当前位置:网站首页>MapReduce之Reduce阶段的join操作案例
MapReduce之Reduce阶段的join操作案例
2022-06-10 15:29:00 【QYHuiiQ】
这里要实现的案例是学生基本信息的表与成绩表的join操作。与之前案例不同的是,前面的案例都是单个文件作为map端的数据输入,而在此案例中我们要将学生基本信息表和成绩表两个数据文件作为map端的数据输入。

- 准备数据

上传至HDFS:
[[email protected] test_data]# hdfs dfs -mkdir /test_reduce_join_input
[[email protected] test_data]# hdfs dfs -put reduce* /test_reduce_join_input
 新建project:
新建project:
- 引入pom依赖
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>wyh.test</groupId>
<artifactId>mapreduce_reduce_join</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
</properties>
<packaging>jar</packaging>
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.7.5</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.7.5</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.7.5</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>2.7.5</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>RELEASE</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.1</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
<encoding>UTF-8</encoding>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>2.4.3</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<minimizeJar>true</minimizeJar>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>- 自定义Mapper
package wyh.test.reduce.join;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileSplit;
import java.io.IOException;
/**
* 学生基本信息表:
* s002,Tom,boy,11
* 成绩表:
* c002,s002,96
* 该案例中存在多个数据输入文件,无论是哪个数据文件,K1都是行偏移量(LongWritable),V1都是行文本数据(Text),
* 要想使两个数据文件产生关联,那么K2应该是两个表中的学生id,V2是各自原始的行文本数据
*/
public class ReduceJoinMapper extends Mapper<LongWritable, Text, Text, Text> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
/**
* 由于该案例中存在多个文件作为数据输入,所以我们在对数据处理时要先判断文件
* InputSplit是一个接口,我们使用其实现类FileSplit得到输入文件的相关信息
*/
//获取数据文件的文件对象
FileSplit fileSplit = (FileSplit) context.getInputSplit();
//获取输入文件的文件名
String inputFileName = fileSplit.getPath().getName();
//根据不同的文件名分别做不同的K2,V2处理
if(inputFileName.equals("reduce_join_student_info.txt")){
//数据来自学生基本信息表
String[] splitInfo = value.toString().split(",");
String studentId = splitInfo[0];
context.write(new Text(studentId), value);
}else{
//数据来自成绩表
String[] splitGrade = value.toString().split(",");
String studentId = splitGrade[1];
context.write(new Text(studentId), value);
}
}
}
- 自定义Reducer
package wyh.test.reduce.join;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
/**
* K2为studentId
* V2为两种源数据文件的行文本数据
* K3为studentId
* V3为相同K2对应的V2值的拼接
*/
public class ReduceJoinReducer extends Reducer<Text, Text, Text, Text> {
@Override
protected void reduce(Text key, Iterable<Text> values, Reducer<Text, Text, Text, Text>.Context context) throws IOException, InterruptedException {
/**
* 经过map阶段之后,会将相同K2的数据放在同一个集合里,所以这里需要我们遍历集合,拿到相同Key的所有值,并将其拼接为V3.
* 但是数据源为两种数据文件,并且想要将学生基本信息放在v3拼接内容的前半部分,成绩放在后半部分,
* 所以我们在遍历V2的集合时,要先判断这条数据是来自于哪个文件,然后才能做处理,
* 由于两种文件中的数据一个是以学生编号(s)开头的,一个是以成绩编号(c)开头的,所以这里我们以V2的开头字母来区分是学生基本信息还是成绩
*/
String studentInfo = "";
String studentGrade = "";
for (Text student : values) {
if(student.toString().startsWith("s")){
//该数据为学生基本信息
studentInfo = student.toString();
}else{
//该数据为成绩
studentGrade = student.toString();
}
}
String result = studentInfo+" # "+studentGrade;
context.write(key, new Text(result));
}
}
- 自定义主类
package wyh.test.reduce.join;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
public class ReduceJoinJobMain extends Configured implements Tool {
@Override
public int run(String[] strings) throws Exception {
Job job = Job.getInstance(super.getConf(), "test_reduce_join");
job.setJarByClass(ReduceJoinJobMain.class);
job.setInputFormatClass(TextInputFormat.class);
TextInputFormat.addInputPath(job, new Path("hdfs://192.168.126.132:8020/test_reduce_join_input"));
job.setMapperClass(ReduceJoinMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
job.setReducerClass(ReduceJoinReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
job.setOutputFormatClass(TextOutputFormat.class);
TextOutputFormat.setOutputPath(job, new Path("hdfs://192.168.126.132:8020/test_reduce_join_output"));
boolean b = job.waitForCompletion(true);
return b?0:1;
}
public static void main(String[] args) throws Exception {
Configuration configuration = new Configuration();
int runStatus = ToolRunner.run(configuration, new ReduceJoinJobMain(), args);
System.exit(runStatus);
}
}
- 打包

- 将jar包上传至服务器并运行

[[email protected] test_jar]# hadoop jar mapreduce_reduce_join-1.0-SNAPSHOT.jar wyh.test.reduce.join.ReduceJoinJobMain
- 查看输出结果

[[email protected] test_jar]# hdfs dfs -cat /test_reduce_join_output/part-r-00000
s002 s002,Tom,boy,11 # c002,s002,96
s003 s003,Alice,girl,12 # c001,s003,84
这样就简单地实现了MapReduce中reduce端join多文件的功能。
边栏推荐
- Quelqu'un a même dit que ArrayList était deux fois plus grand. Aujourd'hui, je vais vous montrer le code source ArrayList.
- Kubernetes 1.24:statefulset introduces maxunavailable copies
- One-way hash function
- 2290. Minimum Obstacle Removal to Reach Corner
- 姿态估计之2D人体姿态估计 - Numerical Coordinate Regression with Convolutional Neural Networks(DSNT)
- ORB_ Slam2 visual inertial tight coupling positioning technology route and code explanation 3 - tight coupling optimization model
- 这几个垂直类小众导航网站,你绝对不会想错过
- [reward publicity] [content co creation] issue 16 may Xu sublimation, create a good time! You can also win a gift package of up to 500 yuan if you sign a contract with Huawei cloud Xiaobian!
- 排序与分页
- 凸函数的Hessian矩阵与高斯牛顿下降法增量矩阵半正定性的理解
猜你喜欢

Software intelligence: formal rules of AAAS system metrics and grammars

这几个垂直类小众导航网站,你绝对不会想错过
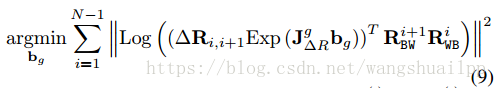
ORB_ Slam2 visual inertial tight coupling positioning technology route and code explanation 2 - IMU initialization

广和通高算力智能模组为万亿级市场5G C-V2X注智

Information theory and coding 2 final review BCH code

ORB_ Slam2 visual inertial tight coupling positioning technology route and code explanation 1 - IMU flow pattern pre integration

顺应医改,积极布局——集采背景下的高值医用耗材发展洞察2022

Digital management medium + low code, jnpf opens a new engine for enterprise digital transformation

Fast detection of short text repetition rate

Hutool Usage Summary (VIP collection version)
随机推荐
点投影到平面上的方法总结
苹果式中文:似乎表达清楚意思了,懂了没完全懂的苹果式宣传文案
Hessian matrix of convex function and Gauss Newton descent method
初学pytorch踩坑
竟然还有人说ArrayList是2倍扩容,今天带你手撕ArrayList源码
Unified certification center oauth2 certification pit
One-way hash function
Mitm (man in the middle attack)
Méthodes couramment utilisées dans uniapp - TIMESTAMP et Rich Text Analysis picture
How the autorunner automated test tool creates a project -alltesting | Zezhong cloud test
22. Generate Parentheses
Solution to some problems of shadow knife RPA learning and meeting Excel
Fast detection of short text repetition rate
The product design software figma cannot be used. What software with similar functions is available in China
Vins theory and code explanation 4 - initialization
Sword finger offer 06 Print linked list from end to end
The power of insight
We media video Hot Ideas sharing
Beginner pytorch step pit
TensorFlow实战Google深度学习框架第二版学习总结-TensorFlow入门