mapping and anonymous mapping .
3.1 Shared file mapping
Let's first look at the code snippet and the dynamic link library mapping snippet , Both belong to shared file mappings , That is, two processes started by the same executable share these two segments , Are mapped to the same physical memory , So where is this memory ? I wrote a program to test the following :
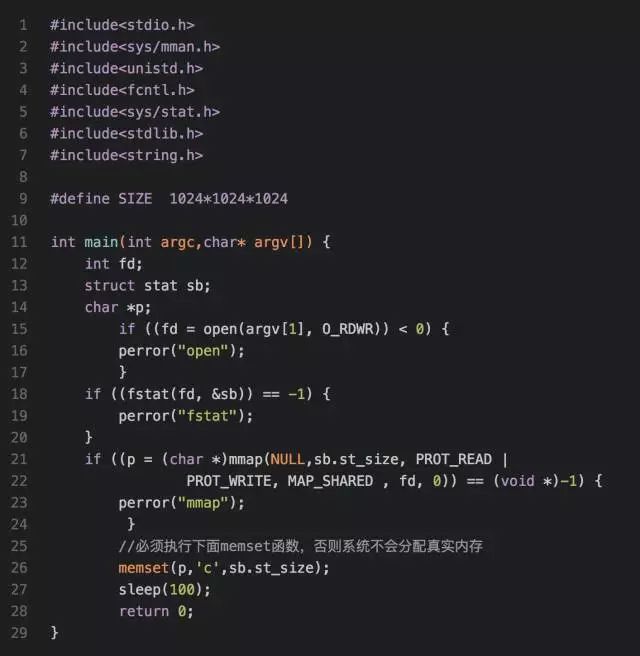
Let's first look at the memory usage of the current system :

When I build a new one locally 1G The file of :
dd if=/dev/zero of=fileblock bs=M count=1024
And then invoke the above procedure. , Share file mapping , At this time, the memory usage is :

We can find out ,buff/cache Increased by about 1G, So we can come to a conclusion , Code snippets and DLL snippets are mapped to the kernel cache in , That is, when performing shared file mapping , The file is read first cache in , Then map to the user process space .
3.2 Private file mapping segment
For data segments in process space , It must be a private file mapping , Because if it's a shared file mapping , Then two processes started by the same executable file , Any process modifies the data segment , Will affect another process , I rewrite the above test program into an anonymous file mapping :

When executing a program , You need to put the previous cache release , Otherwise, it will affect the results
echo 1 >> /proc/sys/vm/drop_caches
Then execute the program , Look at the memory usage :

Compare before and after use , You can find used and buff/cache Respectively increased 1G, When mapping private files , The first is to map files to cache in , Then if a file modifies the file , A piece of memory will be allocated from other memory. First copy the file data to the newly allocated memory , Then modify the newly allocated memory , This is called copy on write .
It's easy to understand , Because if the same executable file opens multiple instances , Then the kernel first maps the executable data segment to cache, Then, if each instance has a modified data segment , A block of memory will be allocated to store data segments , After all, the data segment is also private to a process .
Through the above analysis , We can conclude that , If it's a file map , Is to map the file to cache in , Then different operations are carried out according to whether they are shared or private .
3.3 Private anonymous mapping
image bbs paragraph , Pile up , Stack these are anonymous mappings , Because there is no corresponding segment in the executable , And it must be private mapping , Otherwise, if the current process fork Make a sub process , Then the parent-child processes will share these segments , A change will affect each other , This is not reasonable .
ok, Now I change the above test program to private anonymous mapping

Now let's look at the memory usage

We can see , Only used Added 1G, and buff/cache No growth ; explain , When performing anonymous private mapping , It doesn't take cache, In fact, this makes sense , Because only the current process is using this memory , There is no need to occupy valuable cache.
3.4 Share anonymous mapping
When we need to share memory between parent and child processes , You can use mmap Share anonymous mapping , So where is the memory for sharing anonymous mappings ? I continue to rewrite the above test program to share anonymous mapping .

Now let's take a look at the memory usage :

From the above results , We can see that , Only buff/cache increased 1G, That is, when sharing anonymous mapping , This is from cache Apply for memory in , The reason is also obvious , Because the parent and child processes share this memory , Shared anonymous mapping exists in cache, Then each process maps to each other's virtual memory space , In this way, the same memory can be operated .
4、 The system reclaims memory
When the system is low on memory , There are two ways to free memory , One way is by hand , The other is the memory recovery triggered by the system itself , Let's first look at the manual trigger mode .
4.1 Reclaim memory manually
Reclaim memory manually , It's been demonstrated before , namely
echo 1 >> /proc/sys/vm/drop_caches
We can do it in man proc Here's a brief introduction to this

From this introduction, we can see , When drop_caches File for 1 when , This will release pagecache Releasable part of ( There are some cache Can't be released through this ), When drop_caches by 2 when , This will release dentries and inodes cache , When drop_caches by 3 when , This releases both of the above .
The key is the last sentence , It means if pagecache When there is dirty data in the , operation drop_caches It can't be released , Must pass sync The command flushes dirty data to disk , To pass the operation drop_caches Release pagecache.
ok, I mentioned earlier that some pagecache It can't go through drop_caches Released , In addition to the file mapping and shared anonymous mapping mentioned above , What else exists pagecache 了 ?
4.2 tmpfs
So let's see tmpfs ,tmpfs and procfs,sysfs as well as ramfs equally , Are memory based file systems ,tmpfs and ramfs The difference is that ramfs The file is based on pure memory , and tmpfs In addition to pure memory , And use swap Swap space , as well as ramfs May run out of memory , and tmpfs You can limit the size of memory used , You can use the command df -T -h Look at some file systems , Some of them are tmpfs, The more famous is the directory /dev/shm
tmpfs The file system source file is in the kernel source code mm/shmem.c,tmpfs The implementation is complex , The virtual file system was introduced before , be based on tmpfs File system creates files just like other disk based file systems , There will be inode,super_block,identry,file Isostructure , The difference is mainly in reading and writing , Because reading and writing involves whether the carrier of the file is memory or disk .
and tmpfs File read function shmem_file_read, The process is mainly through inode Structure found address_space address space , In fact, it is the of disk files pagecache, Then locate by reading the offset cache Page and intra page offset .
Then you can directly from this pagecache By function __copy_to_user Copy the data in the cache page to user space , When the data we want to read is not pagecache In the middle of the day , At this time, it is necessary to judge whether it is swap in , If it is in the, first put the memory page swap in, Read again .
tmpfs File write function shmem_file_write, The main process is to determine whether the page to be written is in memory , If in , Then the user status data is directly passed through the function __copy_from_user Copy to kernel pagecache Overwrite old data in , And marked as dirty.
If the data to be written is no longer in memory , Then judge whether it is in swap in , If in , Read it first , Overwrite old data with new data and mark as dirty , If it's not in memory or on disk , Then a new pagecache Store user data .
From the above analysis , We know that based on tmpfs The file is also used cache Of , We can do it in /dev/shm Create a file to detect :

See? ,cache increased 1G, Verified tmpfs It is cache Memory .
Actually mmap The anonymous mapping principle is also used tmpfs, stay mm/mmap.c->do_mmap_pgoff Internal function , There is judgment if file Structure is empty and SHARED mapping , Call shmem_zero_setup(vma) Function in tmpfs Create a new file using

This explains why shared anonymous mapped memory is initialized to 0 了 , But we know how to use it mmap The allocated memory is initialized to 0, That is to say mmap Private anonymous mapping is also 0, So where is it ?
This is in do_mmap_pgoff The function is not reflected inside , But in the missing page exception , Then assign a special initialization to 0 Page of .
So this tmpfs Can the occupied memory pages be recycled ?

in other words tmpfs Document possession pagecache It can't be recycled , The reason is also obvious , Because there are documents that reference these pages , You can't recycle it .
4.3 Shared memory
posix Shared memory and mmap Shared mapping is the same thing , It's all used in tmpfs Create a new file on the file system , Then map to the user state , The last two processes operate on the same physical memory , that System V Whether shared memory is also used tmpfs File system ?
We can trace the following functions

This function is to create a new shared memory segment , The function
shmem_kernel_file_setup
Is in the tmpfs Create a file on the file system , Then process communication is realized through this memory file , I won't write the test program , And it can't be recycled , Because shared memory ipc The mechanism life cycle varies with the kernel , That is, after you create shared memory , If the deletion is not displayed , After the process exits , Shared memory still exists .
I read some technical blogs before , Speaking of Poxic and System V Two sets ipc Mechanism ( Message queue , Semaphores and shared memory ) Is to use tmpfs file system , In other words, the final memory usage is pagecache, But I see in the source code that the two shared memories are based on tmpfs file system , Other semaphores and message queues haven't been seen yet ( To be further studied ).
posix The implementation of message queuing is a bit similar to pipe The implementation of the , It's also my own set mqueue file system , And then in inode Upper i_private Hang up the properties about message queue mqueue_inode_info, On this property , kernel 2.6 when , Is to use an array to store messages , And by the 4.6 A red black tree is used to store messages ( I downloaded both versions , When to start using red and black trees , I didn't go into it ).
Then the two processes operate this every time mqueue_inode_info Message array or red black tree in , Implement process communication , And this mqueue_inode_info Similar to that tmpfs File system properties shmem_inode_info And for epoll Service file system eventloop, There is also a special attribute struct eventpoll, This is hanging on the file Structural private_data wait .
Speaking of this , You can summarize , Code snippets in process space , Data segment , Dynamic link library ( Shared file mapping ),mmap Shared anonymous mappings exist in cache in , But these memory pages are referenced by the process , So it can't be released , be based on tmpfs Of ipc The life cycle of interprocess communication mechanism varies with the kernel , Therefore, it can not be passed drop_caches Release .
Although mentioned above cache Can't release , But it's mentioned later , When out of memory , This memory is OK swap out Of .
therefore drop_caches What can be released is the cache page when reading a file from disk and after a process maps a file to memory , Process exits , At this time, if the cache page of the mapping file is not referenced , It can also be released .
4.4 Automatic memory release mode
When the system is out of memory , The operating system has a set of self-organizing memory , And free the memory mechanism as much as possible , If this mechanism does not free enough memory , Then only OOM 了 .
I mentioned before OOM when , Say redis because OOM Be killed , as follows :

Second half of the second sentence ,
total-vm:186660kB, anon-rss:9388kB, file-rss:4kB
The memory usage of a process , Described with three attributes , That is, all virtual memory , Resident memory anonymous mapping page and resident memory file mapping page .
In fact, from the above analysis , We can also know that a process is actually file mapping and anonymous mapping :
File mapping : Code segment , Data segment , Dynamic link library shared storage segment and file mapping segment of user program ;
Anonymous mapping :bbs paragraph , Pile up , And when malloc use mmap Allocated memory , also mmap Shared memory segment ;
In fact, the kernel reclaims memory according to file mapping and anonymous mapping , stay mmzone.h It has the following definition :

LRU_UNEVICTABLE This is the non expulsion page lru, My understanding is when calling mlock Lock memory , Don't let the system swap out List of outgoing pages .
Under the simple said linux Principle of kernel automatic memory recovery , The kernel has a kswapd Periodically check the memory usage , If free memory is found pages_low, be kswapd Would be right lru_list The first four lru Scan queue , Find inactive pages in the active linked list , And add inactive linked list .
Then traverse the inactive linked list , Recycle one by one and release 32 A page , know free page The number of pages_high, For different pages , Recycling methods are also different .
Of course , When the memory level is below a certain threshold , Memory reclamation is issued directly , The principle and kswapd equally , But this time the recycling effort is greater , More memory needs to be reclaimed .
Document page :
If it's dirty , Write back directly to disk , Reclaim memory .
If it's not a dirty page , Direct release and recovery , Because if it is io Read cache , Release directly , Next time you read , Page missing exception , Read it directly to the disk , If it is a file mapping page , Release directly , On next visit , It also generates two page missing exceptions , Read the contents of the file into the disk at one time , Another time associated with process virtual memory .
Anonymous page : Because anonymous pages have no place to write back , If you release , Then you can't find the data , So the recycling of anonymous pages is swap out To disk , And make a mark on the page table item , The next page missing exception is from the disk swap in Into memory .
swap Swapping in and out actually takes up a lot of system IO Of , If the system memory demand suddenly increases rapidly , that cpu Will be io Occupy , The system will jam , As a result, it is unable to provide external services , Therefore, the system provides a parameter , Used to set when memory reclamation occurs , Perform recycling cache and swap Anonymous page , This parameter is :

This means that the higher the value , The more likely you are to use swap Reclaim memory in the same way , The maximum value is 100, If it is set to 0, Use recycling as much as possible cache To free memory .
5、 summary
This article is mainly about linux Memory management related things :
The first is a review of the process address space ;
Secondly, when the process consumes a lot of memory and leads to insufficient memory , There are two ways we can : The first is manual recycling cache; The other is the system background thread swapd Perform memory reclamation .
Finally, when the requested memory is greater than the remaining memory of the system , At this time, only OOM, Kill process , Free memory , From this process , It can be seen that in order to free up enough memory , How hard it is .
author : Luodaowen's private dishes
http://luodw.cc/2016/08/13/linux-cache/

Statement : In this paper, from “ The Internet ”, The copyright belongs to the original author . If there is any infringement , Please contact us for deletion !

边栏推荐
- How to judge whether the JS object is empty
- Niubi | the tools I have treasured for many years have made me free to fish with pay
- 1-12 preliminary understanding of Express
- Mysql:sql overview and database system introduction | dark horse programmer
- 在启牛开的股票账户安全吗?如何申请低佣金的股票账户?
- 1-3 using SQL to manage databases
- 《安富莱嵌入式周报》第270期:2022.06.13--2022.06.19
- 模板方法模式介绍与示例
- Open the jupyter notebook/lab and FAQ & settings on the remote server with the local browser
- [micro service ~nacos] configuration center of Nacos
猜你喜欢

Uniapp life cycle / route jump

5g demand in smart medicine

【BSP视频教程】BSP视频教程第19期:单片机BootLoader的AES加密实战,含上位机和下位机代码全开源(2022-06-26)

Domestic database disorder
![[micro service ~nacos] configuration center of Nacos](/img/c3/9d8fb0fd49a0ebab43ed604f9bd1cc.png)
[micro service ~nacos] configuration center of Nacos

Usbcan analyzer's supporting can and canfd comprehensive test software lkmaster software solves engineers' can bus test problems
![[career planning for Digital IC graduates] Chap.1 overview of IC industry chain and summary of representative enterprises](/img/d3/68c9d40ae6e61efc10aca8bcc1f613.jpg)
[career planning for Digital IC graduates] Chap.1 overview of IC industry chain and summary of representative enterprises

How to realize the center progress bar in wechat applet

部门新来了个阿里25K出来的,让我见识到了什么是天花板

Best wishes for Lao Wu's party
随机推荐
How to use filters in jfinal to monitor Druid for SQL execution?
Nansen复盘加密巨头自救:如何阻止百亿多米诺倾塌
程序员女友给我做了一个疲劳驾驶检测
Docker installing MySQL
Is it difficult to get a certified equipment supervisor? What is the relationship with the supervising engineer?
Best wishes for Lao Wu's party
Ten of the most heart piercing tests / programmer jokes, read the vast crowd, how to find?
机器学习工作要求研究生吗?
阿婆做的臭豆腐
1-11 create online file service
Analysis of doctor Aifen's incident
Gartner focuses on low code development in China how UNIPRO practices "differentiation"
1-17 express Middleware
PyTorch量化实践(2)
Analysis of PostgreSQL storage structure
Pytorch quantitative perception training (qat) steps
MFC interface library bcgcontrolbar v33.0 - desktop alarm window, grid control upgrade, etc
A comprehensive understanding of gout: symptoms, risk factors, pathogenesis and management
A new one from Ali 25K came to the Department, which showed me what the ceiling is
Web APIs comprehensive case -tab column switching - dark horse programmer