当前位置:网站首页>Realizing deep learning framework from zero -- LSTM from theory to practice [theory]
Realizing deep learning framework from zero -- LSTM from theory to practice [theory]
2022-06-29 22:23:00 【Angry coke】
introduction
In line with “ Everything I can't create , I can't understand ” Thought , This series The article will be based on pure Python as well as NumPy Create your own deep learning framework from zero , The framework is similar PyTorch It can realize automatic derivation .
Deep understanding and deep learning , The experience of creating from scratch is very important , From an understandable point of view , Try not to use an external complete framework , Implement the model we want . This series The purpose of this article is through such a process , Let us grasp the underlying realization of deep learning , Instead of just being a switchman .
What we introduced earlier is simple RNN There are some problems , That is, it is difficult to keep the information away from the current position and the gradient disappears .
LSTM
LSTM Designed to solve the above problems . By making the network learn to forget unwanted information , And remember the information you need to make decisions in the future , To explicitly manage contextual information .
LSTM The context management problem is divided into two sub problems : Remove information that is no longer needed from the context , And adding information that is more likely to be needed for future decisions .
framework
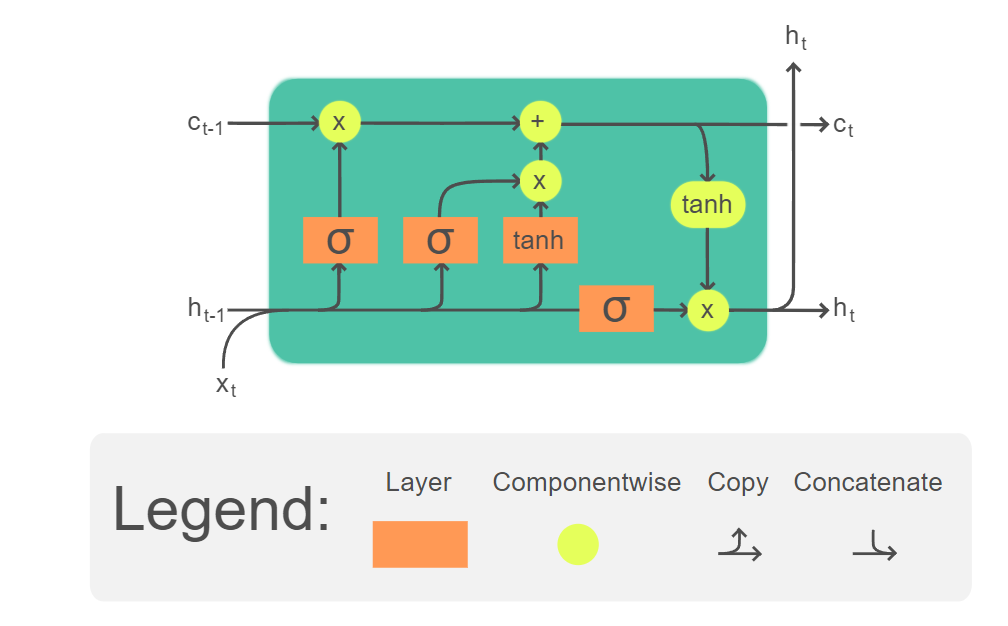
The key to solving these two problems is to learn how to manage this context , Instead of hard coding policies into the architecture .LSTM First Add a display context layer to the network ( Except for the common RNN Hidden layer ), And by using specialized neurons , Gates are used to control the flow of information into and out of the units that make up the network layer . These gates are used through the input 、 Additional weight operations are added to the previous hidden state and the previous context state respectively .
LSTM These doors in share the same design pattern : Each contains a feedforward network , Next is sigmoid Activation function , Finally, there is an element level multiplication with the gated layer .
choice sigmoid As an activation function, its output is based on 0 To 1 Between . The effect combined with element level multiplication is similar to binary mask (binary mask). Close to the mask 1 The values in the gate layer corresponding to the values of are almost the same ; The value corresponding to the lower value is basically erased .
Oblivion gate
The first door we introduced is the forgetting door (forget gate). The purpose of this gate is to delete information that is no longer needed by the context . The forgetting gate calculates the weighted sum of the previous hidden state and the current input , And pass sigmoid convert . obtain mask, The mask Then it is multiplied by the context vector element level to remove the context information that is no longer needed .
f t = σ ( U f h t − 1 + W f x t ) (1) f_t = \sigma(U_f h_{t-1} + W_fx_t) \tag 1 ft=σ(Ufht−1+Wfxt)(1)
among U f U_f Uf and W f W_f Wf Is two weight matrices ; h t − 1 h_{t-1} ht−1 For the previous hidden state ; x t x_t xt Enter... For the current ; σ \sigma σ by sigmoid function , Here we ignore the bias term .
k t = c t − 1 ⊙ f t (2) k_t = c_{t-1} \odot f_t \tag 2 kt=ct−1⊙ft(2)
among c t − 1 c_{t-1} ct−1 Represents the previous context layer vector ; Element level multiplication of two vectors ( By operator ⊙ \odot ⊙ Express , Sometimes called Hadamard product ) Is the multiplication of the corresponding elements of two vectors .
The forgetting gate controls the context vector in memory c t − 1 c_{t-1} ct−1 Whether to be forgotten .
Input gate
Similarly , The input gate also passes through the previous hidden state h t − 1 h_{t-1} ht−1 And current input x t x_t xt Calculation :
i t = σ ( U i h t − 1 + W i x t ) (3) i_t = \sigma(U_ih_{t-1} + W_ix_t) \tag 3 it=σ(Uiht−1+Wixt)(3)
Then we calculate the previous hidden state h t − 1 h_{t-1} ht−1 And current input x t x_t xt Extract actual information from —— all RNN The basic operations used by the network :
g t = tanh ( U g h t − 1 + W g x t ) (4) g_t = \tanh(U_gh_{t-1} + W_gx_t) \tag 4 gt=tanh(Ught−1+Wgxt)(4)
In a simple RNN in , The result of the above calculation is the hidden state of the current time , But in LSTM Middle is not .LSTM The hidden state in is based on the context state c t c_t ct Calculated .
j t = g t ⊙ i t (5) j_t = g_t \odot i_t \tag 5 jt=gt⊙it(5)
Multiply the input gate to control g t g_t gt( Also known as candidate values ) How much can be stored in the current context state c t c_t ct.
We put what we got above j t j_t jt and k t k_t kt Add it up to get the current context state c t c_t ct:
c t = j t + k t (6) c_t = j_t + k_t \tag 6 ct=jt+kt(6)
Output gate
The last gate is the output gate , It is used to control which information of the current hidden state is needed .
o t = σ ( U o h t − 1 + W o x t ) (7) o_t = \sigma(U_o h_{t-1} +W_o x_t) \tag 7 ot=σ(Uoht−1+Woxt)(7)
h t = o t ⊙ tanh ( c t ) (8) h_t = o_t \odot \tanh(c_t) \tag 8 ht=ot⊙tanh(ct)(8)

Given the weights of different gates ,LSTM Accept the context layer and hidden layer of the previous time and the current input vector as input . then , It generates updated context vectors and hidden vectors as output . Hidden layer h t h_t ht Can be used as a stack RNN Input of subsequent layers in , Or generate output for the last layer of the network .
For example, based on the current hidden state , You can calculate the output at the current time y ^ t \hat y_t y^t:
y ^ t = softmax ( W y h t + b y ) (9) \hat y_t = \text{softmax}(W_y h_t + b_y) \tag{9} y^t=softmax(Wyht+by)(9)
All in all ,LSTM Calculation c t c_t ct and h t h_t ht. c t c_t ct Long term memory , h t h_t ht Short term memory . Use input x t x_t xt and h t − 1 h_{t-1} ht−1 Renew long-term memory , In update , some c t c_t ct The characteristics of the forgotten gate f t f_t ft eliminate , Some other features have been added from the input gate to c t c_t ct in .
The new short-term memory is the long-term memory process tanh \tanh tanh Multiplied by the output gate . Be careful , On update ,LSTM Not looking at long-term memory c t c_t ct. Only modify it . c t c_t ct And never go through a linear transformation . This is why the gradient vanishes and explodes .
References
- Speech and Language Processing
边栏推荐
猜你喜欢









随机推荐
The MySQL data cannot be read after the checkpoint recovery. Do you know the reason
The correct method for Navicat to connect to mysql8.0 (valid for personal testing)
Low code, end-to-end, one hour to build IOT sample scenarios, and the sound network released lingfalcon Internet of things cloud platform
MySQL lock common knowledge points & summary of interview questions
Go learning (IV. interface oriented)
架构实战营毕业总结
直播平台开发,进入可视区域执行动画、动效、添加样式类名
Unicom warehousing | all Unicom companies that need to sell their products need to enter the general warehouse first
Can cdc2.2.1 listen to multiple PgSQL libraries at the same time?
Deep learning remote sensing data set
qt5.14.2连接ubuntu20.04的mysql数据库出错
If I am in Zhuhai, where can I open an account? Is it safe to open an account online?
客户端可以连接远程mysql
22 years of a doctor in Huawei
软件快速交付真的需要以安全为代价吗?
这次跟大家聊聊技术,也聊聊人生
This time, I will talk about technology and life
【Proteus仿真】步进电机转速数码管显示
这个flink cdc可以用在做oracle到mysql的,增量同步吗
交友平台小程序制作开发代码分享