![]()
![]()
Sklearn-genetic-opt
scikit-learn models hyperparameters tuning and feature selection, using evolutionary algorithms.
This is meant to be an alternative to popular methods inside scikit-learn such as Grid Search and Randomized Grid Search for hyperparameteres tuning, and from RFE, Select From Model for feature selection.
Sklearn-genetic-opt uses evolutionary algorithms from the DEAP package to choose the set of hyperparameters that optimizes (max or min) the cross-validation scores, it can be used for both regression and classification problems.
Documentation is available here
Main Features:
- GASearchCV: Main class of the package for hyperparameters tuning, holds the evolutionary cross-validation optimization routine.
- GAFeatureSelectionCV: Main class of the package for feature selection.
- Algorithms: Set of different evolutionary algorithms to use as an optimization procedure.
- Callbacks: Custom evaluation strategies to generate early stopping rules, logging (into TensorBoard, .pkl files, etc) or your custom logic.
- Plots: Generate pre-defined plots to understand the optimization process.
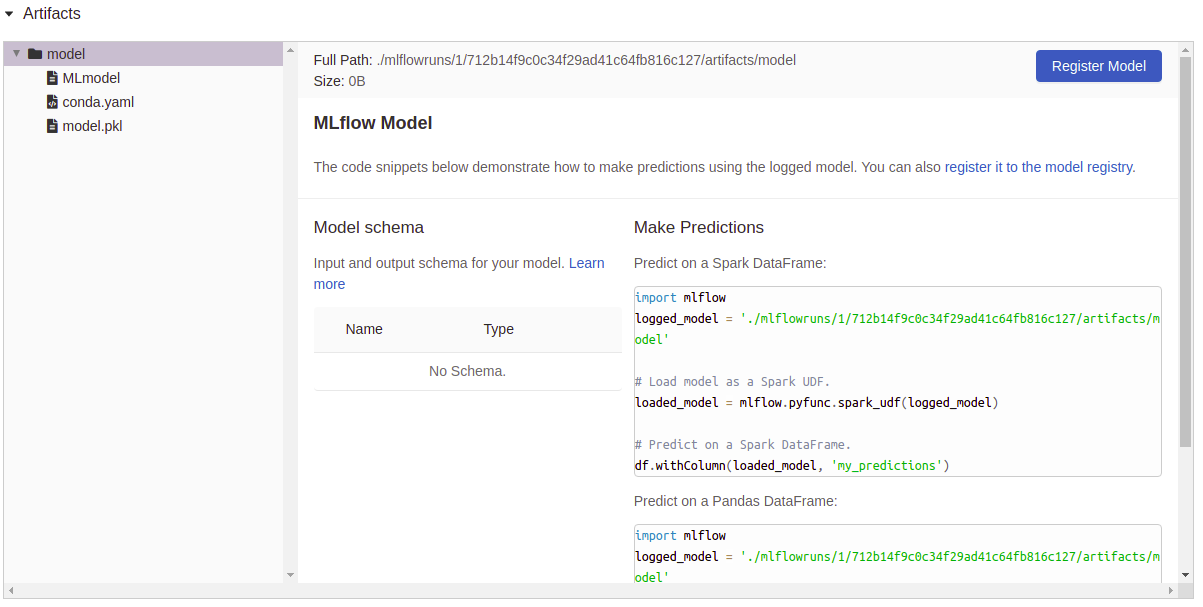
- MLflow: Build-in integration with mlflow to log all the hyperparameters, cv-scores and the fitted models.
Demos on Features:
Visualize the progress of your training:
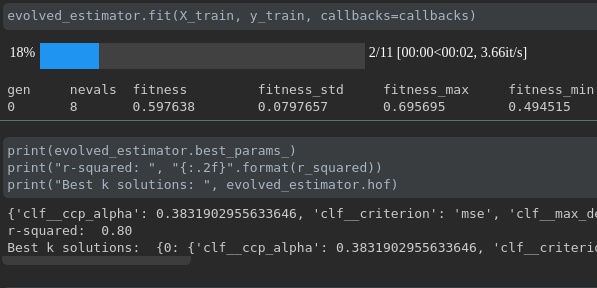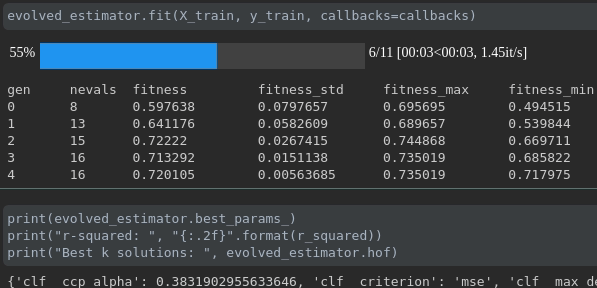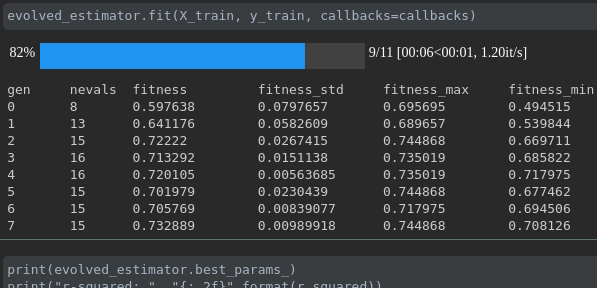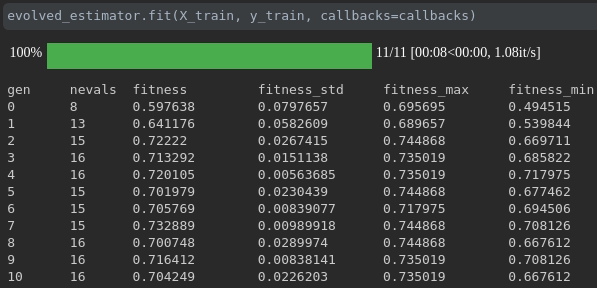
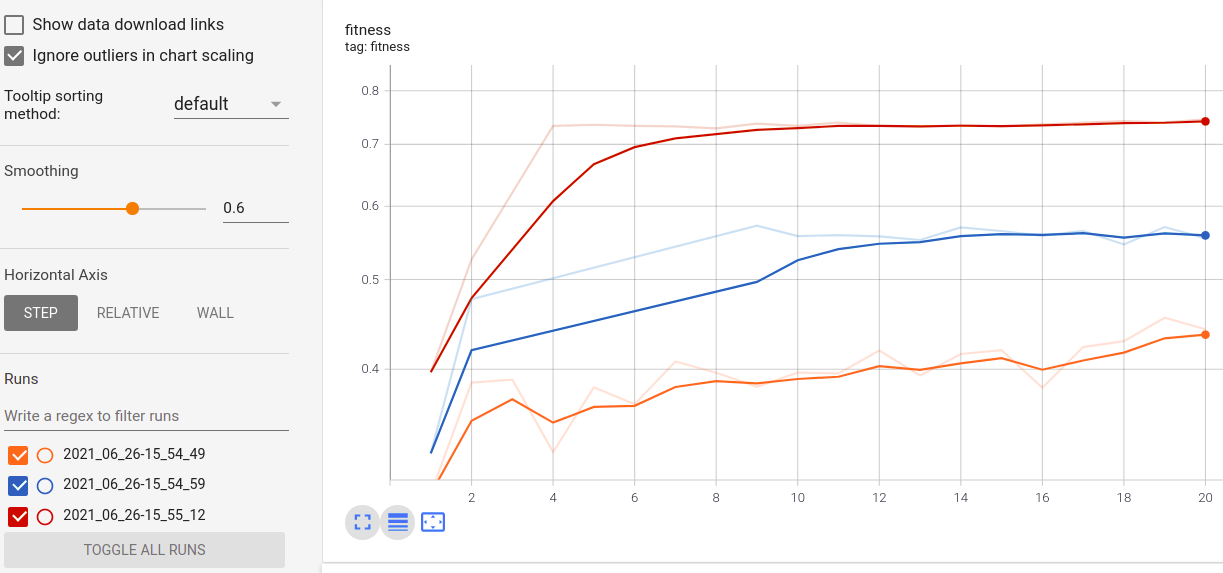
Real-time metrics visualization and comparison across runs:
Sampled distribution of hyperparameters:

Artifacts logging:
Usage:
Install sklearn-genetic-opt
It's advised to install sklearn-genetic using a virtual env, inside the env use:
pip install sklearn-genetic-opt
If you want to get all the features, including plotting and mlflow logging capabilities, install all the extra packages:
pip install sklearn-genetic-opt[all]
The only optional dependency that the last command does not install, it's Tensorflow, it is usually advised to look further which distribution works better for you.
Example: Hyperparameters Tuning
from sklearn_genetic import GASearchCV
from sklearn_genetic.space import Continuous, Categorical, Integer
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split, StratifiedKFold
from sklearn.datasets import load_digits
from sklearn.metrics import accuracy_score
import matplotlib.pyplot as plt
data = load_digits()
n_samples = len(data.images)
X = data.images.reshape((n_samples, -1))
y = data['target']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=42)
clf = RandomForestClassifier()
param_grid = {'min_weight_fraction_leaf': Continuous(0.01, 0.5, distribution='log-uniform'),
'bootstrap': Categorical([True, False]),
'max_depth': Integer(2, 30),
'max_leaf_nodes': Integer(2, 35),
'n_estimators': Integer(100, 300)}
cv = StratifiedKFold(n_splits=3, shuffle=True)
evolved_estimator = GASearchCV(estimator=clf,
cv=cv,
scoring='accuracy',
population_size=10,
generations=35,
param_grid=param_grid,
n_jobs=-1,
verbose=True,
keep_top_k=4)
# Train and optimize the estimator
evolved_estimator.fit(X_train, y_train)
# Best parameters found
print(evolved_estimator.best_params_)
# Use the model fitted with the best parameters
y_predict_ga = evolved_estimator.predict(X_test)
print(accuracy_score(y_test, y_predict_ga))
# Saved metadata for further analysis
print("Stats achieved in each generation: ", evolved_estimator.history)
print("Best k solutions: ", evolved_estimator.hof)
Example: Feature Selection
import matplotlib.pyplot as plt
from sklearn_genetic import GAFeatureSelectionCV
from sklearn.model_selection import train_test_split, StratifiedKFold
from sklearn.svm import SVC
from sklearn.datasets import load_iris
from sklearn.metrics import accuracy_score
import numpy as np
data = load_iris()
X, y = data["data"], data["target"]
# Add random non-important features
noise = np.random.uniform(0, 10, size=(X.shape[0], 5))
X = np.hstack((X, noise))
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=0)
clf = SVC(gamma='auto')
evolved_estimator = GAFeatureSelectionCV(
estimator=clf,
scoring="accuracy",
population_size=30,
generations=20,
n_jobs=-1)
# Train and select the features
evolved_estimator.fit(X_train, y_train)
# Features selected by the algorithm
features = evolved_estimator.best_features_
print(features)
# Predict only with the subset of selected features
y_predict_ga = evolved_estimator.predict(X_test[:, features])
print(accuracy_score(y_test, y_predict_ga))
Changelog
See the changelog for notes on the changes of Sklearn-genetic-opt
Important links
- Official source code repo: https://github.com/rodrigo-arenas/Sklearn-genetic-opt/
- Download releases: https://pypi.org/project/sklearn-genetic-opt/
- Issue tracker: https://github.com/rodrigo-arenas/Sklearn-genetic-opt/issues
- Stable documentation: https://sklearn-genetic-opt.readthedocs.io/en/stable/
Source code
You can check the latest development version with the command:
git clone https://github.com/rodrigo-arenas/Sklearn-genetic-opt.git
Install the development dependencies:
pip install -r dev-requirements.txt
Check the latest in-development documentation: https://sklearn-genetic-opt.readthedocs.io/en/latest/
Contributing
Contributions are more than welcome! There are several opportunities on the ongoing project, so please get in touch if you would like to help out. Make sure to check the current issues and also the Contribution guide.
Big thanks to the people who are helping with this project!
Testing
After installation, you can launch the test suite from outside the source directory:
pytest sklearn_genetic
![[Feature] Parallel Coordinates plot](https://avatars.githubusercontent.com/u/31422766?v=4)
![[FEATURE] Report multiple scoring metrics](https://avatars.githubusercontent.com/u/8134662?v=4)


![change [FEATURE]](https://avatars.githubusercontent.com/u/68053817?v=4)



![[FEATURE] Feature selection and optimization simultaneously](https://avatars.githubusercontent.com/u/888717?v=4)
![[FEATURE]](https://avatars.githubusercontent.com/u/98243108?v=4)

![[FEATURE] Conda package](https://avatars.githubusercontent.com/u/52188949?v=4)


![[FEATURE] Support for XGBoost early stopping](https://avatars.githubusercontent.com/u/11824768?v=4)

 1 Feb 04, 2022
1 Feb 04, 2022
 4.3k Jan 08, 2023
4.3k Jan 08, 2023
 1 Oct 29, 2021
1 Oct 29, 2021
 590 Dec 28, 2022
590 Dec 28, 2022
 0 Jan 20, 2022
0 Jan 20, 2022
 19 Dec 13, 2022
19 Dec 13, 2022
 1 Nov 24, 2021
1 Nov 24, 2021
 1 Nov 21, 2021
1 Nov 21, 2021
 2 Sep 13, 2022
2 Sep 13, 2022
 1 Jan 08, 2022
1 Jan 08, 2022
 8 Jun 07, 2022
8 Jun 07, 2022
 6.7k Jan 08, 2023
6.7k Jan 08, 2023
 47 Dec 30, 2022
47 Dec 30, 2022
 1 Jan 19, 2022
1 Jan 19, 2022
 511 Dec 20, 2022
511 Dec 20, 2022
 2.6k Jan 08, 2023
2.6k Jan 08, 2023
 1 Nov 23, 2021
1 Nov 23, 2021
 552 Dec 27, 2022
552 Dec 27, 2022
 1.7k Jan 04, 2023
1.7k Jan 04, 2023
 203 Dec 26, 2022
203 Dec 26, 2022