当前位置:网站首页>Thesis reading (3) - googlenet of classification
Thesis reading (3) - googlenet of classification
2022-07-28 23:03:00 【leu_ mon】
GoogLeNet
author :Christian Szegedy , Wei Liu
Company :Google Inc.
Time :CVPR,ILSVRC 2014 champion
subject :Going Deeper with Convolutions
Abstract
We are ImageNet Large scale visual recognition challenge 2014(ILSVRC14) A code named Inception Deep convolution neural network structure , The new best results are obtained in classification and detection . The main feature of this architecture is to improve the utilization of computing resources in the network . Through careful manual design , We have increased the depth and breadth of the network while keeping the computing budget unchanged . In order to optimize the quality , The design of the architecture is based on Heb theory and multi-scale processing intuition . We are ILSVRC14 A special case of application in submission is called GoogLeNet, One 22 Layer depth network , Evaluated in classification and detection .
background
The trend of modifying the recent network model is to increase the number and size of layers , Use at the same time dropout To solve the over fitting problem , Convolution network structure has also been successfully applied to downstream tasks such as detection and positioning .
The most direct way to improve the performance of deep neural networks is to increase their size . This includes not only increasing the depth : Number of network layers , It also includes width : Number of units per floor . Both of the above methods have their disadvantages , Larger networks mean more parameters , It's easier to over fit ; It will cause a significant increase in computing resources , But if most weights are close 0, A lot of computing power will be wasted .
The basic way to solve the above two problems is to introduce sparsity and replace the full connection layer with a sparse full connection layer , Even use sparsity in convolution .Arora Their pioneering work shows that if the probability distribution of the data set can be expressed by a large sparse deep neural network , Then the optimal network topology can be constructed layer by layer by analyzing the correlation statistics of the previous layer activation and clustering highly correlated neurons . Unfortunately , When performing numerical calculations on non-uniform sparse data structures , The current computing architecture is very inefficient .
Inception The architecture attempts to approximate Arora The sparse structure of the visual network shown by et al , And through intensive 、 Easily available components to cover hypothetical results . Assume transformation invariance , This means that the network will be based on convolution building blocks , What we need to do is to find the optimal local structure and repeat it in space .
Model
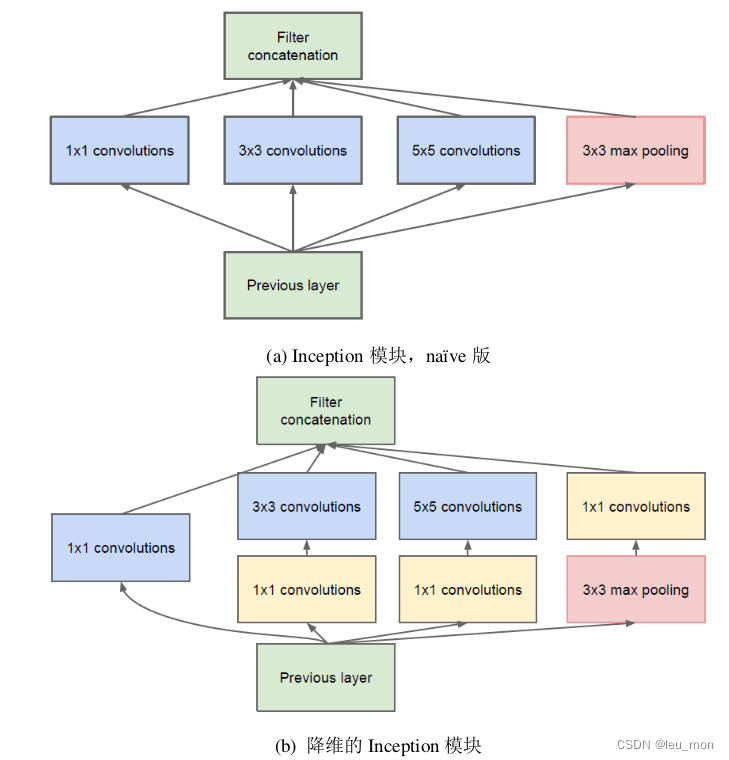
In order to avoid the problem of block correction , at present Inception The size of the filter in the form of architecture is limited to 1×1、3×3、5×5, This is based more on ease of use than necessity . Because pooling operation is very important for the success of convolutional networks , Therefore, an alternative parallel pooling path is added for each such stage , Pictured above (a).
But as the depth of the network increases , Large volume cores will consume a lot of computing resources , Therefore, it is proposed as shown in the figure above (b) Shown , stay 3×3 and 5×5 Before convolution , Use 1×1 Convolution to reduce dimension . A useful aspect of this architecture is that it allows a significant increase in the number of units per phase , There will be no uncontrolled explosion of computational complexity in later stages . The specific network parameters are shown in the table below .
The complete model is shown in the figure below :
- A filter size 5×5, In steps of 3 Average pool layer of ,(4a) The output of stage result is 4×4×512,(4d) The output of stage result is 4×4×528.
- have 128 Filter 1×1 Convolution , Linear activation for dimensionality reduction and correction .
- One has 1024 A fully connected layer of cells and modified linear activation , The discard rate is 70% Of dropout layer .
- Use a softmax Loss of linear layer as classifier ( As the main classifier, it predicts the same 1000 class , But remove when inferring ).

result

Independently trained seven versions of similar GoogLeNet Model ( Including a broader version ), And use them to make an overall prediction , They differ only in sampling method and random input image order . Radical tailoring was used in the test , A picture gets 144 Cut pictures , Too many , Maybe many are unnecessary ,softmax Average on multiple cropped images and all single classifiers , The predicted value is obtained .
The final submission in the competition was obtained on the verification set and the test set top-5 6.67% Error rate , Ranked first among other participants .

The above table shows different cutting quantities , And the error rate comparison under different number of models .
Training & test
- The distributed machine learning system and data parallelism are used to train the network .
- Adopt asynchronous random gradient descent , Momentum is 0.9, Learning rate per 8 individual epoch falling 4%.
- Use Polyak Average is used to create the final model when inferring .
- Image sampling patch Size from image 8% To 100%, The selected aspect ratio is 3/4 To 4/3 Between .
- Andrew Howard The photometric distortion of is conducive to reducing over fitting .
- Use random interpolation method combined with the change of other super parameters to adjust the image size .
- The average pooling layer is used instead of the maximum pooling layer .
Highlights of the article
- be based on Arora The work of others , A model of using network block stacking to fit the visual model of sparse representation is proposed , And achieved good results .
- Use 1*1 The convolution layer is used to reduce the dimension , It can increase the depth of the network .
- Use auxiliary classifiers during training , Make the gradient more effective back propagation to all layers .
Author outlook
- A large number of literatures on sparse matrix multiplication think that for sparse matrix multiplication , Clustering sparse matrices into relatively dense submatrixes will have better performance . Using a similar method to automatically build a non-uniform deep learning architecture .
- Create a more sparse and refined structure fitting in an automated way Arora Sparse network proposed by et al .
边栏推荐
- 【物理应用】水下浮动风力涡轮机的尾流诱导动态模拟风场附matlab代码
- can‘t convert cuda:0 device type tensor to numpy. Use Tensor. cpu() to copy the tensor to host memory
- 【MySQL系列】 MySQL表的增删改查(进阶)
- leetcode 199. 二叉树的右视图
- Yolov5 improvement 12: replace backbone network C3 with lightweight network shufflenetv2
- 记录一下关于三角函数交换积分次序的一道题
- OSV-q grd_ x=grd_ x[:, :, 0:-1, :]-data_ in[:, :, 1:, :]IndexError: too many indices for tensor of d
- 《结构学》介绍
- The US FCC provided us $1.6 billion to support domestic operators to remove Huawei and ZTE equipment
- hp proliant dl380从U盘启动按哪个键
猜你喜欢

无代码开发平台管理后台入门教程

Improvement 17 of yolov5: cnn+transformer -- integrating bottleneck transformers

Paper reading vision gnn: an image is worth graph of nodes

Reading of "robust and communication efficient federated learning from non-i.i.d. data"
Improvement 11 of yolov5: replace backbone network C3 with lightweight network mobilenetv3

xshell7,xftp7个人免费版官方下载,无需破解,免激活,下载即可使用

Introduction to address book export without code development platform
![Stm32f4 serial port burning [flymcu]](/img/5b/0e35c3c58354f911631a3affd3909b.png)
Stm32f4 serial port burning [flymcu]

Shell script foundation - shell operation principle + variable and array definitions
![Draem+sspcab [anomaly detection: block]](/img/97/75ce235c2021b56007eecb82afe4b0.png)
Draem+sspcab [anomaly detection: block]
随机推荐
The simple neural network model based on full connection layer MLP is changed to the model based on CNN convolutional neural network
shell脚本基础——Shell运行原理+变量、数组定义
Wheel 7: TCP client
美国FCC提供16亿美元资助本国运营商移除华为和中兴设备
A new MPLS note from quigo, which must be read when taking the IE exam ---- quigo of Shangwen network
(important) first knowledge of C language -- function
(重要)初识C语言 -- 函数
CGLIb 创建代理
一种分布式深度学习编程新范式:Global Tensor
cannot resize variables that require grad
hp proliant dl380从U盘启动按哪个键
es学习目录
软件测试面试笔试题及答案(软件测试题库)
希捷发布全新RISC-V架构处理器:机械硬盘相关性能暴涨3倍
C语言学习内容总结
LTE cell search process and sch/bch design
歌尔股份与上海泰矽微达成长期合作协议!专用SoC共促TWS耳机发展
cnpm安装步骤
A simple neural network model based on MLP full connection layer
Yolov5 improvement 12: replace backbone network C3 with lightweight network shufflenetv2