当前位置:网站首页>Small project on log traffic monitoring and early warning | environment and foundation 1
Small project on log traffic monitoring and early warning | environment and foundation 1
2022-06-11 00:53:00 【Smelly Nian】
Environment and foundation :


web colony : Realization web Many machines with different functions
Each visit will be logged (access journal )
cdn: Content distribution network (Content Delivery Network), Cache , If so, go back to , If not, go back to the source , Cache it , The next visit will be soon
cdn The logs of can be synchronized to the logs of the headquarters regularly
Whether writing code or architecture , There are no problems that cannot be solved by joining the m-server !!!!
Usually it is to buy cdn service (cdn Pay by traffic )
Bandwidth 95 value : That is, the position from the minimum bandwidth to 95% of the maximum bandwidth
if cdn error You can have multiple nodes Or visit the original site
if cdn error , Monitor the access log to see the traffic ( Too large or too small ) It is obvious that
monitor :( Data from MySQL Come on ) flask frame ( Connect data to pages )

Whole project :
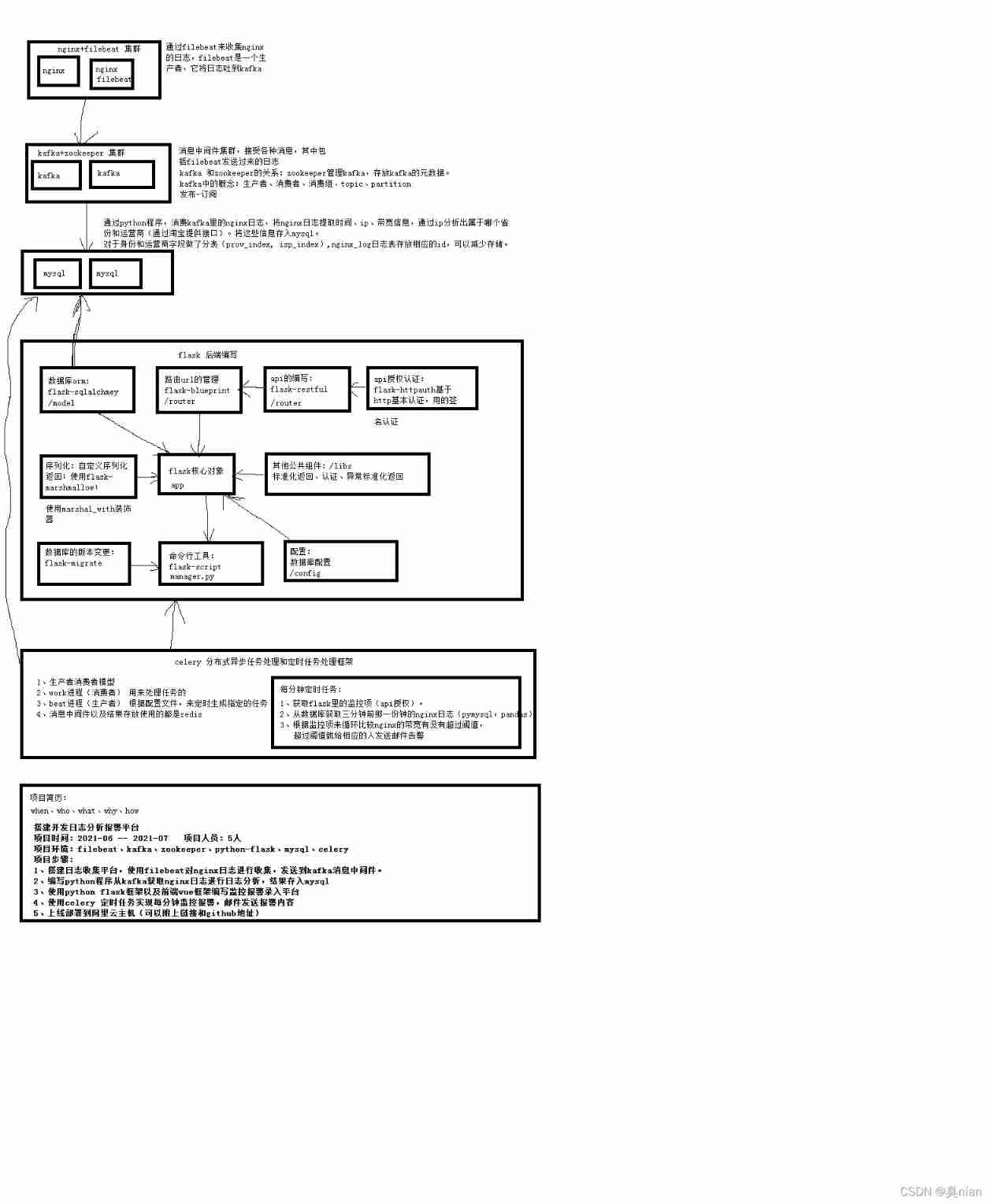
Kafka Architecture diagram :

filebeat monitor nginx acces.log Log changes
Then output to kafka colony
And we need to write python Program , consumption kafka journal , Conduct cleaning settlement , Write results to mysql
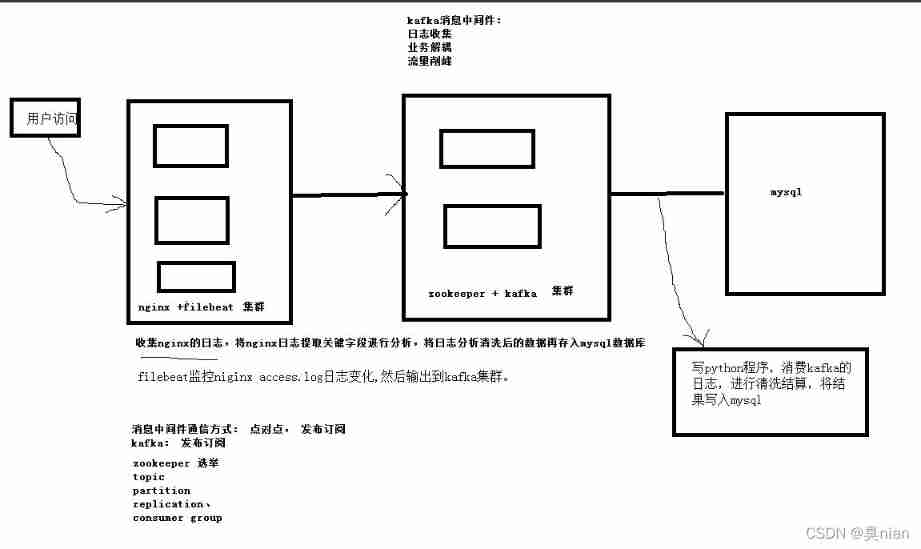
kafka Generally known as Message middleware ( middleware : It doesn't have much to do with your main business It doesn't create intuitive value for you Just play other roles in the middle )
Other message oriented middleware :redis rebbitmq nsq
# producer Consumer model ( A general model in a computer )
Add a warehouse ( middleware )
The role of message middleware ( application )( Include kafka):
1. Realize the decoupling of business
-- The failure of edge business operation will not affect the core business
-- Make it easy for a component to extend something else
2. Traffic peak clipping ( Such as double eleven Or grab red envelopes )
3. Log collection
flask It's the frame
Below flask producers E-mail becomes a consumer ( Realize the decoupling of business )
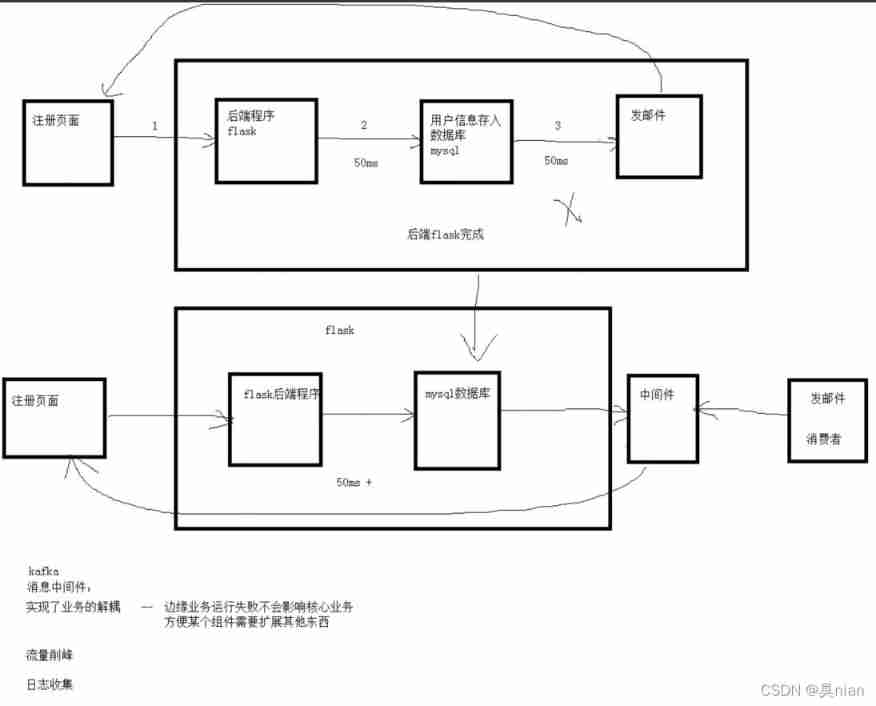
Why does our project introduce kafka?
1. decoupling Prevent processor errors from affecting the core business ( " web I can't visit )
2. Centralized storage of all logs in any program Easy to view and analyze ( Such as nginx tomcat mysql etc. You don't have to search one machine at a time )
3. Because everybody's using I want to learn
The way messages are delivered :
Point to point : one-on-one One to one correspondence between producers and consumers , Consumer consumption , There is no message oriented middleware
Release - subscribe : It can be shared by multiple consumers and independent of each other
The status of each consumer will be recorded (kafka Generally used to publish - The messaging method of subscription )
kafka Technical terms of :
broker:kafka The cluster consists of one or more servers , The server node is called broker( For example, there are only three projects broker)
topic: Categories of messages
partition: Partition Equivalent to a container for messages Increase throughput Increase of efficiency
( How many do you usually have broker Just set up a few partition)
partition Support concurrent read and write
There are many. partition Words , Generally speaking, the order of messages is different from others , But on its own partition It's still in order
There's one for each division leader
producer: producer Throwing data ( When the producer writes data, there will be a ack Sign a 0 1 -1 When writing, you will get a response )
consumer: consumer Read the data
( Consumer groups : Multiple consumers form a large consumption group Increase throughput General follow partition The numbers are consistent )
replicas: copy
(kafka The most basic principle of high availability of messages )
( in the light of partition Of )
( Appoint 2 It means there is a copy besides itself )
( therefore partition It can also be called a copy Therefore, the replica needs to be elected through the replica election algorithm leader Consumer producers will go to leader In which data is written or read Other copies are called follower Just backup If leader There's a problem Will be re elected )
(leader and follower Will be consistent )
The message must be created topic Can store
Generally speaking partition Is evenly distributed

Leader Election reference website :kafka Knowledge system -kafka leader The election - aidodoo - Blog Garden
DNS: The domain name system (Domain Name System, abbreviation :DNS) yes Internet A service of . It will be domain name and IP Address mutual mapping One of the Distributed database , Make it easier for people to access Internet .
Why choose this project ?
- Lab teacher
- Elder martial brother and elder martial sister
here ack This flag bit is not called ack It's just the configuration inside the producer
0: The producer just sends Whether the server sends messages or not
1: only leader Message of successful synchronization The producer will receive a response from the server
If the message doesn't arrive leader node ( for example leader Node crash , new leader The node has not been elected ) The producer will receive an error response , To avoid data loss , The producer will resend the message
If a node that does not receive a message becomes new leader, The message will still be lost
-1: The producer needs to get all the copies ( Include follower) After the feedback is successfully written Before continuing to send
ISR:(in-sync-replica) It is equivalent to a set list Need to synchronize follower aggregate
For example there are 5 Copies ,1 individual leader 4follower(follower All put in ISR Inside )
There's a message coming ,leader How do you know which copies to synchronize ?
according to ISR Come on , If one follower Hang up , Then delete from this list
If one follower Stuck or too slow , It will also ISR In the delete , It can even be deleted as 0, Will not recreate follower
kafka There is no guarantee that the data is absolutely consistent
kafka How to ensure high availability ( It doesn't affect the operation after hanging up )?
Multiple broker Multiple partition Multiple replica
kafka How to ensure data consistency ?
More request.required.acks From the choice of

Consumers' offest( Offset ): An offset will be recorded for each consumption
[[email protected] ~]# cat install_kafka.sh
#!/bin/bash
# You need to modify the name of each server in advance , for example kafka-1 kafka-2 kafka-3
hostnamectl set-hostname kafka-1 # The first 1 The name of the machine , And so on , In the 2 Before executing the script on the stage , Change the name to kafka-2 , The first 3 The table is modified to kafka-3
# modify /etc/hosts file , add to 3 platform kafka Server's ip The corresponding name
cat >>/etc/hosts <<EOF
192.168.0.190 kafka-1
192.168.0.191 kafka-2
192.168.0.192 kafka-3
EOF
# Install the software , Resolve dependencies
yum install wget lsof vim -y
# Install time synchronization service
yum install chrony -y
systemctl enable chronyd
systemctl start chronyd
# Set time zone
cp /usr/share/zoneinfo/Asia/Shanghai /etc/localtime
# Turn off firewall
systemctl stop firewalld
systemctl disable firewalld
# close selinux
setenforce 0
sed -i '/^SELINUX=/ s/enforcing/disabled/' /etc/selinux/config
During installation Just see glibc Don't quit Otherwise down
Now? nginx Just provide web service Provides a static interface
client ( Qin Yu ) Connection domain name www.sc.com If the domain name address is resolved randomly IP Analyze which one you can connect to
( If one of the servers hangs The client is just connected You may not be able to access the page Therefore, the page is not highly available at present )

Load Balancer :load barancer To schedule
Scheduling algorithm : polling (round rinbin abbreviation rr) All machines are treated equally
There is a weighted polling in the polling ( Added a weight: Weight value , That is to say, they are not treated equally Weighted value )
IP Hash : according to IP Hash the address
Minimum connections : Work less and give more How much work is in hand
All connections must be connected to middleware Nature is NAT Connect (full NAT)
The middleware we use this time is nginx

But the machine behind the server (backend Back end real server The server ) Don't get user Of IP Address
So we have to add a module to keep user Of IP Address To log ( stay HTTP An optional header field is added to the request message inside to retain the original source IP Address )( The middleware operates this process )
scp: Remote copy file and file name
scp file ( Transfer folder plus -r) IP Address : route Push this file to the corresponding IP The corresponding path of the address

In the middle nginx Two functions :
- Load balancing
Modify the configuration file stay http Add a load balancer in the module (upstream):

Poll by default
Weighted polling is followed by weight ( The default is 1)

Then comment out your own page Add forwarding function

( In this way, the source addresses obtained by the back-end service machines are all middleware IP)
You can also put load balancing on kafka On the same machine , Just configure a virtual host :
Add one more server and upstream
If only the port settings were different

- Let the back-end real server(backend) Know the front end user Of IP
rginx In the request message remote_address Give a newly added header field The name can be customized , Underscores... Cannot be used (x-real-ip)


The current architecture is still not highly available
Because if the reverse proxy machine hangs up, it will still collapse So we will use a highly available software later keepalived To achieve high availability
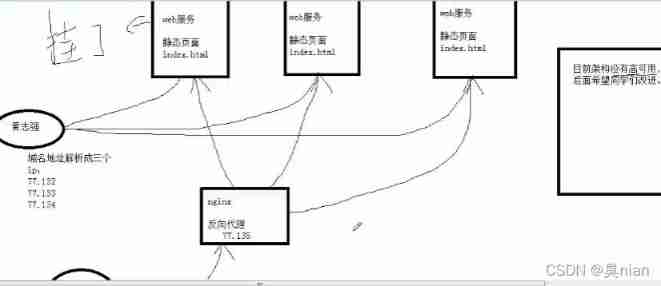

Nginx Now the architecture

The best in reality kafka and nginx Wrap up separately
![]()
Folder details :
bin Executable file
conf The configuration file (.cfg It represents the master configuration file )
docs file
lib library
logs journal
zookeeper and kafka Are two completely different services

Zookeeper Inside :
Specify the data directory
![]()
Specify port number :
![]()
Claim cluster 1 Host No 2 Host No 3 Host No
(.1 .2 .3 It is the unique identifier in the cluster Not to be repeated )
The last two are ports One for data transmission One is used to test viability and election

Represents writing data to any host Data will be synchronized
Check the log :
vim zookeeper-root-server-nginx-kafka03.out
zookeeper There will also be elections in the cluster :
Consistency algorithm :raft
( Election principles : The minority is subordinate to the majority Only those with more than half of the votes can be elected )
( Generally speaking, machines are singular )
The machine must survive for more than half
Three people negotiate See who votes who The minority is subordinate to the majority Choose a candidate ( If the machine hangs up, it will be counted as one ticket So only one of the three machines can die Otherwise, more than half of the requirements will not be met )
partition: in the light of topic The partition
tmux The effect of synchronization
CTRL+B+: Multi window synchronization
![]() Turn on synchronization
Turn on synchronization
![]() Cancel synchronization
Cancel synchronization
When it's on We need to start first. zk Start up kafka
When closing the service First off kafka Close again zk
kafka The configuration file
![]()
broker.id yes broker Unique identification of
zk The three ports of :
2181 Provide services (client visit )
The following is the communication between clusters 2888:3888
2888 Provide election survival detection
3888 Provide data interaction
Start with a daemon kafka:
bin/kafka-server-start.sh -daemon config/server.properties
stop it kafka:
![]()
bin/kafka-topics.sh --create --zookeeper 192.168.0.95:2181 --replication-factor( Specify the number of copies ) 1 --partitions 1 --topic sc
![]()
The producer of this architecture is filebeat The consumer is written by our host python Program
Kafka The data will land on the disk (/tmp/kadka-logs)
Kafka Logs can be cleared according to two dimensions
By time The default is 7 God
By size

Any one of the conditions according to time or size satisfies , Can start log cleaning
segment:kafka When saving the log, it is saved by segment In this way, we can divide time and size
When naming, it is stored in the current order
The assumptions are as follows segment
00.log 11.log 22.log
00.log When saved 0-11 A log of
11.log When saved 12-22 A log of
22.log Saved hour 22 The log after the entry
Kafka The information that creates producers and consumers is zk Inside
Connect zk:
![]()
Zookeeper Is a distributed open source configuration management service
( A file tree contains a lot of information Many hosts monitor the file tree )
(upstream Information from zookeeper Get it inside )

Zk The file inside is ls Absolute path
Look at the data in the file Namely get Absolute path
zk The topic information inside :
![]()
__consumer_offsets: What is saved is the offset of the consumer
After consumers' consumption , There will be an offset setting , The offset can be saved locally by the consumer , You can also save to kafka Server side , Save in kafka Server side words , Deposit __consumer_offests In the group ( By default, I give you points 50 Zones )
Zk effect :
Retain kafka Metadata (topic Copies, etc )
The election controller( Elect a kafka The whole cluster of controller This controller To coordinate the copy leader,follower The election )( This controller The election is based on preemption First come first served basis /controller)
So this version of kafka Can't get away from zookeeper
When the producer sends a message, it can select any one at random , There will be negotiations , This broker Will return you a copy leader Information about , The producer follows up leader Interaction
Exit and enter directly tmux Last status
tmux ls
tmux a -t 0
beats: This is a set of tools to collect and transmit information
beats The six tools of the family :( All are elk A member of the architecture )

Filebeat: Lightweight delivery tool for forwarding and centralizing log data .Filebeat Monitor the log file or location you specify , Collect log events , And forward them to the appropriate location Such as :elasticsearch redeis kafka etc.
One will be opened for each monitored file harvester
Input Component is to tell which file to monitor , And start a for each file Harvester

Logstach( use Java Written ): Tools for collection and filtering
Filebeat:

rpm -qa Is to view all the software installed on this computer
rpm It's also linux A software management command in -q query a all
rpm -ql filebeat see filebeat Where has it been installed What documents are involved
![]()
This configuration file is yml Format , Not at all wrong !!!

Data directory and log directory
![]()

Fealbeat The directory in the configuration file supports wildcards
Kafka The underlying layer communicates through host names
Zk The default window is 2181
Producer consistency is to see ack
Consumer consistency , It's the highest water level That is, the barrel effect
Filebeat It's the producer
Python A program is a consumer
Python manipulation kafka:Pykafka modular Write about consumers by yourself , Finally, print out the logs we got message Information about
( The consumers we use now are all testing tools )
边栏推荐
- [network planning] 2.2.4 Web cache / proxy server
- 海贼oj#146.字符串
- 扎实的基础知识+正确的方法是快速阅读源码的关键
- 集线器、交换机与路由器有什么区别?
- systemd 下开机启动的优化,删除无用的systemd服务
- Multipass Chinese document - instructions for use (contents page)
- Shengteng AI development experience based on target detection and identification of Huawei cloud ECS [Huawei cloud to jianzhiyuan]
- Yii2 ActiveRecord 使用表关联出现的 id 自动去重问题
- Lucene mind map makes search engines no longer difficult to understand
- How to handle file cache and session?
猜你喜欢





![[network planning] 2.4 DNS: directory service of the Internet](/img/a8/74a1b44ce4d8b0b1a85043a091a91d.jpg)
![[untitled] test](/img/6c/df2ebb3e39d1e47b8dd74cfdddbb06.gif)


随机推荐
How word inserts a guide (dot before page number) into a table of contents
MySQL
The principle and source code interpretation of executor thread pool in concurrent programming
qt程序插件报错plugin xcb
Loop structure statement
浅谈有赞搜索质量保障体系 v2021
年金险还能买吗?年金险安不安全?
集线器、交换机与路由器有什么区别?
Kubernetes入门介绍与基础搭建
亿级搜索系统(优酷视频搜索)的基石,如何保障实时数据质量?v2020
数组的字典排序
大厂是面对深度分页问题是如何解决的(通俗易懂)
Test it first
Review of software architecture in Harbin Institute of technology -- LSP principle, covariance and inversion
ts+fetch实现选择文件上传
MySql 触发器
What is thread in concurrent programming
BGP basic concept and iBGP basic configuration
[network planning] 2.2.4 Web cache / proxy server
Safety training management measures