当前位置:网站首页>Li Mu D2L (VI) -- model selection
Li Mu D2L (VI) -- model selection
2022-07-26 09:09:00 【madkeyboard】
List of articles
One 、 Model selection
Training error : The error of the model in the training data
The generalization error : Model error on new data
Validation data set : Data set used to evaluate the quality of the model
Test data set : A data set used only once
K- Then cross verify : When there is not enough data to use , The training data can be divided into K block , stay i = (1,2,… ,k) In the cycle of , I want to put number i Block as validation data set , The rest are used as training data sets , Final report K The average of the errors of the verification sets .
Two 、 Over fitting and under fitting

Model capacity : Ability to fit various functions ; Low volume models are difficult to fit training data ; The high-capacity model can remember all the training data .
The model capacity on the left of the figure below is relatively low , Only one straight line can be fitted , The high-capacity model on the right is too complex , Fit in the noise .

Impact of model capacity

VC Dimension is equal to the size of a maximum data set , No matter how the label is given , There is a model for both of them to classify it perfectly .
Support N Dimension input of the perceptron VC Weishi N + 1, Some multi-layer perceptron VC dimension O(NLog2 N)
3、 ... and 、 Code implementation
Use the following third-order polynomials to generate labels for training and test data

import math
import numpy as np
import torch
from torch import nn
from d2l import torch as d2l
import os
os.environ["KMP_DUPLICATE_LIB_OK"]="TRUE"
max_degree = 20 # The eigenvalue
n_train, n_test = 100, 100
true_w = np.zeros(max_degree)
true_w[0:4] = np.array([5, 1.2, -3.4, 5.6]) # This assignment is based on polynomial data
features = np.random.normal(size=(n_train + n_test, 1))
np.random.shuffle(features)
poly_features = np.power(features, np.arange(max_degree).reshape(1, -1))
for i in range(max_degree):
poly_features[:, i] /= math.gamma(i + 1)
labels = np.dot(poly_features, true_w)
labels += np.random.normal(scale=0.1, size=labels.shape)
# Check the first two samples
true_w, features, poly_features, labels = [
torch.tensor(x, dtype=torch.float32)
for x in [true_w, features, poly_features, labels]]
# print(features[:2], poly_features[:2, :], labels[:2])
# Implement a function to evaluate the loss of the model on a given data set
def evaluate_loss(net, data_iter, loss):
metric = d2l.Accumulator(2)
for X, y in data_iter:
out = net(X)
y = y.reshape(out.shape)
l = loss(out, y)
metric.add(l.sum(), l.numel())
return metric[0] / metric[1]
# Define training function
def train(train_features, test_features, train_labels, test_labels,
num_epochs=400):
loss = nn.MSELoss()
input_shape = train_features.shape[-1]
net = nn.Sequential(nn.Linear(input_shape, 1, bias=False))
batch_size = min(10, train_labels.shape[0])
train_iter = d2l.load_array((train_features, train_labels.reshape(-1, 1)),
batch_size)
test_iter = d2l.load_array((test_features, test_labels.reshape(-1, 1)),
batch_size, is_train=False)
trainer = torch.optim.SGD(net.parameters(), lr=0.01)
animator = d2l.Animator(xlabel='epoch', ylabel='loss', yscale='log',
xlim=[1, num_epochs], ylim=[1e-3, 1e2],
legend=['train', 'test'])
for epoch in range(num_epochs):
d2l.train_epoch_ch3(net, train_iter, loss, trainer)
if epoch == 0 or (epoch + 1) % 20 == 0:
animator.add(epoch + 1, (evaluate_loss(
net, train_iter, loss), evaluate_loss(net, test_iter, loss)))
print('weight:', net[0].weight.data.numpy())
# Third order polynomial function fitting ( normal )
train(poly_features[:n_train, :4], poly_features[n_train:, :4],
labels[:n_train], labels[n_train:])
d2l.plt.show()
''' weight: [[ 4.982289 1.1968644 -3.388561 5.612971 ]] '''

Now let's look at the situation of under fitting , Only two features are given , You can see that the final error is very large .
train(poly_features[:n_train, :2], poly_features[n_train:, :2],
labels[:n_train], labels[n_train:])
''' weight: [[3.3086548 5.039875 ]] '''

Let's see fitting again , It's equivalent to giving out the whole data ( A large part of the noise is also given ), And some data will mislead the results . You can see train and test Between gap There is a significant increase .

边栏推荐
- Dynamic SQL and exceptions of pl/sql
- Apple generated and verified tokens for PHP
- CF1481C Fence Painting
- "Could not build the server_names_hash, you should increase server_names_hash_bucket_size: 32"
- 本地缓存
- ES6 modular import and export) (realize page nesting)
- Pop up window in Win 11 opens with a new tab ---firefox
- Pat grade a a1013 battle over cities
- Simple message mechanism of unity
- Laravel框架日志文件存放在哪里?怎么用?
猜你喜欢

187. Repeated DNA sequence

Day 6 summary & database operation

数据库操作 题目二
Pop up window in Win 11 opens with a new tab ---firefox

unity TopDown角色移动控制

Numpy Foundation
Horizontal comparison of the data of the top ten blue chip NFTs in the past half year
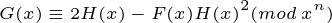
NTT (fast number theory transformation) polynomial inverse 1500 word analysis

ext4文件系统打开了DIR_NLINK特性后,link_count超过65000的后使用link_count=1来表示数量不可知

The child and binary tree- open root inversion of polynomials
随机推荐
基于序的评价指标 (特别针对推荐系统和多标签学习)
李沐d2l(六)---模型选择
The Child and Binary Tree-多项式开根求逆
Overview of motion recognition evaluation
unity简易消息机制
Nuxt - Project packaging deployment and online to server process (SSR server rendering)
Matlab 绘制阴影误差图
Hbuilderx runs the wechat developer tool "fail to open ide" to solve the error
对象型的集合按某个属性的值进行去重
Where are the laravel framework log files stored? How to use it?
Database operation topic 2
CF1481C Fence Painting
JVM触发minor gc的条件
Flask project learning (I) -- sayhello
756. 蛇形矩阵
Day06 homework -- skill question 2
Day06 homework -- skill question 1
at、crontab
力扣题DFS
Zipkin安装和使用