当前位置:网站首页>2022cuda summer training camp day3 practice
2022cuda summer training camp day3 practice
2022-07-29 10:27:00 【Hua Weiyun】

2022CUDA Summer training camp Day1 practice https://bbs.huaweicloud.com/blogs/364478
2022CUDA Summer training camp Day2 practice https://bbs.huaweicloud.com/blogs/364479
Today is the third day , The theme is Event,Memory and Shared Memory.
( One )Event
Let's start with the first one ——Event.
Event yes CUDA In the event , Used to analyze 、 testing CUDA Errors in the program .
Generally, we will define a macro :
#pragma once#include <stdio.h>#define CHECK(call) \do \{ \ const cudaError_t error_code = call; \ if (error_code != cudaSuccess) \ { \ printf("CUDA Error:\n"); \ printf(" File: %s\n", __FILE__); \ printf(" Line: %d\n", __LINE__); \ printf(" Error code: %d\n", error_code); \ printf(" Error text: %s\n", \ cudaGetErrorString(error_code)); \ exit(1); \ } \} while (0)And use this macro in the appropriate place to print CUDA Error log for .
notes :#pragma once, Don't put it in the source code file , This is usually only in the header file .( Prevent header files from being introduced multiple times )
The specific call process is as follows :

The specific order is as follows :
(1) Statement Event( Here we calculate the time before and after the kernel function runs start Event and stop Event For example )
cudaEvent_t start, stop;(2) establish Event
CHECK(cudaEventCreate(&start));CHECK(cudaEventCreate(&stop));(3) add to Event( In the right place )
cudaEventRecord(start);cudaEventRecord(stop);(4) wait for Event complete
(a) Non blocking mode —— It can be used for some processing without waiting
cudaEventQuery(start);(b) Blocking mode —— It can be used to wait for the processing after the kernel function is executed
cudaEventSynchronize(stop);(5) Calculate two Event Time interval between
CHECK(cudaEventElapsedTime(&elapsed_time, start, stop));(6) The destruction Event
CHECK(cudaEventDestroy(start));CHECK(cudaEventDestroy(stop));The complete code is as follows :
#pragma once#include <stdio.h>#define CHECK(call) \do \{ \ const cudaError_t error_code = call; \ if (error_code != cudaSuccess) \ { \ printf("CUDA Error:\n"); \ printf(" File: %s\n", __FILE__); \ printf(" Line: %d\n", __LINE__); \ printf(" Error code: %d\n", error_code); \ printf(" Error text: %s\n", \ cudaGetErrorString(error_code)); \ exit(1); \ } \} while (0)#include <stdio.h>#include <math.h>#include "error.cuh"#define BLOCK_SIZE 32__global__ void gpu_matrix_mult(int *a,int *b, int *c, int m, int n, int k){ int row = blockIdx.y * blockDim.y + threadIdx.y; int col = blockIdx.x * blockDim.x + threadIdx.x; int sum = 0; if( col < k && row < m) { for(int i = 0; i < n; i++) { sum += a[row * n + i] * b[i * k + col]; } c[row * k + col] = sum; }} void cpu_matrix_mult(int *h_a, int *h_b, int *h_result, int m, int n, int k) { for (int i = 0; i < m; ++i) { for (int j = 0; j < k; ++j) { int tmp = 0.0; for (int h = 0; h < n; ++h) { tmp += h_a[i * n + h] * h_b[h * k + j]; } h_result[i * k + j] = tmp; } }}int main(int argc, char const *argv[]){ int m=100; int n=100; int k=100; // Statement Event cudaEvent_t start, stop, stop2, stop3 , stop4 ; // establish Event CHECK(cudaEventCreate(&start)); CHECK(cudaEventCreate(&stop)); CHECK(cudaEventCreate(&stop2)); int *h_a, *h_b, *h_c, *h_cc; CHECK(cudaMallocHost((void **) &h_a, sizeof(int)*m*n)); CHECK(cudaMallocHost((void **) &h_b, sizeof(int)*n*k)); CHECK(cudaMallocHost((void **) &h_c, sizeof(int)*m*k)); CHECK(cudaMallocHost((void **) &h_cc, sizeof(int)*m*k)); for (int i = 0; i < m; ++i) { for (int j = 0; j < n; ++j) { h_a[i * n + j] = rand() % 1024; } } for (int i = 0; i < n; ++i) { for (int j = 0; j < k; ++j) { h_b[i * k + j] = rand() % 1024; } } int *d_a, *d_b, *d_c; CHECK(cudaMalloc((void **) &d_a, sizeof(int)*m*n)); CHECK(cudaMalloc((void **) &d_b, sizeof(int)*n*k)); CHECK(cudaMalloc((void **) &d_c, sizeof(int)*m*k)); // copy matrix A and B from host to device memory CHECK(cudaMemcpy(d_a, h_a, sizeof(int)*m*n, cudaMemcpyHostToDevice)); CHECK(cudaMemcpy(d_b, h_b, sizeof(int)*n*k, cudaMemcpyHostToDevice)); unsigned int grid_rows = (m + BLOCK_SIZE - 1) / BLOCK_SIZE; unsigned int grid_cols = (k + BLOCK_SIZE - 1) / BLOCK_SIZE; dim3 dimGrid(grid_cols, grid_rows); dim3 dimBlock(BLOCK_SIZE, BLOCK_SIZE); // Start start Event cudaEventRecord(start); // Non-blocking mode cudaEventQuery(start); //gpu_matrix_mult<<<dimGrid, dimBlock>>>(d_a, d_b, d_c, m, n, k); gpu_matrix_mult_shared<<<dimGrid, dimBlock>>>(d_a, d_b, d_c, m, n, k); // Start stop Event cudaEventRecord(stop); // Because we have to wait for the kernel function to finish executing , So choose blocking mode cudaEventSynchronize(stop); // computing time stop-start float elapsed_time; CHECK(cudaEventElapsedTime(&elapsed_time, start, stop)); printf("start-》stop:Time = %g ms.\n", elapsed_time); cudaMemcpy(h_c, d_c, (sizeof(int)*m*k), cudaMemcpyDeviceToHost); //cudaThreadSynchronize(); // Start stop2 Event CHECK(cudaEventRecord(stop2)); // Non-blocking mode //CHECK(cudaEventSynchronize(stop2)); cudaEventQuery(stop2); // computing time stop-stop2 float elapsed_time2; cudaEventElapsedTime(&elapsed_time2, stop, stop2); printf("stop-》stop2:Time = %g ms.\n", elapsed_time2); // The destruction Event CHECK(cudaEventDestroy(start)); CHECK(cudaEventDestroy(stop)); CHECK(cudaEventDestroy(stop2)); //CPU Function calculation cpu_matrix_mult(h_a, h_b, h_cc, m, n, k); int ok = 1; for (int i = 0; i < m; ++i) { for (int j = 0; j < k; ++j) { if(fabs(h_cc[i*k + j] - h_c[i*k + j])>(1.0e-10)) { ok = 0; } } } if(ok) { printf("Pass!!!\n"); } else { printf("Error!!!\n"); } // free memory cudaFree(d_a); cudaFree(d_b); cudaFree(d_c); cudaFreeHost(h_a); cudaFreeHost(h_b); cudaFreeHost(h_c); return 0;}There will be some warnings when compiling , Don't worry about it. :
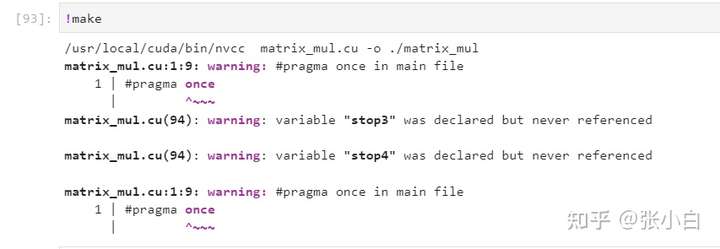
stay Quardo P1000 Of GPU On the implementation :
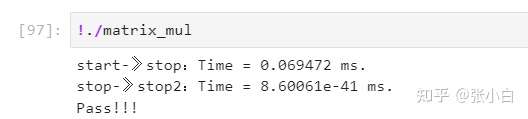
stay Jetson Nano B01 On the implementation :

Here take matrix multiplication as an example , Print the time to call the matrix multiplication kernel function , And the back cudaMemcpy Time for .
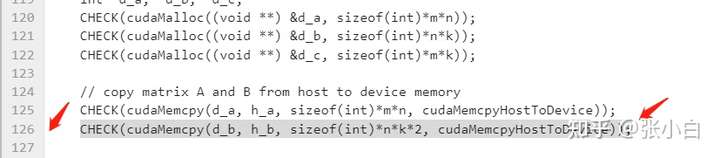
We forced
CHECK(cudaMemcpy(d_b, h_b, sizeof(int)*n*k, cudaMemcpyHostToDevice));Change it to
CHECK(cudaMemcpy(d_b, h_b, sizeof(int)*n*k*2, cudaMemcpyHostToDevice));Deliberately let it out of bounds .
recompile , function , Look at the effect :
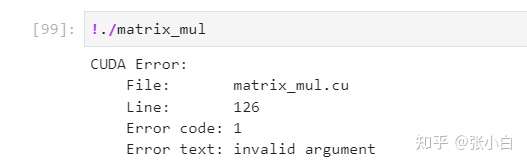
The system will tell you There is something wrong with this line :
In this way, we can track CUDA Error in call .
Here we need to summarize that Zhang Xiaobai is debugging CHECK Several problems found in the process :
(1) without CHECK(cudaEventCreate()) Just call directly cudaEventRecord() Or execute the following Event function , It will result in failure to print information . Zhang Xiaobai was concerned about stop2 This event Just made this mistake , Lead to stop->stop2 I can't find the time .
(2) about cudaEventQuery() You can't add CHECK Of , If it is added, it will report an error :
In the above environment , If you write like this :
CHECK(cudaEventQuery(stop2));The following errors will appear when compiling and executing :
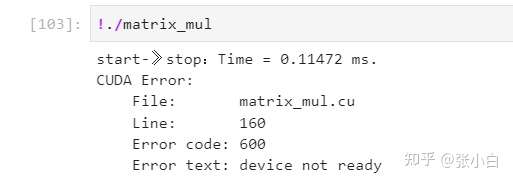
notes :cudaEventQuery Of cudaErrorNotReady It represents that the event has not happened ( Not yet recorded ), It doesn't mean error .
Use Nano Check the performance :
!echo nano | sudo -S /usr/local/cuda/bin/nvprof ./matrix_mul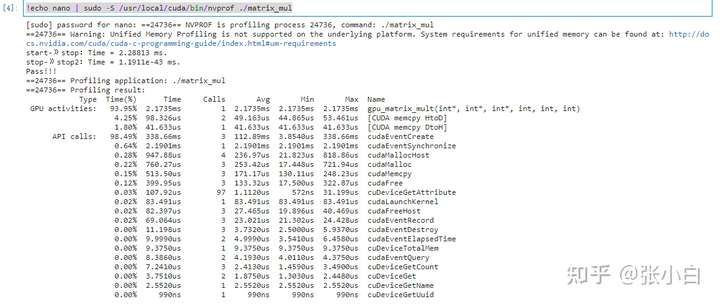
( Two )Memory
This is about CUDA Storage unit , Actually Day2 Also mentioned :

Let's go further today :
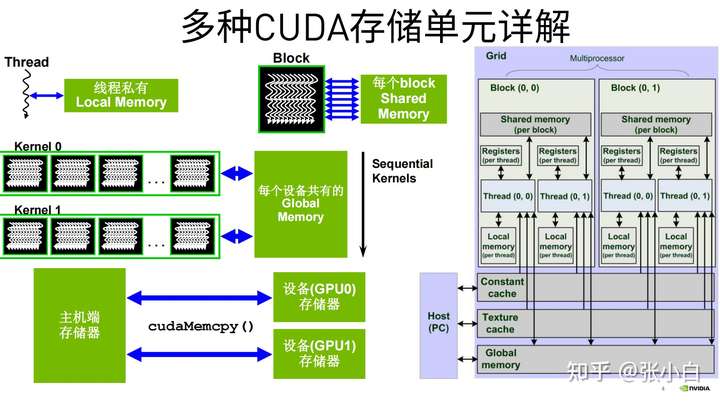
Zhang Xiaobai sorted out the following table :( Not all , It needs to be perfected )
| name | Location | purpose | Usage method | Limit | remarks |
|---|---|---|---|---|---|
| Register register | GPU Of SM On | Store local variables | Every SM There are thousands of The maximum number of a thread is 256 individual Need to save | Thread private , The fastest Thread exit will be invalid | |
| Shared memory | GPU On chip | Realization Block Thread communication within , At present, it is much faster Thread Where to communicate | __shared__ Modifier need __syncThreads() Sync | It is divided into 32 individual banks Need to save , Will affect activities warp Number | Can be 1 individual block all thread visit , Sub fast High bandwidth , Low latency |
| Local memory | Store large arrays and variables of a single thread (Register Use it when not enough ) | There is no specific storage unit | Thread private , Slower , Speed vs Global memory near | ||
| Constant memory Constant memory | Resident in device memory in | For the same warp All of the thread Access the same constant data at the same time , Like ray tracing | __constant__ Modifier Must be in host End use cudaMemcpyToSymbol initialization | There is no specific storage unit , But there is a separate cache | read-only , overall situation |
| Global memory | Equate to GPU memory Resident in device memory in | input data , Write results | overall situation , Slower | ||
| Texture memory Texture memory | For accelerating local access , Such as heat conduction model | read-only , overall situation , The speed is inferior to Shared Memory( Delay ratio Shared Memory high , Bandwidth ratio hared Memory Small ) | |||
| Host memory: Pageable memory | Host side memory | Use malloc Access to use free Release | Not available DMA visit | Memory pages can be replaced to disk | |
| Another kind Host memory: also called : Page-locked Memory,Zero-Copy Memory | Host side memory | Use cudaMallocHost visit Use cudaFreeHost Release | Belong to another kind Global memory | ||
( 3、 ... and )Shared Memory
Here is how to use Shared Memory Optimize CUDA application
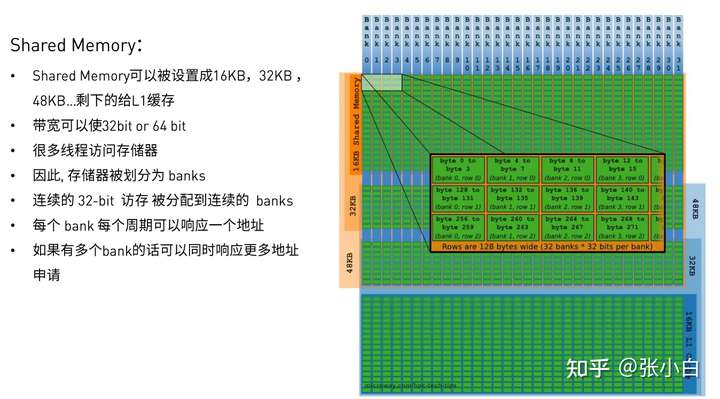
Shared Memory It is characterized by being especially fast when it is fast , It's especially slow when it's slow .
When is it fast ?
same warp All threads in access different banks
perhaps same warp All threads in read the same address ( By radio )
When is it slow ?
same warp Multiple threads access the same bank Different addresses for ( There will be bank conflict)
Serial access
Please note that :bank conflict The reason for this is warp Distribution and bank The distribution of overlapped :

How to avoid bank conflict, The simple way is Padding Law ( It seems to be called patching ):
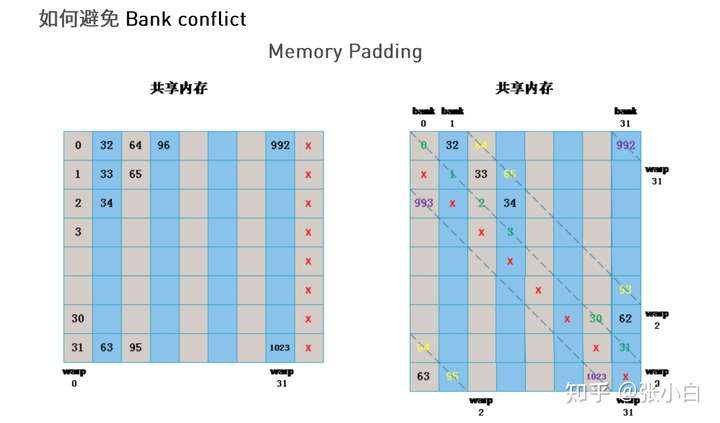
By adding an empty column , Give Way bank Forced dislocation , So that each piece of continuous data is allocated to different bank in .
It's very simple :

It's setting up Shared Memory When , Not set to Matrix BLOCK_SIZE X BLOCK_SIZE, And set to BLOCK_SIZE X (BLOCK_SIZE+1).
Last , We can use Shared Memory Optimize mXn, nXk Matrix multiplication of Code for , Improve the efficiency of storage access .
The specific method is as follows :
Apply for two Shared Memory, All are BLOCK_SIZE X BLOCK_SIZE size . One along the matrix mXn slide , One along the matrix nXk slide . take The result of the subset is added to In the purpose matrix :
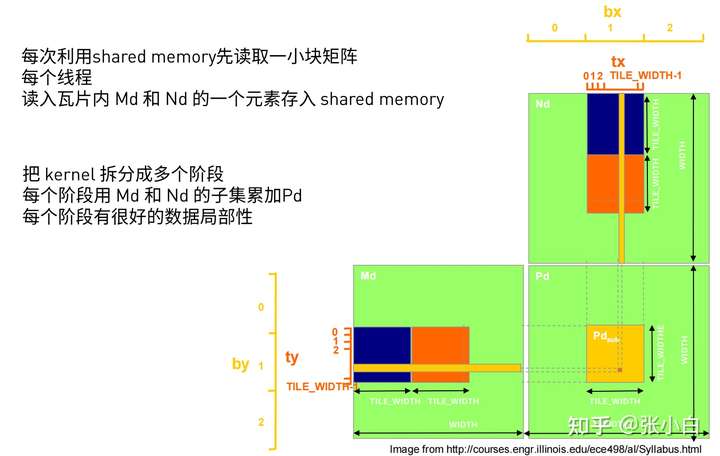
The specific code is as follows :
__global__ void gpu_matrix_mult_shared(int *d_a, int *d_b, int *d_result, int m, int n, int k) { __shared__ int tile_a[BLOCK_SIZE][BLOCK_SIZE]; __shared__ int tile_b[BLOCK_SIZE][BLOCK_SIZE]; int row = blockIdx.y * BLOCK_SIZE + threadIdx.y; int col = blockIdx.x * BLOCK_SIZE + threadIdx.x; int tmp = 0; int idx; for (int sub = 0; sub < gridDim.x; ++sub) { idx = row * n + sub * BLOCK_SIZE + threadIdx.x; tile_a[threadIdx.y][threadIdx.x] = row<n && (sub * BLOCK_SIZE + threadIdx.x)<n? d_a[idx]:0; idx = (sub * BLOCK_SIZE + threadIdx.y) * n + col; tile_b[threadIdx.y][threadIdx.x] = col<n && (sub * BLOCK_SIZE + threadIdx.y)<n? d_b[idx]:0; __syncthreads(); for (int k = 0; k < BLOCK_SIZE; ++k) { tmp += tile_a[threadIdx.y][k] * tile_b[k][threadIdx.x]; } __syncthreads(); } if(row < n && col < n) { d_result[row * n + col] = tmp; }}And put the front Where matrix multiplication is called in the code :
gpu_matrix_mult<<<dimGrid, dimBlock>>>(d_a, d_b, d_c, m, n, k); Change it to
gpu_matrix_mult_shared<<<dimGrid, dimBlock>>>(d_a, d_b, d_c, m, n, k); The rest remains the same .
Start compilation , stay Jetson Nano B01 On the implementation :
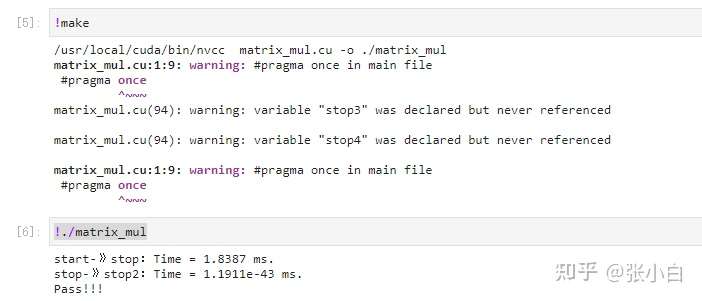
Compare the previous matrix multiplication code ,start-》stop:Time = 2.25109 ms Time drops slightly .
Zhang Xiaobai then revised blocksize, Change them into 16,8,4, Then carry out statistical summary :
| matrix MXN(m) | matrix NXK(n) | matrix NXK(k) | blocksize | stop-start(ms) |
|---|---|---|---|---|
| 100 | 100 | 100 | 32 | 1.83286 |
| 100 | 100 | 100 | 16 | 1.27365 |
| 100 | 100 | 100 | 8 | 1.23292 |
| 100 | 100 | 100 | 4 | 3.52865 |
| 100 | 100 | 100 | 6( Supplementary measurement ) | 2.1999 |
| 100 | 100 | 100 | 12( Supplementary measurement ) | 1.34755 |
From the above results ,blocksize by 8,16,32 There seems to be little difference , however blocksize by 4 The speed drops sharply when . from 100 by 4 In terms of multiples of . It seems to be this time wrap and bank Overlapped .
Then we use Padding Dafa, look :

take tile_a and tile_b The square matrix of is changed to the square matrix of mending sides :
It seems that the effect is not very good .
notes : stay blocksize by 4 when , Actually, it didn't happen bank conflict! And just because 4X4, Only 16 Threads , And one warp need 32 Threads , So it's equivalent to calculating , Half of the computing power is wasted , Then the speed is twice as slow . Teacher Huan suggested , At least NXN>32 better .
So Zhang Xiaobai will blocksize set 6, Try again , As a result, the above table is inserted . Of course , The speed still drops slightly ( It's the same below ). My personal guess is , If it is 6636 , Actually 32 One thread warp, Instead, we need 2 individual warp To get the job done , So the speed is still not good . Zhang Xiaobai guessed that blocksize The square of is set to 32 The multiple of is the most appropriate . For example, 8864 ...12X12=32X4.5, It seems not suitable .. However, the speed may be slightly improved due to more use ( It turns out to be the same )
Zhang Xiaobai worries that the matrix is too small , take Matrix from 100 Change it to 1000 try .
But once the discovery is changed to 1000 after ,CPU The calculation may not work :
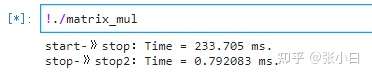
I have to put CPU That part of the code is shielded from the code compared later .

recount :
| matrix MXN(m) | matrix NXK(n) | matrix NXK(k) | blocksize | stop-start(ms) |
|---|---|---|---|---|
| 1000 | 1000 | 1000 | 32 | 265.106 |
| 1000 | 1000 | 1000 | 16 | 228.09 |
| 1000 | 1000 | 1000 | 8 | 202.382 |
| 1000 | 1000 | 1000 | 4 | 518.315 |
| 1000 | 1000 | 1000 | 6( Supplementary measurement ) | 386.171 |
| 1000 | 1000 | 1000 | 12( Supplementary measurement ) | 246.29 |
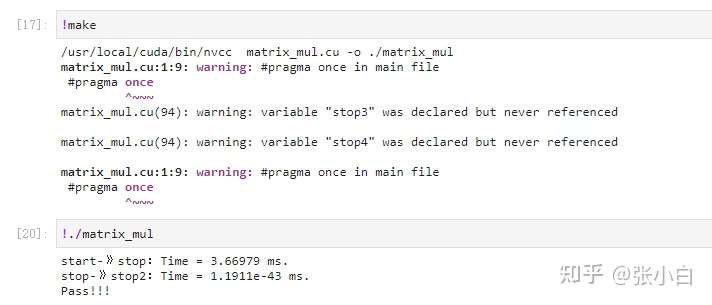
Zhang Xiaobai used Padding I tried :
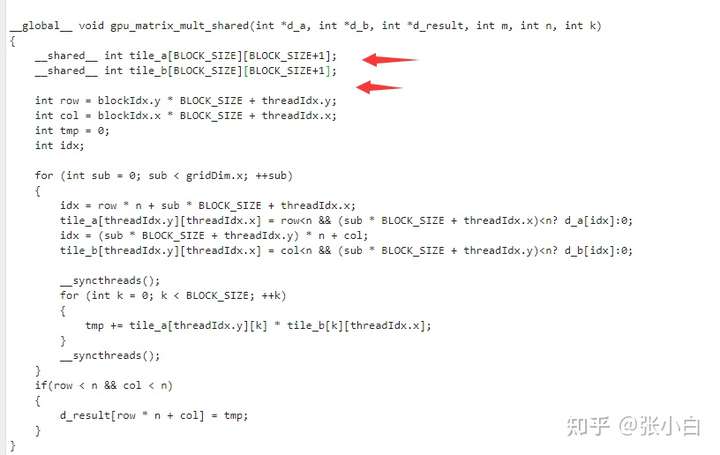
It seems that there is no acceleration effect :( It's slower )
notes : Empathy , In fact, nothing happened bank conflict, It's all in Zhang Xiaobai's heart YY..
( To be continued )
边栏推荐
- 静态资源映射
- [semantic segmentation] 2021-pvt2 cvmj
- paho交叉编译
- Several common design methods of test cases [easy to understand]
- 10 suggestions for 10x improvement of application performance
- 消费电子,冻死在夏天
- SAP Fiori @OData. Analysis of the working principle of publish annotation
- Only simple function test? One article takes you to advanced interface automatic testing technology in 6 steps
- Is it safe to open an account online now? Do you want to know that you must go to the business hall to open an account now?
- Two MySQL tables with different codes (utf8, utf8mb4) are joined, resulting in index failure
猜你喜欢

云服务大厂高管大变阵:技术派让位销售派

Oracle advanced (XIV) explanation of escape characters

Consumer electronics, frozen to death in summer

mosquitto_ Sub -f parameter use

全面、详细的SQL学习指南(MySQL方向)

leetcode刷题——排序

Scrape crawler framework

函数——(C游记)

MySQL infrastructure: SQL query statement execution process
![[Yugong series] go teaching course 009 in July 2022 - floating point type of data type](/img/85/3c776af519debbb2df802ea774c965.png)
[Yugong series] go teaching course 009 in July 2022 - floating point type of data type
随机推荐
Implementation of college logistics repair application system based on SSM
Hanyuan high tech Gigabit 2-optical 6-conductor rail managed Industrial Ethernet switch supports X-ring redundant ring network one key ring network switch
Big cloud service company executives changed: technology gives way to sales
消费电子,冻死在夏天
The latest translated official pytorch easy introduction tutorial (pytorch version 1.0)
通俗易懂讲解梯度下降法!
转转push的演化之路
皕杰报表之文本附件属件
Science fiction style, standard 6 airbags, popular · yachts from 119900
跟着李老师学线代——矩阵(持续更新)
MySQL million level data migration practice notes
There is still a chance
"Focus on machines": Zhu Songchun's team built a two-way value alignment system between people and robots to solve major challenges in the field of human-computer cooperation
Solve problems intelligently
12代酷睿处理器+2.8K OLED华硕好屏,灵耀14 2022影青釉商务轻薄本
What are the compensation standards for hospital misdiagnosis? How much can the hospital pay?
Unity3d empty package APK error summary
Knowledge points of common interview questions: distributed lock
汉源高科千兆2光6电导轨式网管型工业级以太网交换机支持X-Ring冗余环网一键环网交换机
Sed, regular expression of shell programming