当前位置:网站首页>Summary of target tracking related knowledge
Summary of target tracking related knowledge
2022-07-26 14:40:00 【The way of code】
feather map
stay cnn Every convolution layer of , All data exist in three-dimensional form . It can be seen as many two-dimensional pictures stacked together , Each of them is called a feature map.
1. In the input layer , If it is a grayscale picture , Then there is only one feature map; If it's a color picture , It is commonly 3 individual feature map( Red, green and blue ).
2. On other layers , There are several convolution kernels between layers (kernel), Each on the upper floor feature map Convolute with each convolution kernel , Will produce a next layer feature map, Yes N Convolution kernels , The lower layer will produce N individual feather map.
Convolution kernel (filter)
Each convolution kernel has three dimensions of length, width and depth ; The depth of convolution kernel is the same as that of the current image (feather map Number of sheets ) identical . The number of convolution kernels and the number of convolution kernels required for the next layer feather map identical . stay CNN In a convolution layer of : The length of convolution kernel 、 The width is artificially specified , Long X The width is also known as the size of the convolution kernel , The commonly used size is 3X3,5X5 etc. ; for example , In the original image layer ( Input layer ), If the image is a grayscale image , Its feather map The number of 1, Then the depth of the convolution kernel is 1; If the image is grb Images , Its feather map The number of 3, Then the depth of the convolution kernel is 3.
Training data
batchsize: Batch size . In deep learning , It is generally used SGD Training , That is to say, each training session takes batchsize Sample training ; iteration:1 individual iteration Equal to using batchsize One sample training ; epoch:1 individual epoch It is equal to training once with all the samples in the training set , Generally speaking epoch The value of is how many times the entire dataset is rotated .
for example 300 One sample training ,epoch=1,batchsize = 10 ,iteration=30.
BN(Batch Normalization) layer
BN Layer is batch-norm layer , It is generally used to accelerate the training speed and a method in deep learning , It is usually placed in the convolution layer (conv layer ) Or after the full connection layer , The data are normalized and the training fitting speed is accelerated .
Common location :conv→bn→relu
If the network uses sigmod Activation function , When the error passes forward , after sigmod unit , Need to take sigmod Gradient of , and sigmod The maximum gradient of is 0.25, So the more forward it goes , The smaller the error , This is gradient dissipation , But what is a gradient explosion ? Note the error when passing through the full connection or convolution layer , Also multiply by the weight w, If w They're all bigger , greater than sigmod The resulting reduction , In this way, the error will become larger and larger as we move forward , Produce a gradient explosion .
BN The calculation diagram of the layer is shown below ,x It's input data , To xhat The mean variance is normalized , Back xhat To y In fact, it is an ordinary linear transformation , Similar to full connection but no crossover . without BN layer ,x Enter the following network directly , During training x The transformation of the distribution will inevitably lead to the later network to adjust to the learning x The mean and variance of , Into BN layer ,xhat Is a normalized data , The cost is an additional linear layer in the network y, But the former brings more performance , So it accelerates .

AUC(Area Under Curve)
A good example , A negative example , The probability that the prediction is positive is more likely than the probability that the prediction is negative . So by definition : We have two most intuitive calculations AUC Methods :
1: draw ROC curve ,ROC The area under the curve is AUC Value
2: Suppose there are (m+n) Samples , Among them, positive samples m individual , Negative sample n individual , All in all mn A sample is right , Count , The probability value of positive sample predicted as positive sample is greater than that of negative sample predicted as positive sample, which is recorded as 1, Add up the count , Then divide by (mn) Namely AUC Value .
AUC As a numerical value, we can evaluate the classifier directly , The higher the value, the better .
Mean average accuracy MAP(Mean Average Precision)
We use loU And threshold to determine whether it is the target . Calculate the... Of each detection frame obtained from the model loU value , Use the calculated loU Value and setting loU Threshold comparison , The correct detection times of each class in each image can be calculated (A). For each image , We all have ground truth The data of , Therefore, the actual target of a given category in the image is also known (B) The number of . We also calculated the number of correct predictions (A)(True possitive). So we can use this formula to calculate the accuracy of this kind of model (A/B)
That is, given the category of an image C Of Precision= The number of correctly predicted images is divided by the total number of targets in the category of images . Suppose you now have a given class , The validation set has 100 Images , And we know that every image has all of its classes ( be based on ground truth). So we can get 100 A precision value , Calculate this 100 Average of precision values , The result is the average precision of this class .
That is, a C Average precision of class = All images on the validation set are for the class C The sum of the precision values of / Some kind C The number of all images for this target . Now add to our entire collection 20 Classes , For each category , We all calculate first loU, Next, calculate the accuracy , Then calculate the average accuracy . All we have now 20 Different average precision values . Use these average precision values , We can easily judge the performance of any given category of models .
But the problem is using 20 Different average accuracies make it difficult to measure the whole model , So we can choose a single number to represent the performance of a model ( A metric to unify them ), We can take the average of the average precision values of all classes , namely MAP( Mean average accuracy ).
MAP= The average precision sum of all categories is divided by all categories . That is, the average of the average precision of all classes in the dataset .
EAO Expected average coverage
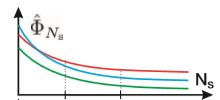
EAO The purpose of this paper is to hope that a good tracker can have good accuracy at the same time A And robustness R, If you use it directly A and R The weighted sum of two numbers is unfair , So we need to redefine .
Suppose there is A video with a frame length , So one with The coverage accuracy of the tracker in this video (Overlay accuracy)op For each frame op The average of ,op Namely bonding box And ground truth Cross and compare Φ Express , namely :
So an ideal EAO Is to put from 1 To an expected maximum Find an average , Is the expected average coverage , Just like its name , Equivalent to the area under the curve in the figure below :
shortcut connection
ResNet The structure uses a connection method , namely “ Detour ” It means .

Bottleneck( The bottleneck layer )
This means that the input and output dimensions differ greatly , Like a bottleneck , Narrow at the top and wide at the bottom, or wide at the top and narrow at the bottom .1x1 filters Can play a role in changing the output dimension (channels) The role of . You can see , On the right 1x1 filters Put dimension (channels) It's going up , The difference between input and output dimensions is large .

Feel the field :
In convolutional neural networks CNN in , Determine the area size of the input layer corresponding to an element in the output result of a certain layer , It's called the receptive field receptive field. Using mathematical language is to feel the wild is CNN An element of the output result of a layer in corresponds to a mapping of the input layer .
Learn more about programming , Please pay attention to my official account :

边栏推荐
- Tdengine helps Siemens' lightweight digital solution simicas simplify data processing process
- GOM登录器配置免费版生成图文教程
- 《MySQL高级篇》五、InnoDB数据存储结构
- VBA 上传图片
- Sqldeveloper tools quick start
- winscp传输文件和VNC连接问题
- 堆叠降噪自动编码器 Stacked Denoising Auto Encoder(SDAE)
- 【方差分析】之matlab求解
- Transc knowledge representation model
- [draw with toolbar]
猜你喜欢
![[ostep] 04 virtualized CPU - process scheduling strategy](/img/42/7ffb9745ef21a8db35861119dd70bf.png)
[ostep] 04 virtualized CPU - process scheduling strategy

Maya imports the model into unity

Prediction and value evaluation of technology fusion relationship based on multiple features

Arithmetic operation and logic operation of image in opencv

Win11 running virtual machine crashed? Solution to crash of VMware virtual machine running in win11

Multi task text classification model based on tag embedded attention mechanism
When AI encounters life and health, Huawei cloud builds three bridges for them

【文件上传漏洞-06】分布式配置文件攻击实验—以upload-labs-4为例

C nanui related function integration

C# 常用功能整合
随机推荐
『云原生』KubeSphere可插拔组件之DevOps系统
c# 用移位 >> 和运算与 &判断两个 二进制数 是否发生过改变
Prediction and value evaluation of technology fusion relationship based on multiple features
VP video structured framework
As the "first city" in Central China, Changsha's "talent attraction" has changed from competition to leadership
What is restful style and its four specific implementation forms
Arithmetic operation and logic operation of image in opencv
Jzoffer51- reverse pairs in the array (merge sort solution)
OpenCV中图像算术操作与逻辑操作
请问数据库规范的文档吗 参考一下?
[GYCTF2020]FlaskApp
First knowledge of opencv4.x --- image perspective transformation
Some lightweight network models in detection and segmentation (share your own learning notes)
Mysql5.7 is installed through file zip - Ninth Five Year Plan xiaopang
【方差分析】之matlab求解
【1.2.投资的收益和风险】
Wechat applet - "do you really understand the use of applet components?
Classic line style login interface
UDP多线程在线聊天
嵌入式开发:调试嵌入式软件的技巧