当前位置:网站首页>Activation functions commonly used in deep learning
Activation functions commonly used in deep learning
2022-07-27 08:53:00 【DeepDriving】
This article was first published on WeChat public 【DeepDriving】, Welcome to your attention .
List of articles
Preface
In artificial neural networks , Activation functions play a very important role , Its main function is to add a nonlinear operation to all hidden layers and output layers , Make the output of neural network more complex 、 Better presentation skills . Imagine if the activation functions are linear , Then the neural network model becomes a regression model , The whole model can only represent one operation . This paper briefly introduces several activation functions commonly used in deep learning .
Several commonly used activation functions
1 Sigmoid Activation function
Sigmoid The mathematical expression of the activation function is :
f ( x ) = 1 1 + e − x f(x)=\frac{1}{1+e^{-x} } f(x)=1+e−x1
The function image is as follows :

Sigmoid The advantages of the activation function are as follows :
- Its range is [0,1], It is very suitable as the output function of the model to output a 0~1 The probability value in the range , For example, it is used to represent the category of two classifications or to represent the confidence .
- The function is continuously derivable , It can provide very smooth gradient values , Prevent abrupt gradients during model training .
shortcoming :
- We can see from the function image of its derivative , The maximum value of its derivative is only 0.25, And when x stay [-5,5] The derivative value is almost close to 0 了 . This situation will cause neurons to be in a saturated state during training , Its weight can hardly be updated during back propagation , This makes the model difficult to train , This phenomenon is called gradient vanishing problem .
- Its output is not in 0 For the center, but are greater than 0 Of , In this way, the neurons of the next layer will get the all positive signal output from the previous layer as the input , therefore
SigmoidThe activation function is not suitable to be placed in the front layer of neural network, but generally in the last output layer . - You need to do an exponential operation , High computational complexity .

2 Tanh Activation function
Tanh The mathematical expression of the activation function is :
f ( x ) = e x − e − x e x + e − x f(x)=\frac{e^{x}-e^{-x}}{e^{x}+e^{-x} } f(x)=ex+e−xex−e−x
The function image is as follows :
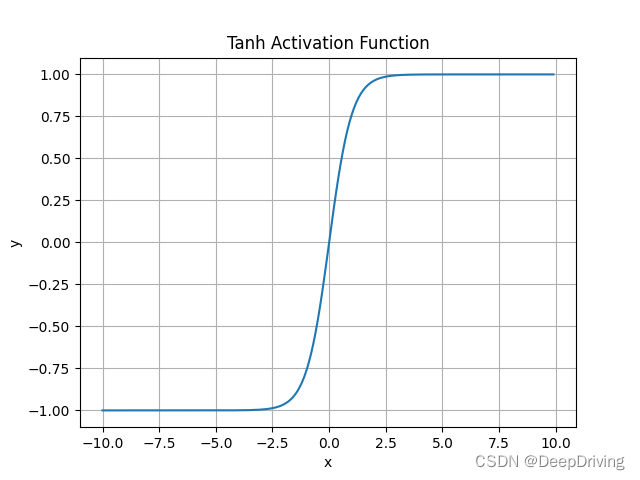
Tanh The value range of the activation function is 0 Centred [-1,1], This will solve the problem Sigmoid The output of the activation function is not in 0 Centered problem . But again , Use Tanh Activation function also has the problems of gradient disappearance and high computational complexity . The following is the function image of its derivative :

3 ReLU Activation function
ReLU The mathematical expression of the activation function is :
f ( x ) = m a x ( 0 , x ) f(x)=max(0,x) f(x)=max(0,x)
The function image is as follows :

ReLU The advantage of activation function is that it can solve Sigmoid and Tanh The gradient vanishing problem of activation function , But there are also some disadvantages :
- And
Sigmoidequally , Its output is not in 0 Centred . - If the input is less than 0, Then its output is 0, There is no gradient return when it leads to back propagation , Thus, the weights of neurons cannot be updated , This situation is equivalent to that neurons are inactive , Into the “ dead zone ”.
4 LeakyRelu Activation function
LeakyRelu The mathematical expression of the activation function is :
f ( x ) = m a x ( α x , x ) f(x)=max(\alpha x,x) f(x)=max(αx,x)
The function image is as follows :

LeakyRelu The activation function solves this problem by adding a small positive slope to the negative half axis ReLU Activate the “ dead zone ” problem , This slope parameter α \alpha α It is a manually set super parameter , Generally set as 0.01. In this way ,LeakyRelu The activation function can ensure that the weight of neurons in the model training process is less than 0 Will still be updated in case of .
5 PRelu Activation function
PRelu The mathematical expression of the activation function is :
f ( α , x ) = { α x , f o r x < 0 x , f o r x ≥ 0 } f(\alpha ,x)=\begin{Bmatrix} \alpha x , for \ x<0 \\ x , for \ x\ge 0 \end{Bmatrix} f(α,x)={ αx,for x<0x,for x≥0}
The function image is as follows :
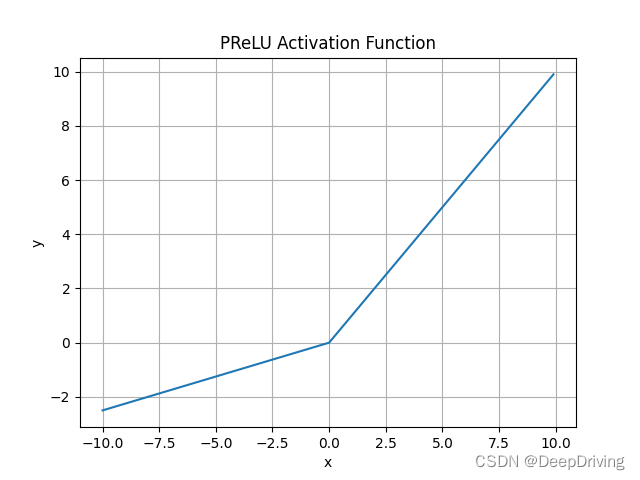
And LeakyRelu The difference between activation functions is ,PRelu The slope parameter of the negative half axis of the activation function α \alpha α It is a constant value obtained by learning rather than manually setting , It seems more reasonable to choose through learning .
6 ELU Activation function
ELU The mathematical expression of the activation function is :
f ( α , x ) = { α ( e x − 1 ) , f o r x ≤ 0 x , f o r x > 0 } f(\alpha ,x)=\begin{Bmatrix} \alpha (e^{x} - 1) , for \ x\le 0 \\ x , for \ x> 0 \end{Bmatrix} f(α,x)={ α(ex−1),for x≤0x,for x>0}
The function image is as follows :

And LeakyRelu and PRelu The difference between activation functions is ,ELU The negative half axis of the activation function is an exponential function rather than a straight line , The whole function is smoother , This can make the convergence speed of the model faster in the training process .
7 SELU Activation function
SELU The mathematical expression of the activation function is :
f ( α , x ) = λ { α ( e x − 1 ) , f o r x ≤ 0 x , f o r x > 0 } f(\alpha ,x)=\lambda \begin{Bmatrix} \alpha (e^{x} - 1) , for \ x\le 0 \\ x , for \ x> 0 \end{Bmatrix} f(α,x)=λ{ α(ex−1),for x≤0x,for x>0}
among λ = 1.0507 , α = 1.6733 \lambda=1.0507, \alpha=1.6733 λ=1.0507,α=1.6733.
The function image is as follows :

SELU The activation function is defined in the self normalization network , Internal normalization is achieved by adjusting the mean and variance , This internal normalization is faster than external normalization , This makes the network converge faster .
8 Swish Activation function
Swish The mathematical expression of the activation function is :
f ( x ) = x ∗ s i g m o i d ( x ) f(x)= x * sigmoid(x) f(x)=x∗sigmoid(x)
The function image is as follows :

From the above figure, we can observe ,Swish The activation function has no upper bound but a lower bound 、 smooth 、 Nonmonotonic properties , These characteristics can play a beneficial role in the process of model training . Compared with other functions mentioned above ,Swish The activation function is in x=0 Smoother around , The non monotonic characteristic enhances the expression ability of input data and weights to be learned .
9 Mish Activation function
Mish The mathematical expression of the activation function is :
f ( x ) = x ∗ t a n h ( l n ( 1 + e x ) ) f(x)=x * tanh(ln(1+e^{x})) f(x)=x∗tanh(ln(1+ex))
The function image is as follows :

Mish The function image of the active function is the same as Swish The activation function is similar to , But smoother , The disadvantage is that the computational complexity is higher .
How to choose the right activation function
Gradient vanishing and gradient explosion are common problems in training depth Neural Networks , Therefore, it is very important to choose the appropriate activation function . If you want to select the activation function of the model output layer , You can choose according to the task type :
- Linear activation function is selected for regression task .
- II. Classification task selection
SigmoidActivation function . - Multi category task selection
SoftmaxActivation function . - Multi tag task selection
SigmoidActivation function .
If you want to select the activation function of the hidden layer , Generally, it is selected according to the type of neural network :
- Convolution neural network selection
ReLUActivation function and its improved activation function (LeakyRelu、PRelu、SELUwait ). - Recurrent neural network selection
SigmoidorTanhActivation function .
besides , There are also some empirical guidelines for reference :
ReLUAnd its improved activation function is only suitable for hidden layers .SigmoidandTanhActivation functions are generally used in the output layer rather than in the hidden layer .SwishThe activation function is suitable for more than 40 Layer of neural network .
Reference material
- https://www.v7labs.com/blog/neural-networks-activation-functions
- https://learnopencv.com/understanding-activation-functions-in-deep-learning/
- https://himanshuxd.medium.com/activation-functions-sigmoid-relu-leaky-relu-and-softmax-basics-for-neural-networks-and-deep-8d9c70eed91e
Welcome to my official account. 【DeepDriving】, I will share computer vision from time to time 、 machine learning 、 Deep learning 、 Driverless and other fields .

边栏推荐
猜你喜欢

数智革新
![2040: [Blue Bridge Cup 2022 preliminary] bamboo cutting (priority queue)](/img/76/512b7fd4db55f9f7d8f5bcb646d9fc.jpg)
2040: [Blue Bridge Cup 2022 preliminary] bamboo cutting (priority queue)

Aruba学习笔记10-安全认证-Portal认证(web页面配置)

Hangzhou E-Commerce Research Institute released an explanation of the new term "digital existence"
永久设置source的方法

Minio 安装与使用

E. Split into two sets

微信安装包从0.5M暴涨到260M,为什么我们的程序越来越大?
NiO Summary - read and understand the whole NiO process
![[interprocess communication IPC] - semaphore learning](/img/47/b76c329e748726097219abce28fce8.png)
[interprocess communication IPC] - semaphore learning
随机推荐
"Weilai Cup" 2022 Niuke summer multi school training camp 1
4276. 擅长C
Flask's operations on model classes
Do a reptile project by yourself
PVT的spatial reduction attention(SRA)
NIO this.selector.select()
2034: [Blue Bridge Cup 2022 preliminary] pruning shrubs
Supervisor 安装与使用
Can "Gulangyu yuancosmos" become an "upgraded sample" of China's cultural tourism industry
HUAWEI 机试题:字符串变换最小字符串 js
Arm system call exception assembly
B tree
[interprocess communication IPC] - semaphore learning
4274. 后缀表达式
Network IO summary
693. 行程排序
07_ Service registration and discovery summary
JWT authentication and login function implementation, exit login
Encountered 7 file(s) that should have been pointers, but weren‘t
[nonebot2] several simple robot modules (Yiyan + rainbow fart + 60s per day)