当前位置:网站首页>Spark - understand partitioner in one article
Spark - understand partitioner in one article
2022-06-30 22:14:00 【BIT_ six hundred and sixty-six】
One . introduction
spark Handle RDD Providing a foreachPartition and mapPartition The method of partition To deal with , One partition It may contain the contents of one or more files ,Partitioner Can be based on pairRDD Of key Implement customization partition The content of .

Partitioner The two most basic methods of a function are numPartitions and getPartition(key: Any):
A.numPartitions: Get the total number of partitions
B.getPartition:
according to key Get current partition Number of corresponding partitions , The scope is [0, numPartitions-1], there partitionId And TaskContext.getPartitionId The value is consistent. , adopt hash(key) obtain int Of partitionNum Variable , identical partitonNum Of key Corresponding paidRDD Assign to the same partition Internal treatment
common Partition Partition types are as follows :
| Partition function | Partition method |
| HashPartitioner | according to hash(key) Partition |
| RangePartitioner | according to Range Boundary zoning |
| Partitioner | Partition according to custom rules |
Two .HashPartitioner
1. Source code analysis
hashPartitioner be based on Object.hashcode % partitionNum partition , We need to pay attention to partitionNum The value of is to need >= 0 Of ,partiionNum Is obtained through getPartition In function nonNegativeMod Function implementation
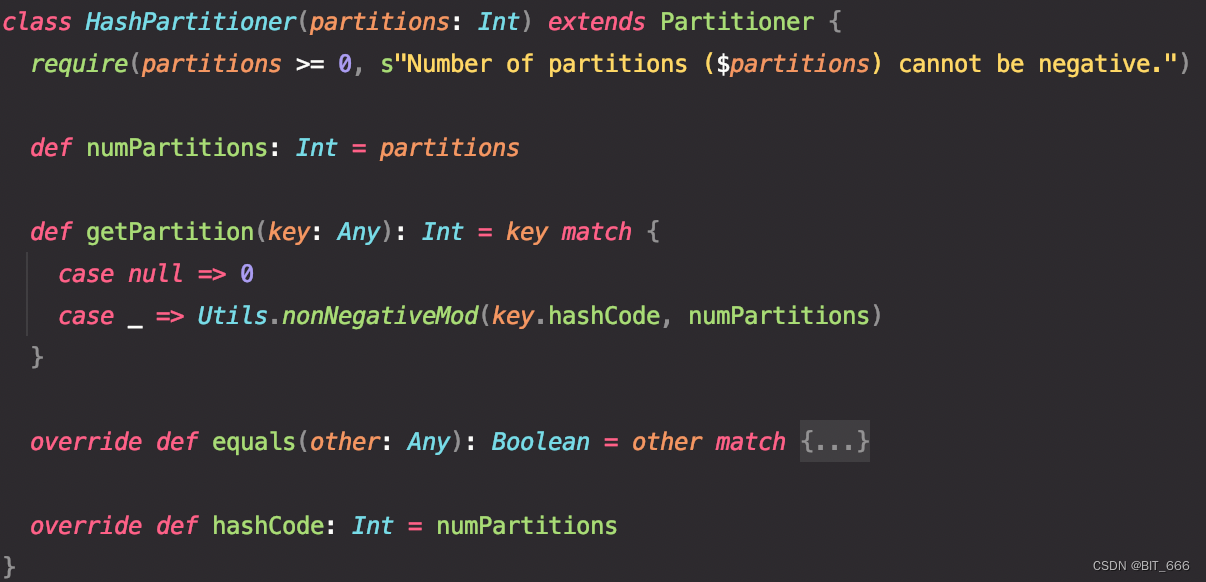
nonNegativeMod In the realization of hashCode % partitionNum The requirement of nonnegativity is added on the basis of , because partitionNum Is greater than or equal to 0 Number of :

2. Code testing
val testRdd = sc.parallelize((0 until 500).toArray.zipWithIndex)
val partitionNum = 5
testRdd.partitionBy(new HashPartitioner(partitionNum)).foreachPartition(partition => {
if (partition.nonEmpty) {
val info = partition.toArray.map(_._1)
val taskId = TaskContext.getPartitionId()
info.take(3).map(num => println(s"taskId: $taskId num: $num hashNum: ${num.hashCode()} %$partitionNum=${num.hashCode() % 5}"))
}
})There will be 0-499 common 500 A digital zipWithIndex Generate pairRdd And pass HashPartitioner Generate 5 individual Partition, adopt TaskContext obtain partitionId, Print the logs one by one , Here the local[1] Configuration of :
val conf = new SparkConf().setAppName("PartitionTest").setMaster("local[1]")
You can see the same... In the red box TaskId Corresponding partition Internal key All have the same mod value , So they are divided into the same partition .

3.repartition
In normal use repartition Function adoption HashPartitioner Function as the default partition function , Let's try :
println("=============================repartition=============================")
testRdd.repartition(5).foreachPartition(partition => {
if (partition.nonEmpty) {
val info = partition.toArray.map(_._1)
val taskId = TaskContext.getPartitionId()
info.take(3).map(num => println(s"taskId: $taskId num: $num hashNum: ${num.hashCode()} %$partitionNum=${num.hashCode() % 5}"))
}
})What's different from the above is taskId There's a difference , But the same mod Of key Will still be divided into the same partition :

3、 ... and .RangePartitioner
1. Source code analysis
RangePartitioner The elements are roughly evenly distributed to different partitions according to the range partition, The scope is passed in by RDD Content sampling to determine .

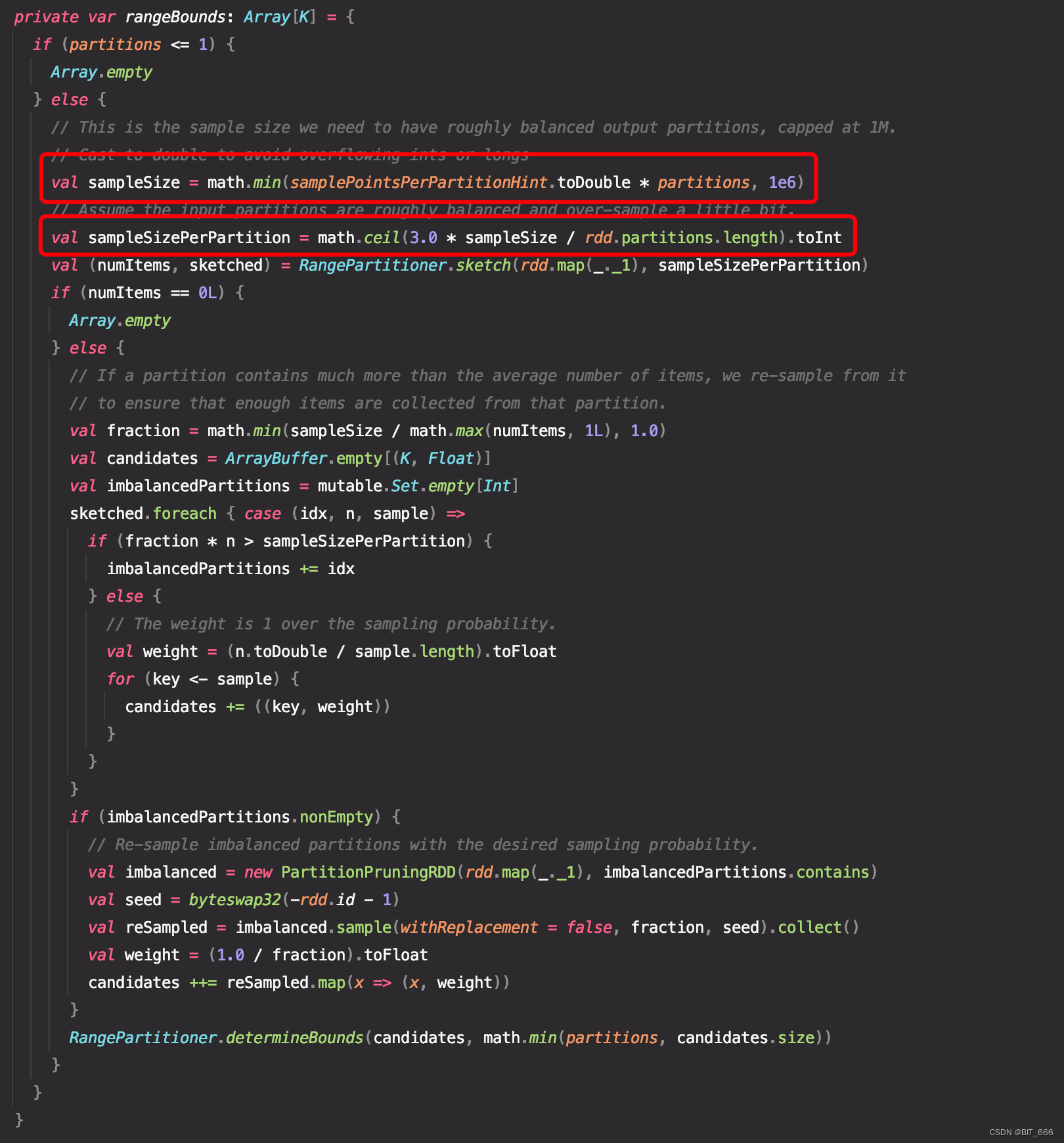
except partitions In addition to the parameters of ,RangePartitioner You also need to partition the rdd Incoming for random sampling generation rangeBounds Use , Compared with HashPartition direct hashCodes % partitionNum The operation of ,RangePartitioner The partition is divided into two steps :
A. Get partition Boundary
The sample size of the partition to be sampled is 1m, Convert to double Avoid precision overflow , first else Logically, if the number of items in a partition is far more than the average , Then resample , To ensure that the partition can collect enough samples , The bottom if The function resamples the unbalanced partition with the required sampling probability , Finally, we get the boundary of the partition , Here you can take time to study it alone . Take an example to roughly understand , If all partition Internal key The range is 0-500, Random generation 5 Zones , Generate a 101-203-299-405 Such a range , Each number represents the upper bound of its partition , For example, zoning 0 The upper bound of is 101, Partition 1 The upper bound of is 203, By analogy , The resulting 5 Zones .
B. according to Boundary Get partition
If the partition array length is not greater than 128, A simple cycle of violence search , If exceeded 128, Then binary search is performed , At the same time, provide the basis ascending Parameter determination partitionId The order or reverse order of . This is the same as before. Spark-Scala The optimization strategy adopted for data feature bucket division is consistent , You can have a look if you are interested :Scala - Numerical characteristics are divided into buckets .

2. Code testing
val testRdd = sc.parallelize((0 until 500).toArray.zipWithIndex)
testRdd.partitionBy(new RangePartitioner(5, testRdd)).foreachPartition(partition => {
if (partition.nonEmpty) {
val info = partition.toArray.map(_._1)
val taskId = TaskContext.getPartitionId()
info.take(3).map(num => println(s"taskId: $taskId num: $num hashNum: ${num.hashCode()} length: ${info.length}"))
}
})Still used 500 A pure number RDD Conduct range Partition testing , In order to verify the idea of roughly equal distribution , There will be no printing at last mod result , Instead, print each partition Number of internal elements , You can see that the number of each group is not the same as before HashPartitioner Get the same uniformity , But between 500/5=100 Up and down , But the total is 500.

Four .SelfPartitioner
1. Source code analysis
Customize Partitioner It mainly realizes the following two functions , It's mentioned above , Simply add :
numPartitions: Get the total number of partitions
getPartition: obtain key Corresponding partition id
2. Code implementation
A.SelfPartitioner
Based on the above RangePartitioner Uneven partition , We use SelfParitioner Customize the partition to achieve uniform partition , Here laziness directly generates the corresponding upper bound boundary, In the real world boundary It should be based on partitionNum The quantity of is dynamically generated ,getPartition Function introduced break Mechanism , Unfamiliar students can move :Scala - elegant break, Then there is the basic cycle of violence , If the upper bound is found, the corresponding index As a partition id.
import scala.util.control.Breaks._
class SelfPartition(partitionNum: Int) extends Partitioner {
val boundary: Array[(Int, Int)] = Array(100, 200, 300, 400, 500).zipWithIndex
override def numPartitions: Int = partitionNum
override def getPartition(key: Any): Int = {
val keyNum = key.toString.toInt
var partitionNum = 0
breakable(
boundary.foreach(bound => {
if (keyNum < bound._1) {
partitionNum = bound._2
break()
}
})
)
partitionNum
}
}B. Running results
val testRdd = sc.parallelize((0 until 500).toArray.zipWithIndex)
testRdd.partitionBy(new SelfPartition(5)).foreachPartition(partition => {
if (partition.nonEmpty) {
val info = partition.toArray.map(_._1)
val taskId = TaskContext.getPartitionId()
info.take(3).map(num => println(s"taskId: $taskId num: $num hashNum: ${num.hashCode()} length: ${info.length}"))
}
})adopt SelfPartitioner After partitioning, you can see 0-499 common 500 Elements are evenly distributed to 5 individual Partition Inside , Except for the simplest boundary Method outside the partition , You can also customize it hash Method ,key The default type of is Any, If key No scala Basic data types for , Then use key.asInstanceOf[T] Conversion can be .

5、 ... and .repartitionAndSortWithinPartitions
1. Function analysis

In addition to normal partition requirements ,spark Also provide repartitionAndSortWithinPartitions function , This function is based on the given partition Partitioner Partition to get new RDD, And sort according to each key , bring RDD Keep the data in a certain order , The method ratio repartition + sorting More efficient , Because it puts the sorting mechanism into shuffle In the process of .

In the source code, this method is located in OrderedRddFunctions Within class , Only incoming partition functions are supported Partitioner,ordering Sorting rules need to use implict The method definition of the implicit function is passed in :
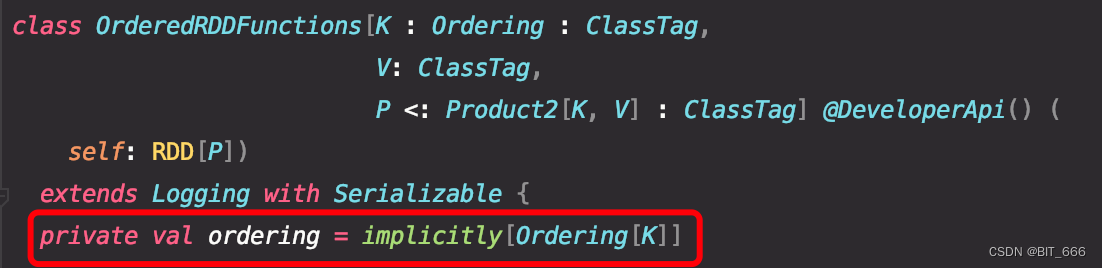
For those that need to be partitioned key: Any, You need to define an implicit function to ensure its implementation Ordering Interface to implement post partition sorting , Otherwise, you can only partition without sorting .
2. Code implementation
A. Partition sort by
On the basis of partition function , Added Ordering Implicit function , here Partitioner The function is still responsible for key Get the partition Id, Different from the above , Partition while rdd Conduct shuffle, among order The rules of are given by implicit functions , Here we sort by comparing their scores , If you want to reverse the order, just add a minus sign -(x.score - y.score).
// Students
case class Student(name: String, score: Int)
// Implicit function -Ordering
implicit object StudentOrdering extends Ordering[Student] {
override def compare(x: Student, y: Student): Int = {
x.score - y.score
}
}
class SelfSortPartition(partitionNum: Int) extends Partitioner {
val boundary: Array[(Int, Int)] = Array(100, 200, 300, 400, 500).zipWithIndex
override def numPartitions: Int = partitionNum
override def getPartition(key: Any): Int = {
val stuKey = key.asInstanceOf[Student]
val keyNum = stuKey.name.toInt
var partitionNum = 0
breakable(
boundary.foreach(bound => {
if (keyNum < bound._1) {
partitionNum = bound._2
break()
}
})
)
partitionNum
}
}B. The main function
Use here 0-499 Of String Type as student number ,Score Then take math.random x 100 To simulate , Partition use Student Of name id, So the partition of each element is unchanged , What changes is the order of each element .
println("=============================SortPartition=============================")
val studentRdd = sc.parallelize((0 until 500).toArray.map(num => (Student(num.toString, (math.random * 100).toInt), true)))
studentRdd.take(5).foreach(println(_))
studentRdd.repartitionAndSortWithinPartitions(new SelfSortPartition(5)).foreachPartition(partition => {
if (partition.nonEmpty) {
val taskId = TaskContext.getPartitionId()
println("===========================")
partition.toArray.take(5).map(stu => {
println(s"TaskId: ${taskId} Name: ${stu._1.name} Score: ${stu._1.score}")
})
}
}Due to the use x.score - y.score Sequential counting , So sort by score from small to large :

This is the worst student I have ever taken , How can I take the exam 0 branch .
C. Other writing
except StudentOrdering Writing , Direct Object Student Writing , here A <: Student Said any A All subclasses of support this implicit call , About <: Relevant knowledge can refer to :Scala Generic Generic class details - T
object Student {
implicit def orderingByGradeStudentScore[A <: Student]: Ordering[A] = {
Ordering.by(stu => stu.score)
}
}
implicit object StudentOrdering extends Ordering[Student] {
override def compare(x: Student, y: Student): Int = {
x.score - y.score
}
}If you want to support multiple sorting , You can add multiple fields in Yuanzu , Will give priority to name Compare again score, And so on , Similarly, if you want to reverse the order , For example, arrange in reverse order according to scores , Is changed to (stu.name,-1 * stu.score)
object Student {
implicit def orderingByGradeStudentScore[A <: Student]: Ordering[A] = {
Ordering.by(stu => (stu.name, stu.score))
}
}If the corresponding partition key It didn't come true implict Comparison of implicit functions , Then the function will directly report grey , Can't compile :

6、 ... and . summary
Partitioner These are the general usages of , Except for three HashPartitioner Out of function ,Spark It can also be done through repartitionAndSortWithinPartitions Implement partition + Sorted requirements , On the whole ,Partitioner Support user-defined partition rules to plan tasks task What kind of partition data , It is very convenient for fine processing and regional customization , besides , Some data that needs to be processed sequentially or stored sequentially , adopt SortWithinPartitions The method can also improve efficiency , Very nice, nice . Finally, continue to lament the abstraction of naming ,partition - Fragmentation 、 Partition , Seeing the screen now is like seeing RDD.

边栏推荐
- Pytorch quantitative perception training (qat) steps
- Error filesystemexception: /data/nodes/0/indices/gttxk-hntgkhacm-8n60jw/1/index/ es_ temp_ File: structure needs cleaning
- [BSP video tutorial] BSP video tutorial issue 19: AES encryption practice of single chip bootloader, including all open source codes of upper and lower computers (June 26, 2022)
- How to judge whether the JS object is empty
- Gartner focuses on low code development in China how UNIPRO practices "differentiation"
- msf之ms17-010永恒之蓝漏洞
- Bloom filter
- latex左侧大括号 latex中大括号多行公式
- B_ QuRT_ User_ Guide(35)
- Uniapp routing uni simple router
猜你喜欢

How to realize the center progress bar in wechat applet

JD and Tencent renewed the three-year strategic cooperation agreement; The starting salary rose to 260000 yuan, and Samsung sk of South Korea scrambled for a raise to retain semiconductor talents; Fir

顺祝老吴的聚会

Jupyter notebook/lab switch CONDA environment

部门新来了个阿里25K出来的,让我见识到了什么是天花板

Pytorch quantitative practice (1)

Is machine learning suitable for girls?
Notes [introduction to JUC package and future]

The Jenkins download Plug-in can't be downloaded. Solution
![[career planning for Digital IC graduates] Chap.1 overview of IC industry chain and summary of representative enterprises](/img/d3/68c9d40ae6e61efc10aca8bcc1f613.jpg)
[career planning for Digital IC graduates] Chap.1 overview of IC industry chain and summary of representative enterprises
![Notes [introduction to JUC package and future]](/img/d9/f96830defb9faa812ecf9e3925e971)
随机推荐
Interesting plug-ins summary
RP prototype resource sharing - shopping app
Apache server OpenSSL upgrade
Bloom filter
HDFS centralized cache management
程序员女友给我做了一个疲劳驾驶检测
B_ QuRT_ User_ Guide(35)
Do a scrollbar thinking
The Three Musketeers: One for All!
Qsort function and Simulation Implementation of qsort function
Some problems when SSH default port is not 22
机器学习中如何使用数据集?
Femas:云原生多运行时微服务框架
Anti leakage family photo in attack and defense drill
On several key issues of digital transformation
Go Web 编程入门: 一探优秀测试库 GoConvey
京东与腾讯续签三年战略合作协议;起薪涨至26万元,韩国三星SK争相加薪留住半导体人才;Firefox 102 发布|极客头条
Some memory problems summarized
机器学习适合女生学吗?
vncserver: Failed command ‘/etc/X11/Xvnc-session‘: 256!