当前位置:网站首页>MySQL indexes and transactions
MySQL indexes and transactions
2022-07-04 04:36:00 【Lockey-s】
Blog home page :Lockey-s Welcome to thumb up Collection Leaving a message. Welcome to discuss !
This paper is written by 【Lockey-s】 original ! First appeared in CSDN
Because the blogger is learning Xiaobai one , There are bound to be mistakes , If you have any questions, please leave a message in the comment area to point out , Thank you no all ! Boutique column ( Update from time to time )
Indexes and transactions
Indexes
Concept
Index is a special kind of file , Contains reference pointers to all data in the data table , You can create indexes on one or more columns in the created table .
effect
- The main function of index is to search , Improve search efficiency . Search efficiency is improved , But it will also pay a price .
- Index of database , It also needs to consume some additional storage space , More data , The more extra space is consumed .
- After the index is determined , Every time the content is added, deleted or modified , It is often necessary to adjust the index structure synchronously .
Benefits of indexing : Improved search speed .
The disadvantages of indexing : Take up too much space , Slow down the speed of addition, deletion and modification .
Operation of index
Take this student form as an example , We didn't create an index on this table :
Look at the index
adopt show index from Table name ; You can see the index , The code and running results are as follows :
show index from student;

You can see that we did not create an index , But there is also the index . The built-in index is the primary key constraint :primary key It brings , With the primary key ,MySQL The index will be created automatically .
Not only does the primary key have its own index ,unique It also has its own index
Create index
Is to create an index for a table , adopt :create index Index name on Table name ( Name ); To create an index . The code is as follows :
create index name_index on student(name);
The operation results are as follows :
Here we can see the newly created index , However, it should be noted that index creation is a very inefficient thing , Especially when there are a lot of data in the table , For the database on the server , If the table inside has no index , Don't create indexes easily . Otherwise, the database may crash .
Delete index
When deleting an index , adopt :**drop index Index name on Table name ; ** To delete an index . But here's the thing , When deleting an index , If it is a database with a large amount of data , It may also cause the database to crash , So in creating 、 When deleting an index , It should be adjusted at the beginning of the database . The code and results are as follows :
drop index name_index on student;
The operation results are as follows :
You can see that the index we created before has now been deleted .
Data structure behind index
Indexing can greatly speed up the search , So the data structure behind the index is to speed up the search . That is to use multi fork search tree , Because then the height of the tree will drop , The search speed is faster . The data structure in the database uses B+ Trees ( The most common data structure , Is in the B Trees Has been improved on the basis of ), It is also written in the index :
B+ Trees , Each node contains multiple key value , Each node has N individual key, It is divided into N Intervals , The value of the parent node will be reflected in the child node . Each value of a non leaf node , Finally, it will be reflected in the leaf node , The value in the parent node , As the maximum value in the child node ( minimum value ), This graph is the maximum case , The lowest leaf node , Use the linked list to connect in order :
- Because use B+ Trees When searching , Holistic IO The number of times will also be relatively small
- All queries will eventually fall on the leaf node , So every time I look up IO The times are the same , And the speed is stable .
- The following leaf nodes are connected with a linked list , Range finding is fast
- All data storage ( load ), They are all placed on leaf nodes , Only... Are saved in non leaf nodes key value , Therefore, non leaf orders occupy less space as a whole , It can even be cached in memory .
Business
effect
The function of a transaction is to wrap several independent operations into a whole , Make it impossible to work separately . This is called Atomicity . Namely , Or not , Or do it all .
give an example
A to B Transfer accounts 500 element , As shown in the figure below :
If in execution SQL When , Finish the first SQL, Execute the second SQL When , The database crashed 、 Power is off 、 The program is broken , Then you can't implement the second SQL 了 . Transactions are generated in response to this situation , If this happens , The database automatically performs some restorative operations , To eliminate the first SQL The impact of statements .
Use of transactions
- adopt start transaction; To open a transaction .
- Execute more than one SQL sentence
- Roll back or commit :rollback/commit;rollback It's all failure ( That is, roll back ),commit It's all success .
The basic characteristics of affairs
- Atomicity .
- Uniformity , Before the transaction is executed , And after execution , The data in the database must be reasonable and legal . Just like after the transfer , Account balance cannot be negative .
- persistence , Once the transaction is committed , It is persistent and stored .
- Isolation, : When transactions are executed concurrently , What happened .
Dirty reading the first case ( You can't read while writing )
Dirty reading is a transaction A While modifying a plastic , Business B To read this data , That is, what I read is a temporary result , Not the end result . It's like now “ Many people fill in the form ” Probably A After filling in ,B Go ahead and revise A The data of ,A What you fill in may be just a temporary data . Temporary data is Dirty data .
The reason for dirty reading is : Between transactions , Without any isolation , Add some constraints , You can effectively avoid dirty reading problems
Deal with dirty reading
Lock the write operation , In the process of modification , Others can't read ( Locked state ), After modification , Others can read ( Contact locking ). Once the write lock is added , It means that the isolation between transactions is high , Concurrency is reduced .
The second case of dirty reading ( It can't be read repeatedly )
It's like we're in GitHub Submit the code above , And then other people go through GitHub To read the code , Like the picture below :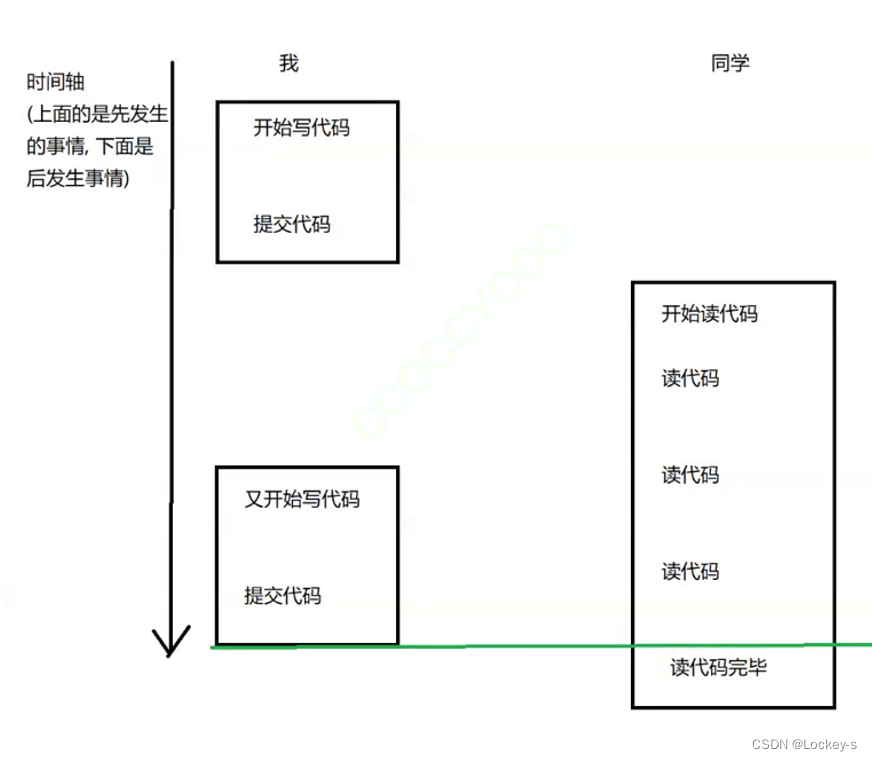
The first four read operations before submitting the second code , All I read is old code , Then the last time I read the code, I read the new code submitted for the second time :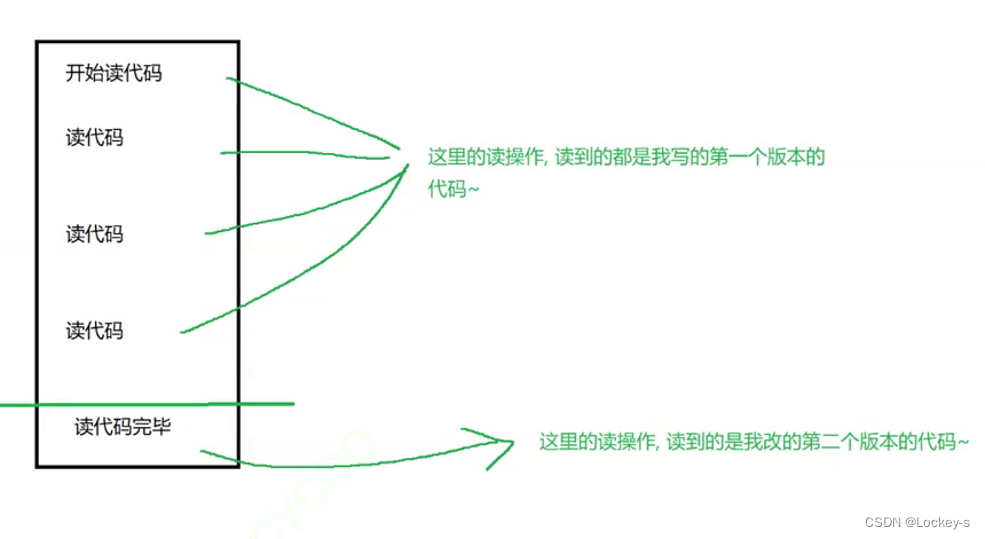
To avoid this , When reading operations , You can't perform write operations . By locking when reading , It solves the problem of non repeatable reading . In this case , It will make transactions more isolated , But the concurrency is also lower .
The problem of unreal reading
Like the second case of dirty reading , If after locking , The rest of the time can also be used for other . For example, modify another table , It can greatly improve the utilization of resources , As shown in the figure below :
After doing this , The strength of the lock will not be too great . It's like epidemic containment , If one person is diagnosed , Just one building , If the diagnosis is too much , Just close a community .
But when reading like this , Found that the number has changed , There was only one code file , Then there was another . That is, a transaction is queried many times during execution , The results of multiple queries are different ( More or less ), This is also a special non repeatable , Completely solve this problem , Namely Serial execution , It is during the reading operation , You can't write . Highest isolation , Minimum concurrency , The most reliable data , The slowest .
MySQL Isolation level of transactions in
The isolation level of the database can be adjusted according to the actual requirements , Through different isolation levels , It also controls the isolation between things , This controls the degree of concurrency .
- read uncommitted Allow reading uncommitted data , The highest degree of concurrency , Minimum isolation . Will introduce Dirty reading + It can't be read repeatedly + The problem of unreal reading .
- read committed Only data after submission is allowed to be read , Equivalent to writing and locking , Reduce the degree of concurrency , The degree of isolation is higher , Solved dirty reading , Will introduce It can't be read repeatedly + Fantasy reading .
- repeatable read It is equivalent to giving Read and write Lock them all , The degree of concurrency is reduced , Isolation has increased again , Solve the problem of dirty reading and non repeatable reading , Will introduce unreal reading .
- serializable Serialization , The lowest degree of concurrency , The highest degree of isolation , Solved dirty reading , It can't be read repeatedly , Cold poison problem , But the slowest execution .
It can be modified by my.ini This configuration file , To set the current isolation level , According to the actual demand scenario , To determine which isolation level to use .
边栏推荐
- Virtual commodity account trading platform source code_ Support personal QR code collection
- 陪驾注意事项 这23点要注意!
- 普源DS1000Z系列数字示波器在通信原理实验中的应用方案
- 1. Mx6u-alpha development board (LED drive experiment in C language version)
- NFT new opportunity, multimedia NFT aggregation platform okaleido will be launched soon
- Emlog用户注册插件 价值80元
- Leetcode skimming: binary tree 08 (maximum depth of n-ary tree)
- MIN_ RTO dialog
- 深入解析结构化异常处理(SEH) - by Matt Pietrek
- Keysight n9320b RF spectrum analyzer solves tire pressure monitoring scheme
猜你喜欢

博朗与Virgil Abloh于2021年为纪念博朗品牌100周年而联合打造的“功能性艺术”将在博物馆展出Abloh作品期间首次亮相

NFT新的契机,多媒体NFT聚合平台OKALEIDO即将上线

UnicodeDecodeError: ‘gbk‘ codec can‘t decode byte 0x98 in position 1093: illegal multibyte sequence

统计遗传学:第三章,群体遗传

R语言dplyr中的Select函数变量列名
A beautiful API document generation tool

Boutique website navigation theme whole station source code WordPress template adaptive mobile terminal
NFT new opportunity, multimedia NFT aggregation platform okaleido will be launched soon

Graduation project
Statistical genetics: Chapter 3, population genetics
随机推荐
leetcode:1314. 矩阵区域和【二维前缀和模板】
[wechat applet] good looking carousel map component
RPC Technology
A beautiful API document generation tool
The interactive solution of JS and app in the H5 page embedded in app (parameters can be transferred and callbacks can be made)
沃博联结束战略评估,决定保留表现优异的博姿业务
Leetcode brush question: binary tree 06 (symmetric binary tree)
更优雅地远程操作服务器:Paramiko库的实践
Unity Resource path
Select function variable column name in dplyr of R language
MySQL JDBC编程
微信脑力比拼答题小程序_支持流量主带最新题库文件
分布式CAP理论
Rhcsa 04 - process management
"Don't care too much about salary when looking for a job", this is the biggest lie I've ever heard
Distributed cap theory
UnicodeDecodeError: ‘gbk‘ codec can‘t decode byte 0x98 in position 1093: illegal multibyte sequence
Formatted text of Kivy tutorial (tutorial includes source code)
Eig launched Grupo Cerro, a renewable energy platform in Chile
Why use node