当前位置:网站首页>第六周复习
第六周复习
2022-07-27 02:19:00 【皮糖小王子】
正则表达式
1.正则表达式
(1)概念:正则表达式是一门独立的语言,专门用来匹配,校验和筛查所需数据,通用于任何编程语言。
(2)在python中如果想要使用正则就必须要借助re模块。
(3)初步了解正则之手机号码验证import re phone_number = input('please input your phone_nuber>>>:').strip() if re.match('^[13|15|17|18|19][0-9]{9}',phone_number): print(phone_number) else: print('输入不合法')
2.正则表达式之字符串
字符串在没有量词修饰的情况下一次只会针对一个数据在中括号内编写的多个数据值彼此都是或的关系
正则 说明 全称 [0-9] 匹配0到9之间的任意一个数字(包括0和9 [0123456789] [A-Z] 匹配A到Z之间的任意一个字母(包括A和Z) [ABCD,WXYZ] [a-z] 匹配a到z之间的任意一个字母(包括a和z) [abcd…wxyz]
3.正则表达式之特殊符号
特殊符号在没有量词修饰的情况下一个符号一次只会针对一个数据值^于$的组合能够明确的限制想要查找的具体数据管道符|在很多场景下的意思都是或()用于后续的正则起别名,分组获取对应数据
正则 说明 . 匹配除换行符以外的任意字符 \w 匹配字母或数字或下划线 \W 匹配非字母或数字或下划线 \d 匹配数字 ^ 匹配字符串的开头 $ 匹配字符串的结尾 a管道符b 匹配字符a或字符b () 给正则表达式分组,不影响正则表达式的匹配 [] 匹配字符组中的字符 [^] 匹配除了字符组中字符的所有字符
4.正则表达式之量词
在正则表达式中所有的量词默认都是贪婪匹配(尽可能多的匹配)量词不能单独使用,必须跟在表达式的后面,并且只能影响紧挨着的左边那一个
正则 说明 * 重复零次或更多次(默认就是更多次) + 重复一次或更多次(默认就是更多次) ? 重复零次或一次(默认就是一次) {n} 重复n次 {n,} 重复n次或更多次 {n,m} 重复n到m次
5.贪婪匹配与非贪婪匹配
(1)概念:在满足匹配时,匹配尽可能长的字符串。结束的标志有上述符号左右两边添加的表达式决定
名词 符号 贪婪匹配 .* 非贪婪匹配 .*?
6.取消转义
在正则表达式中,存在着很多特殊意义的元字符,eg:\n;\s等,如果要匹配正确的\n或\s而不是换行符就需要对\进行转义,变成.
正则 待匹配字符串 匹配结果 说明 \n \n False 在正则表达式中\是有特殊意义的字符,\n表示换行 双斜杠n \n True 转义\之后变成\,即可匹配 “\n” ‘\n’ True 在python中,字符串中的’‘也需要转义,所以每一个字符串’'又需要转义一次 r’\n’ r’\n’ True 在字符串之前加r,让整个字符串不转义
re模块
1.re.findall
通过正则表达式筛选出文本中所有符合条件的数据import re res = re.findall('a','jason oscar aaa') print(res) # 结果是个列表 # ['a', 'a', 'a', 'a', 'a']
2.re.finditer
finditer与findall作用一致,只不过结果会被处理成迭代器对象,用于节省内存import re res = re.finditer('a','jason oscar aaa') print(res) # <callable_iterator object at 0x000001E559BD3710>
3.re.search
search通过正则表达式匹配到一个符合条件的内容就结束import re res = re.search('a','jason oscar aaa') print(res) # <_sre.SRE_Match object; span=(1, 2), match='a'> print(res.group()) # a
4.re.match
match通过正则表达式从头开始匹配,如果头部已经不符合,那么后面则直接不执行import re res = re.match('a','jason oscar aaa') print(res) # None res1 =re.match('a','ason oscar aaa') print(res1) # <_sre.SRE_Match object; span=(0, 1), match='a'>
5.re.compile
compile能够提前准备好正则,之后可以反复使用,减少代码冗余import re obj = re.compile('a') # 提前定义好一个正则 print(re.findall(obj,'safsecxcfdwerwrdd')) # ['a'] print(re.findall(obj,'saafedasadasfe3as')) # ['a', 'a', 'a', 'a', 'a', 'a'] print(re.findall(obj,'adsfawdxfadaswdad')) # ['a', 'a', 'a', 'a', 'a']
6.re模块特殊补充之分组
(1)re.findallimport re res = re.findall('abc','abcabcabc') print(res) # ['abc', 'abc', 'abc']
findall针对分组的正则表达式匹配到的结果优先展示!!!import re res1 = re.findall('a(b)c','abcabcabc') print(res1) # ['b', 'b', 'b']
findall也能够取消分组优先展示————(?:)import re res = re.findall('a(?:b)c','abcabcabcabc') print(res) # ['abc', 'abc', 'abc', 'abc'](2)re.search
import re res = re.search('a(b)(c)','abcabcabc') print(res.group()) # abc print(res.group(1)) # b print(res.group(2)) # c**
7.re模块特殊补充之别名
一般用在search和match,不建议在findall使用!!!结构:?P<别名>res = re.search('a(?P<id>b)(?P<name>c)','abcabcabc') print(res.group()) # abc print(res.group(1)) # b print(res.group(2)) # c print(res.group('id')) # b print(res.group('name')) # c
第三方模块的下载
1.第三方模块使用条件
第三方模块必须先下载才可以导入使用
python下载第三方模块需要借助于pip工具
2.下载命令
pip3.6(python解释器版本) install 模块名
openpyxl模块
1.模块描述:
主要用于操作excel表格 也是pandas底层操作表格的模块
2.openpyxl实操
(1)创建excel文件# 创建excel表 from openpyxl import Workbook # 导入模块 wb = Workbook() # 创建excel文件 wb1 = wb.create_sheet('成绩表') wb2 = wb.create_sheet('财务表') wb3 = wb.create_sheet('帅哥表', 0) wb1.title = '舔狗表' # 支持二次修改 wb1.sheet_properties.tabColor = "1072BA" # 修改工作簿颜色(2)
写入数据
第一种写入方式:wb1['A1'] = '叙利亚鸡丁' wb1['D2'] = '快男'第二种写入方式:
wb1.cell(row=3, column=2, value='老六冲啊')第三种写入方式(批量写入):
wb1.append(['username','password','age','gender','hobby']) wb1.append(['jason1',123,18,'male','read']) wb1.append(['jason2',123,18,'male','read']) wb1.append(['jason3',123,18,'male','read']) wb1.append(['jason4',123,18,'male','read']) wb1.append(['jason4',123,18,'male',None]) wb1.append([None,123,18,'male',''])
3.openpyxl读数据
openpyxl不擅长读数据,所以有一些模块优化了读取的方式,我们一般会用这种新模块(pandas模块)。# openpyxl读写数据使用的模块不一样 from openpyxl import Workbook from openpyxl import load_workbook # 读数据 wb = load_workbook(r'111.xlsx') print(wb.sheetnames) # 查看excel文件中所有的工作簿名称 ['成绩表', 'Sheet', '考勤表'] wb1 = wb['成绩表'] print(wb1.max_row) # 4 读出列表行数 print(wb1.max_column) # 3 读出列表列数 # 读某一位置的数据 print(wb1['B2'].value) # pass # 读取第几行第几列数据 print(wb1.cell(row=2,column=2).value) # pass # 一次性读所有 for i in wb1.rows: print([j.value for j in i]) """ ['username', 'grade', 'age'] ['jason', 'pass', 20] ['kevin', 'Failed', 22] ['oscar', 'pass', 21] """ for j in wb1.columns: print([i.value for i in j]) """ ['username', 'jason', 'kevin', 'oscar'] ['grade', 'pass', 'Failed', 'pass'] ['age', 20, 22, 21] """
4.pandas模块本质
pandas模块,模块底层就是引用openpyxl模块。如果解释器缺失openpyxl模块,则pandas模块也不可用。import pandas d = { '姓名':['jason','kevin','oscaar','tony'], '性别':['male','female','male','male'], '年龄':[20,22,21,19], } df = pandas.DataFrame(d) df.to_excel(r'222.xlsx')
random随机数模块
1.random
返回0到1之间随机的小数import random print(random.random()) # 0.7601865770439645
2.randint
返回1到6之间随机的整数import random print(random.randint(1,6)) # 2
3.choice
随机抽取一个import random print(random.choice(['特等奖','一等奖','二等奖','优秀奖'])) # 二等奖
4.sample
随机抽样,自定义抽取个数import random (random.sample(['特等奖','一等奖','二等奖','优秀奖'],2)) # ['二等奖', '特等奖']
5.shuffle
随机打乱顺序import random l1 = [2, 3, 4, 5, 6, 7, 8, 9, 10, 'J', 'Q', 'K', 'A', '大王', '小王'] random.shuffle(l1) print(l1) # [10, 3, 'Q', 2, 'A', 'J', '小王', '大王', 8, 6, 4, 5, 7, 'K', 9]
hashlib加密模块
1.什么是加密?
将明文数据(看得懂)经过处理之后变成密文数据(看不懂)的过程。
2.为什么加密
不想让敏感的数据轻易的泄露。
3.如何判断当前数据值是否已经加密
一帮情况下如果是一串没有规则的数字与字母组合一般都是加密之后的结果。
4.如何加密(加密算法)
就是对明文数据采用的机密策略
不同的加密算法复杂度不一样 得出的结果长短也不一样
通常情况下加密之后的结果越长 说明采用的加密算法越复杂
5.常见加密算法
md5;sha系列;hmac;base64
6.代码实现
import hashlib md5 = hashlib.md5() # 选择md5加密算法作为数据的加密策略 md5.update(b'123') # 往里面添加明文数据,数据必须是bytes类型 res = md5.hexdigest() # 获取加密之后的结果 print(res) # 202cb962ac59075b964b07152d234b70
7.加密之后的结果一帮情况下不能反解密
所谓的反解密很多时候其实是偷换概念
提前假设别人的密码是什么 然后用各种算法算出对应的密文
之后构造对应关系 然后比对密文 最终映射明文
{‘密文1’:123,‘密文2’:321,…}
8.只要明文数据是一样的那么采用相同的算法得出的密文肯定一样
import hashlib md5 = hashlib.md5() # 选择md5加密算法作为数据的加密策略 md5.update(b'123') # 往里面添加明文数据,数据必须是bytes类型 md5.update(b'hello') # 往里面添加明文数据,数据必须是bytes类型 md5.update(b'word') # 往里面添加明文数据,数据必须是bytes类型 res = md5.hexdigest() # 获取加密之后的结果 print(res) # ecd179dcff348e21d19100060a5df96c md5.update(b'123helloword') res1 = md5.hexdigest() print(res1) # ecd179dcff348e21d19100060a5df96c
9.加盐处理(salt)
目的是为了增加复杂度import hashlib password = input('password>>>:').strip() md5 = hashlib.md5() # 选择md5加密算法作为数据的加密策略 md5.update('公司设置的盐(干扰项)'.encode('utf8')) # 加入干扰项(salt) md5.update(password.encode('utf8')) res = md5.hexdigest() print(res) # 123-------> 78bf5bd131c520b54168206d75f9f9be
10.动态加盐(salt)
目的依旧是增加安全性
干扰项每次都不一样
eg:每次获取当前时间 每个用户用户名截取一段
11.加密实际应用场景
(1)用户密码加密
注册存储密文,登录也是比对密文(2)文件安全性校验
正规的软件程序写完之后做一个内容的加密:
步骤一:网址提供软件文件记忆该文件内容对应的密文;
步骤二:用户下载完成后不直接运行,而是对下载的内容做加密;
步骤三:然后比对两次密文是否一致,如果一致表示文件没有被修改;
步骤四:不一致则表示改程序有可能被植入病毒(3)大文件加密优化
需求:有程序文件100G,要读取100G内容后加密。
解绝方法:不对100G所有文件进行加密处理,而是截取一部分进行加密处理!!!
代码展示:eg:每隔500M读取30bytes import os os.path.getsize()
subprocess模块
1.作用:模拟计算机cmd命令窗口
import subprocess cmd = input('请输入您的指令>>>:').strip() sub = subprocess.Popen(cmd, shell=True, stdout=subprocess.PIPE, stderr=subprocess.PIPE ) # stdout执行命令之后正确的返回结果 print(sub.stdout.read().decode('gbk')) # stderr执行命令报错之后的返回结果 print('*'*50) print(sub.stderr.read().decode('gbk')) print('*'*50)
日志模块
1.什么是日志
日志类似于是历史记录
2.为什么要使用日志
为了记录事物发生的事实(类似于古代的史官)
3.如何使用日志
(1):日志等级
debug等级——>info等级——>warning等级——>error等级——>critical等级# 日志等级 import logging logging.debug('debug等级') # 10 logging.info('info等级') # 20 logging.warning('warning等级') # 默认从warning级别开始记录日志 30 logging.error('error等级') # 40 logging.critical('critical等级') # 50
(2):基本使用import logging file_handler = logging.FileHandler(filename='x1.log', mode='a', encoding='utf-8',) logging.basicConfig( format='%(asctime)s - %(name)s - %(levelname)s -%(module)s: %(message)s', datefmt='%Y-%m-%d %H:%M:%S %p', handlers=[file_handler,], level=logging.ERROR ) logging.error('你好!!!')
4.日志模块详细阐述
我们在记录日志的时候,不需要像下面一样全部写,过于繁琐,所以该模块提供了固定的配置字典直接调用即可。# 日志详细阐述 import logging # 1.日志的产生(准备原材料) logger对象 logger = logging.getLogger('购物车记录') # 2.日志的过滤(剔除不良品) filter对象>>>:可以忽略 不用使用 # 3.日志的产出(成品) handler对象 hd1 = logging.FileHandler('a1.log', encoding='utf-8') # 输出到文件中 hd2 = logging.FileHandler('a2.log', encoding='utf-8') # 输出到文件中 hd3 = logging.StreamHandler() # 输出到终端 # 4.日志的格式(包装) format对象 fm1 = logging.Formatter( fmt='%(asctime)s - %(name)s - %(levelname)s -%(module)s: %(message)s', datefmt='%Y-%m-%d %H:%M:%S %p', ) fm2 = logging.Formatter( fmt='%(asctime)s - %(name)s: %(message)s', datefmt='%Y-%m-%d', ) # 5.给logger对象绑定handler对象 logger.addHandler(hd1) logger.addHandler(hd2) logger.addHandler(hd3) # 6.给handler绑定formmate对象 hd1.setFormatter(fm1) hd2.setFormatter(fm2) hd3.setFormatter(fm1) # 7.设置日志等级 logger.setLevel(10) # debug # 8.记录日志 logger.debug('写了半天 好累啊 好热啊')
5.日志字典配置(直接参考赋值即可)
# 日志配置字典 import logging import logging.config # 定义日志输出格式 开始 standard_format = '[%(asctime)s][%(threadName)s:%(thread)d][task_id:%(name)s][%(filename)s:%(lineno)d]' \ '[%(levelname)s][%(message)s]' #其中name为getlogger指定的名字 simple_format = '[%(levelname)s][%(asctime)s][%(filename)s:%(lineno)d]%>(message)s' # 自定义文件路径 logfile_path = 'a3.log' # log配置字典 LOGGING_DIC = { 'version': 1, 'disable_existing_loggers': False, 'formatters': { 'standard': { 'format': standard_format }, 'simple': { 'format': simple_format }, }, 'filters': { }, # 过滤日志 'handlers': { #打印到终端的日志 'console': { 'level': 'DEBUG', 'class': 'logging.StreamHandler', # 打印到屏幕 'formatter': 'simple' }, #打印到文件的日志,收集info及以上的日志 'default': { 'level': 'DEBUG', 'class': 'logging.handlers.RotatingFileHandler', # 保存到文件 'formatter': 'standard', 'filename': logfile_path, # 日志文件 'maxBytes': 1024*1024*5, # 日志大小 5M 'backupCount': 5, 'encoding': 'utf-8', # 日志文件的编码,再也不用担心中文log乱码了 }, }, 'loggers': { #logging.getLogger(__name__)拿到的logger配置 '': { 'handlers': ['default', 'console'], # 这里把上面定义的两个handler都加上,>即log数据既写入文件又打印到屏幕 'level': 'DEBUG', 'propagate': True, # 向上(更高level的logger)传递 }, # 当键不存在的情况下 (key设为空字符串)默认都会使用该k:v配置 # '购物车记录': { # 'handlers': ['default','console'], # 这里把上面定义的两个handler都加上,即log数据既写入文件又打印到屏幕 # 'level': 'WARNING', # 'propagate': True, # 向上(更高level的logger)传递 # }, # 当键不存在的情况下 (key设为空字符串)默认都会使用该k:v配置 }, } logging.config.dictConfig(LOGGING_DIC) # 自动加载字典中的配置 # logger1 = logging.getLogger('购物车记录') # logger1.warning('尊敬的VIP客户 晚上好 您又来啦') # logger1 = logging.getLogger('注册记录') # logger1.debug('jason注册成功') logger1 = logging.getLogger('登录记录') # 产生日志 logger1.debug('jason登陆成功')
6.实战练习
按照软件开发目录规范编写使用配置文件中变量名推荐全大写
(1)日志字典数据应该放在conf文件夹settings.py文件中, 它属于配置文件
(2)字典数据是日志模块固定的配置,写完一次之后几乎都不需要动,应该放在lib文件夹中的common.py文件中。
common.py文件代码展示:# 把日志封装成函数 import logging import logging.config from conf import settings def get_logger(msg): logging.config.dictConfig(settings.LOGGING_DIC) # 自动加载字典中的配置 logger1 = logging.getLogger(msg) # logger1.debug(f'{username}注册成功') # 这里让用户自己写更好 return logger1
项目开发流程
1.需求分析:
(1)明确项目的体功能(要明确到底要写什么东西,实现什么功能)
这个阶段的话具体要询问产品经理以及客户(客户对产品的具体需求)
(2)参与人员:
产品经理;开发经理;架构师
(3)技术人员主要职责:
引导客户提出一些比较合理,比较容易实现的需求。
2.架构设计:
(1)明确项目的核心技术点
项目使用的编程语言;项目使用的框架;项目所使用的数据库
(2)参与人员:
架构师
3.分组开发:
(1)明确每个组每个人具体到写该项目的哪些功能
(2)参与人员:
架构师;开发经理;普通程序员
4.提交测试:
(1)程序员自己本身写完自测以及交付测试小组测试
(2)参与人员:
普通的程序员;测试小组
5.交付上线:
(1)参与人员:
运维工程师
(2)可以直接把项目交给客户帮客户定期维护
边栏推荐
- redis秒杀案例,跟着b站尚硅谷老师学习
- Wechat applet generation Excel
- flask_ Reqparse parser inheritance in restful
- Is Jiufang intelligent investment a regular company? Talk about Jiufang intelligent investment
- DTS is equipped with a new self-developed kernel, which breaks through the key technology of the three center architecture of the two places Tencent cloud database
- How can you access the domestic server and overseas server quickly with one database?
- Machine learning [Matplotlib]
- Meta Quest内容生态总监谈App Lab设计初衷
- LPCI-252通用型PCI接口CAN卡的功能和应用介绍
- Insert pictures and videos in typera
猜你喜欢


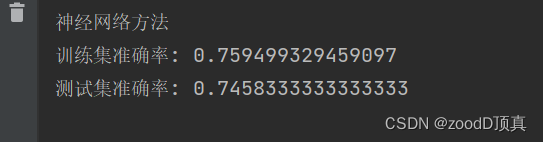
![Machine learning [Matplotlib]](/img/d1/31ec2f96ca96465c6863798c7db179.jpg)





随机推荐
Binary tree (day 82)
Briefly sort out the dualpivotquicksort
Introduction to database - a brief introduction to MySQL
Installation and use of anti-virus software ClamAV
[tree chain dissection] template question
Use websocket to realize a web version of chat room (fishing is more hidden)
Ring counting (Northern Polytechnic machine test questions) (day 83)
Cocos game practice-05-npc and character attack logic
Volatile keyword and its function
Realization of regular hexagon map with two-dimensional array of unity
Characteristics and experimental suggestions of abbkine abfluor 488 cell apoptosis detection kit
在typora中插入图片和视频
架构基本概念和架构本质
MySQL的数据库有关操作
Machine learning [Matplotlib]
A new paradigm of distributed deep learning programming: Global tensor
百融榕树数据分析拆解方法
477-82(236、61、47、74、240、93)
Director of meta quest content ecology talks about the original intention of APP lab design
Reading notes of Kazuo Inamori's advice to young people